It is no secret that we built Titan Takeoff to make it easy for you to make inferences and deploy your models. With the nitty-gritty details of deployment and technical complications of running massive models abstracted away, you can stop worrying about performance issues and instead focus on what really matters - how to select the best model for your use case and get your desired model to product quality outputs.
We recognize that the model selection and prompt engineering process are essential as this can influence the user experience and satisfaction with your applications. We also realize that this process is complex, usually requiring many rounds of repeated experimentation.
Simplified Model Selection and Prompt Engineering with LLM Arena
In order to help you with this challenging process, we have built the LLM Arena. This interactive web application lets you quickly compare the outputs across different models and prompts. We’ve abstracted away all the technical complexities of deploying other models, so you can use our simple interface to compare different models and prompts, speeding up experimentation and development of your AI-powered application.
In the previous blog post, we talked about the Tournament Mode, where users can host a knockout-style tournament for Large Language Models, allowing them to judge and compare outputs between various models and find the ultimate winning model that produces the best output.
While this may be a helpful way of testing out a more comprehensive selection of models, we recognize that this may only be appropriate for some model comparison workflows. Therefore, we have included a Comparison mode in the LLM Arena that allows users to simply compare two models in-depth, side-by-side, without going through the process of playing a whole tournament and spinning up and down different models.
Model Selection: You can pick two model outputs to compare side-by-side, making evaluating the outputs of the models more convenient and straightforward.
Simultaneous Streaming: The responses from two models are streamed back in real-time, allowing you to compare the speed of responses as well.
Efficient Model Orchestration: The Comparison Mode is built with Hades, a Kubernetes-based orchestration system that efficiently spins up and down models on demand, based on which models you need.
We’re still working with the fictional NextGen Education, an Education Tech company, from the previous blog post. We’re helping their marketing department with their social media campaign this time. They want to use an LLM to create a promotional post for their new product, PlanlyAI, an AI-powered tool to help teachers make lesson plans (what we did in our previous blog post).
They have decided to pick a Llama-2 7B model and have secured enough budget to host it in full precision. However, they can also choose to save much more by hosting a quantized or compressed version of Llama 2 7B on a smaller AWS instance, allowing them to spend more on marketing campaigns. But they’re still a bit hesitant about the performance loss that comes with quantization. In order to reassure them about using quantized models, they will have to see an output that is not significantly worse than that of the unquantized model.
This is the prompt we’re going to use:
Craft a compelling and concise marketing tweet for NextGen Tech, promoting their new product, PlanlyAI. PlanlyAI is an innovative AI-powered platform designed to assist teachers in generating comprehensive and engaging lesson plans efficiently. The tweet should emphasize the benefits of PlanlyAI, such as its ability to save time, enhance lesson quality, and personalize learning experiences. Highlight the user-friendly nature of the platform and its alignment with modern teaching needs. Include a call to action encouraging educators to explore PlanlyAI for their lesson planning needs. The tone should be enthusiastic, professional, and focused on the transformative impact of PlanlyAI in the educational sector. Ensure the tweet is under 280 characters, making it suitable for Twitter.
Here’s what it looks like in Comparison Mode:
We see that the outputs from the quantized and unquantized models aren’t very different from each other, and the marketing department will be pleased to know that they will have saved some compute costs for their marketing costs.
The comparison mode is a lightweight and helpful way to compare the outputs of two models side-by-side. It allows for quick experimentation to select the better model or sometimes even to test a hypothesis (that quantized models do not differ much from those in full precision). If you’re keen to incorporate LLM Arena into your AI game plan, do reach out to us.
TitanML enables machine learning teams to deploy large language models (LLMs) effortlessly and efficiently. Our flagship product, Titan Takeoff Inference Server, is already supercharging the deployments of several ML teams.
Founded by Dr. James Dborin, Dr. Fergus Finn, and Meryem Arik and backed by key industry partners, including AWS and Intel, TitanML is a team of dedicated deep learning engineers on a mission to supercharge the adoption of enterprise AI.
It is no secret that we built Titan Takeoff to make it easy for you to make inferences and deploy your models. With the nitty-gritty details of deployment and technical complications of running massive models abstracted away, you can stop worrying about performance issues and instead focus on what really matters - how to select the best model for your use case and get your preferred model to product quality outputs.
We recognize that the model selection and prompt engineering process are critical as this can influence the user experience and satisfaction with your applications. We also know that this process is complex, usually requiring many rounds of repeated experimentation.
Simplified Model Selection and Prompt Engineering with LLM Arena
In order to help you with this challenging process, we have built the LLM Arena. This interactive web application allows you to quickly compare the outputs across different models, as well as prompts. We’ve abstracted away all the technical complexities of deploying other models so you can use our simple interface to compare different models and prompts, speeding up the experimentation and development of your AI-powered application.
In this article, we will be featuring one of the modes of LLM Arena, Tournament Mode, where users can host a knockout-style tournament for Large Language Models, allowing them to judge and compare outputs between various models and find the ultimate winning model that produces the best output. It is a fun but also useful way to select the most appropriate model.
Model Selection: You can pick the number of models to be included in the tournament (4 or 8) and choose which models to have. It will automatically create a tournament bracket with your preferred models.
Knockout style Tournaments: Two models face each other in each battle, with the winner advancing to the next round and the other being eliminated
Blind Model Test: The names of the models are not revealed until the tournament ends to reduce bias when judging models.
Efficient Model Orchestration: The Tournament round is built with Hades, a Kubernetes-based orchestration system that efficiently spins up and down models on demand. It saves you the need to deploy many models simultaneously, which would be extremely expensive. It also saves you the hassle of manually spinning up and down models compared to just deciding to spin up one or two models at the same time.
Let’s say we’re an Education Tech company called NextGen Education. One of our internal tools is an AI-powered application that creates course materials for teachers and instructors. We’re looking to create a five-day lesson plan for high school students learning how to code with Python from scratch.
We have calculated that we have just enough budget to deploy an optimized 4-bit 7 Billion parameter LLM, but are not sure which LLM would be the most appropriate for our specific use case, so putting our four shortlisted 7 Billion models in a tournament to compare outputs and decide a winner sounds like a perfect way to determine how it works.
We can select four 7B models to compare. Here, we choose Intel’s Neural Chat, Llama-2, Mosaic ML’s MPT, and Intel’s NeuralChat. Then we can start the tournament. It pairs up the models into tournament brackets and loads up the first two models. In order to be impartial, the names of the models are not revealed until the end of the tournament. Let’s paste in our prompt (Create a five-day lesson plan to teach high school students how to code with Python from the very beginning).
Here, we can compare the outputs of the two models side-by-side very easily, evaluate their outputs, and pick the best one to advance to the next round. You will have a chance to assess each shortlisted model through the tournament bracket. Before each battle, our orchestration system, Hades, will spin down the old models and spin up the new models dynamically, saving you the need to deploy all the models at the same time.
At the end of the tournament, the names of each model will be revealed, as well as the winning model. Congratulations, you have found a model most suited for your prompt. However, playing multiple tournaments is recommended before you select a suitable model to ensure outputs are consistent, reliable, and appropriate. You should battle-test your models to ensure that your models behave properly when receiving inappropriate or ambiguous requests.
Selecting a model best suited for your use case is essential as it can determine the quality of your outputs and user experience with your AI-powered app. It usually requires repeated experimentation that may be troublesome and impractical without suitable tools. The LLM Arena, built on Titan Takeoff, bridges this gap by allowing you to focus on experimentation to select the suitable model by abstracting the complex logic of model orchestration. If you want to incorporate LLM Arena into your AI game plan, do reach out to us.
TitanML enables machine learning teams to deploy large language models (LLMs) effortlessly and efficiently. Our flagship product, Titan Takeoff Inference Server, is already supercharging the deployments of several ML teams.
Founded by Dr. James Dborin, Dr. Fergus Finn, and Meryem Arik and backed by key industry partners, including AWS and Intel, TitanML is a team of dedicated deep learning engineers on a mission to supercharge the adoption of enterprise AI.
TitanML is introducing a new feature, Structured Generation, which is designed to give you more control over your models and revolutionise how you interact with and process data outputs. Our NLP Engineer, Josh, recently showcased this development in the video above and we're here to walk you through our findings and what it means for you and your projects.
Structured generation is a technique focused on producing data in a specific, pre-defined format. Unlike traditional unstructured or semi-structured outputs, structured generation ensures data consistency and adherence to a predetermined schema or format, making it highly efficient for further processing and analysis.
This has been realised in two forms - Regex decoding, and JSON Decoding. Regex decoding is designed for shorter outputs or those requiring character-level precision in their format. JSON decoding is more suited to producing primitive types structured into objects following a set schema, with this schema defined using the JSON-Schema language.
The main advantage of using structured generation lies in its ease of integration with your downstream tasks. By forcing the model to produce data in a consistent format, it reduces the need for additional processing or data cleaning. This ensures not only a streamlined workflow, but also compliance with the typed ontologies and the ability to inject further prompt information local to individual values being generated.
In the video, we illustrated the practicality of structured generation with a simple example: generating the birth date of Bob Marley. The language model can output this information in three different formats: unstructured, semi-structured, and structured. While unstructured data might be suitable for casual conversations, structured data, like dates in ISO 8601 format, are immediately usable in a database or for further computational processes as they adhere to a predefined YYYY-MM-DD schema.
This functionality can be achieved through masking out next tokens which do not adhere to the requirements of the regex. This is achieved by converting the regex into a finite state machine, and traversing it in tandem with the generation of tokens. A key challenge arises here with tokenisation - language models typically operate on tokens, which usually do not align with individual characters. As such, the FSM must be traversed with multiple transitions per token. The masking out of non-compliant tokens is achieved by driving down their assigned value in the generated logits, as to make it impossible for it to be selected as the next token.
Another aspect of structured generation is the use of JSON schemas. These schemas define the structure of the output, ensuring that it adheres to a specific format. They offer a blueprint for the data structure, specifying what fields are expected and their data types.
For example, if you need information about a city, you can define a schema with fields like country, population, and even list of city districts etc. The language model then generates data that fits this schema, making it incredibly useful for structured data queries. A further benefit here is the proximity of the key to the tokens being generated - the model can be seen to be further prompted by virtue of the adjacent key.
In order to address the challenges of structured generation in JSON, we are proposing a set of decoding rules called JSON DeRuLO (Decoding Rules for Language Output):
Information extraction or generation into JSON according to a specified Schema
Guaranteed adherence to required types
Allowance for extra prompting within keys (tokens detailing specifics of required information are immediately local to those being generated)
Option to extract data solely as spans from an input text (as a bulletproof RAG implementation)
Structured generation represents a significant leap forward in improving the usability and application of language models. Whether you're working on complex data analysis, building databases, or simply need precise information extraction, structured generation is set to be a game changer.
TitanML enables machine learning teams to effortlessly and efficiently deploy large language models (LLMs). Their flagship product, Titan Takeoff Inference Server, is already supercharging the deployments of a number of ML teams.
Founded by Dr. James Dborin, Dr. Fergus Finn and Meryem Arik, and backed by key industry partners including AWS and Intel, TitanML is a team of dedicated deep learning engineers on a mission to supercharge the adoption of enterprise AI.
Welcome to the world of retrieval augmented generation (RAG) — a groundbreaking approach revolutionizing natural language processing applications. In the pursuit of creating more coherent, contextually relevant, and informative content, researchers have devised an innovative methodology that combines the prowess of retrieval-based techniques with the fluency of generative models. This combination enables machines to not only generate text but also retrieve and incorporate pertinent information from vast repositories, leading to a more refined, context-aware, and knowledgeable output. In this walkthrough, I hope to elucidate the
techniques involved in building a RAG application, and provide a template to emulate for your own projects. As always, we at TitanML take away the tricky parts of initialising, building, optimising and orchestrating your models, so you can get straight into coding the application around them, prototyping your product and iterating on your big ideas.
So, what is RAG? Simply put, it is a technique for providing extra information to our models before expecting back an answer. This may be necessary because you want:
it to answer questions based off of information outside of its knowledge base.
to ask questions about events after the model's cutoff date.
access to niche or specialised information (without the hassle of finetuning).
or most commonly: you want the model to be able to inference about private data. Think medical records, emails, company docs and contracts, IP, anything internal that never had a chance to appear in the public internet scrape that went into the initial training.
The idea behind RAG is to first go and collect the relevant bits of information from our large pool of documents and then add this text, hopefully containing the answer to the question, as an extension to our prompt of the generation model. Rather than make anything up, the model just has to read and extract the answer from the context provided. The
way we can make comparison between texts and queries is based off of the idea of textual embeddings - if done well, similar text (words, sentences, sections or whole documents) should be embedded into similar vectors. We can then rank text matches between our query and passages using simple vector comparison maths, and hopefully receive high scores when the
passage has similar content to what the question is alluding to.
A RAG workflow: a method to augment our prompts to help chat models answer questions on our personal data. Note our 'augmented' prompt is a combination of the context, the query and a prompt template.
For this demo we are switching industry - we are going to emulate a big bank with billions of assets under management - and importantly, our company information is split across a sea of distributed documents. For our application we need our chatbot to be able to retrieve and recall from these private documents, so the answers provided are correct, even though the corpus is not in the model's knowledge base.
documents =[ "Our research team has issued a comprehensive analysis of the current market trends. Please find the attached report for your review.", "The board meeting is scheduled for next Monday at 2:00 PM. Please confirm your availability and agenda items by end of day.", "Our quarterly earnings report will be released to the public on the 10th. Senior management is encouraged to prepare for potential investor inquiries.", "The due diligence process for the potential merger with XYZ Corp is underway. Please provide any relevant data to the M&A team by Friday.", "Please be informed that our compliance department has updated the trading policies. Ensure all employees are aware and compliant with the new regulations.", "We're hosting a client seminar on investment strategies next week. Marketing will share the event details for promotion.", "The credit risk assessment for ABC Corporation has been completed. Please review the report and advise on the lending decision.", "Our quarterly earnings for the last quarter amounted to $3.5 million, exceeding expectations with a 12% increase in net profit compared to the same period last year.", "The investment committee meeting will convene on Thursday to evaluate new opportunities in the emerging markets. Your insights are valuable.", "Our asset management division is launching a new fund. Marketing will roll out the promotional campaign in coordination with the release.", "An internal audit of our trading operations will commence next week. Please cooperate with the audit team and provide requested documents promptly.", ]
For this demo, orchestration and inference of both models is going to be handled by a Takeoff Server.
Our server runs inside Docker containers, so we can deploy and manage them from python using the docker-sdk. Reach out to us here to gain access to the Takeoff Pro image (all the SOTA features), or pull and build the community edition here and adapt your code accordingly.
TAKEOFF_IMAGE_BASE ='tytn/takeoff-pro' # Docker-sdk code defis_takeoff_loading(server_url:str)->bool: try: response = requests.get(server_url +"/healthz") returnnot response.ok except requests.exceptions.ConnectionError as e: returnTrue defstart_takeoff(name, model, backend, device, token=HF_TOKEN): print(f"\nStarting server for {model} with {backend} on {device}...") # Mount the cache directory to the container volumes =[f"{Path.home()}/.takeoff_cache:/code/models"] # Give the container access to the GPU device_requests =[docker.types.DeviceRequest(count=-1, capabilities=[["gpu"]])]if device =="cuda"elseNone client = docker.from_env() image =f"{TAKEOFF_IMAGE_BASE}:0.5.0-{'gpu'if device =='cuda'else'cpu'}" server_port =4000 management_port =4000+1 container = client.containers.run( image, detach=True, environment={ "TAKEOFF_MAX_BATCH_SIZE":10, "TAKEOFF_BATCH_DURATION_MILLIS":300, "TAKEOFF_BACKEND": backend, "TAKEOFF_DEVICE": device, "TAKEOFF_MODEL_NAME": model, "TAKEOFF_ACCESS_TOKEN": token, }, name=name, device_requests=device_requests, volumes=volumes, ports={"3000/tcp": server_port,"3001/tcp": management_port}, shm_size="4G", ) server_url =f"http://localhost:{server_port}" management_url =f"http://localhost:{management_port}" for _ inrange(10):# Give te server time to init and download models ifnot is_takeoff_loading(server_url): break print("building...") time.sleep(3) print('server ready!') return server_url, management_url
takeoff_url, takeoff_mgmt = start_takeoff( 'rag-engine',#container name chat_model,#model name 'compress-fast',#backend 'cuda'#device ) # in terminal run: 'docker logs rag-engine' to see status # first time running this may take a while as the image needs to be downloaded
Starting server for meta-llama/Llama-2-7b-chat-hf with compress-fast on cuda... building... building... building... server ready!
Takeoff streams generated tokens back from the server using Server Sent Events (SSE). These two utility functions help print the tokens in the response as they arrive.
defprint_sse(chunk, previous_line_blank=False): chunk = chunk.decode('utf-8') text = chunk.split('data:') iflen(text)==1: returnTrue text = text[1] ifnot previous_line_blank: print('\n') print(text, end='') returnFalse defstream_response(response): prev =True for line in response.iter_lines(): prev = print_sse(line, prev)
We now have an inference server setup and ready to answer our queries, but with no RAG included - this means our model is going to have to wing it. Let's see how it does:
Our quarterly earnings are as follows: Q1 (April-June) Revenue: $100,000 Net Income: $20,000 Q2 (July-September) Revenue: $120,000 Net Income: $30,000 Q3 (October-December) ... Total Net Income: $100,000 Note: These are fictional earnings and are used for demonstration purposes only.
The model even admits itself that its answers are completely made up! This is good honesty, but also makes the generations absolutely useless to our production applications.
Vector databases are specialized databases designed for handling and storing high-dimensional data points, often used in machine learning, geospatial applications, and recommendation systems. They organize information in a way that enables quick similarity searches and efficient retrieval of similar data points based on their mathematical representations, known as vectors, rather than traditional indexing methods used in relational databases. This architecture allows for swift computations of distances and similarities between vectors, facilitating tasks like recommendation algorithms or spatial queries.
One of the essential pieces of a RAG engine is the vector database, for storing and easy access to our text embeddings. It is an exciting space, and there are a number of options to pick from out in the ecosystem (Dedicated vector database solutions: Milvus, Weaviate, Pinecone. Classic databases with vector search functionality: PostgreSQL, OpenSearch, Cassandra). However, for this demo we don't need all the bells and whistles, so we're going to make our own minimal one right here, with all the functionality we need. The VectorDB in our app sits external to takeoff, so feel free to swap in/out and customise to fit your personal VectorDB solution.
Our VectorDB needs a place to store our embedding vectors and our texts; as well as two functions: one to add a vector/text pair (we track their colocation by shared index) and one to retrievek documents based off 'closeness' to a query embedding. The interfaces to our DB take in the vectors directly so we can seperate this from our inference server, but feel free to place the calls to the models via Takeoff within the VectorDB class.
We can now populate our makeshift database. To do so, we send our text in batches to the embedding endpoint in our Takeoff server to receive their respective embeddings to be stored together.
This example uses a conservative batch size to matcch our small demo - but feel free to tune to your own needs.
batch_size =3 for i inrange(0,len(documents), batch_size): end =min(i + batch_size,len(documents)) print(f"Processing {i} to {end -1}...") batch = documents[i:end] response = requests.post(takeoff_url +'/embed', json ={ 'text': batch, 'consumer_group':'embed' }) embeddings = response.json()['result'] print(f"Received {len(embeddings)} embeddings") for embedding, text inzip(embeddings, batch): db.add(embedding, text) db.stats()
Processing 0 to 2... Received 3 embeddings Processing 3 to 5... Received 3 embeddings Processing 6 to 8... Received 3 embeddings Processing 9 to 10... Received 2 embeddings {'vectors': torch.Size([11, 1024]), 'text': 11}
For each of our 11 documents, we have a (1, 1024) vector representation stored.
Let's quickly remind ourselves of our original query:
print(query)
What are our quarterly earnings?
This is the first part of our new RAG workflow: embed our query and use our db to match the most relevant documents:
response = requests.post(takeoff_url +"/embed", json ={ 'text': query, 'consumer_group':'embed' }) query_embedding = response.json()['result'] # Retrieve top k=3 most similar documents from our store contexts = db.query(query_embedding, k=3) print(contexts)
['Our quarterly earnings report will be released to the public on the 10th. Senior management is encouraged to prepare for potential investor inquiries.', 'The investment committee meeting will convene on Thursday to evaluate new opportunities in the emerging markets. Your insights are valuable.', 'Our quarterly earnings for the last quarter amounted to $3.5 million, exceeding expectations with a 12% increase in net profit compared to the same period last year.']
With this extra information, let's see if our model can provide the correct answer:
context ="\n".join(contexts) augmented_query =f"context: {context}\n be as precise in your answer as possible, just give the answer from the context\nquery: {query}?\nanswer:" response = requests.post(takeoff_url +"/generate", json={'text': augmented_query} ) answer = response.json()['text'] print(answer)
defget_contexts(question, db, k=5): response = requests.post(takeoff_url +'/embed', json ={ 'text': question, 'consumer_group':'embed' }) question_embedding = response.json()['result'] return db.query(question_embedding, k=k) defmake_query(question, context): user_prompt =f"context: {context}\n be as precise in your answer as possible, just give the answer from the context\nquestion: {question}\nanswer:" return requests.post(takeoff_url +'/generate_stream', json={'text': user_prompt}, stream=True) defask_question(question): contexts = get_contexts(question, db, k=5) contexts ="\n".join(reversed(contexts))# reversed so most relevant context closer to question return make_query(question, contexts)
stream_response(ask_question("what is the research team working on?"))
The research team is working on a comprehensive analysis of the current market trends.
queries =["Which corporation is doing our credit risk assessment?", "what is the research team working on?", "when is the board meeting?"] for query in queries: print(f"Question: {query}") stream_response(ask_question(query)) print("\n=======================================================")
Question: Which corporation is doing our credit risk assessment? ABC Corporation. ======================================================= Question: what is the research team working on? The research team is working on a comprehensive analysis of the current market trends. ======================================================= Question: when is the board meeting? Monday at 2:00 PM. =======================================================
And that is it! We have an end-to-end application that is capable of interpreting and then answering detailed questions based off of our private, internal data.
The beauty of RAG is that we get the perks of generative models: we can interface our application with human language, and our model understands and adapts to the nuances and intentions
of our question phrasing, and the model can explain and reason its answer; plus, we get the benefits of retrieval models: we can be confident that the answer is correct, based on context, has a source,
and is not an infamous hallucination. In fact, as more and more people start bringing generative models into their products, RAG workflows are rapidly becoming the de facto way to design an application around the model at the core.
While the landscape of model deployment and orchestration can be challenging, the integration of two interdependent models may seem like an added layer of complexity. Luckily, TitanML is here to help - our expertise lies in managing these intricacies, so you can focus on your application and accelerate your product development.
TitanML enables machine learning teams to effortlessly and efficiently deploy large language models (LLMs). Our flagship product Takeoff Inference Server is already supercharging the deployments of a number of ML teams.
Founded by Dr. James Dborin, Dr. Fergus Finn and Meryem Arik, and backed by key industry partners including AWS and Intel, TitanML is a team of dedicated deep learning engineers on a mission to supercharge the adoption of enterprise AI.
In the race to build amazing AI-powered applications, it is no secret that Machine Learning (ML) engineers spend most of their time and efforts on optimising their models and improving the quality of their outputs. Working in a fast paced industry with pressing deadlines, they usually overlook the importance of creating an efficient inference server. As a result, they end up hacking together a poorly designed inference server that doesn't do justice to their amazing models.
Since the inference server sits between the user and the model, its poor performance would offer users a poor user experience either through slow response times and low capacity. To use an analogy, just imagine the absurdity of listening to high quality Audiophile music with your low budget supermarket earphones! Your inference server is just like your earphones, you can't enjoy the high throughput (how many requests a system can process in a given amount of time) and low latency (time the system takes to respond to a single request) of your models if your inference server is inefficient!
We're going to step through the mind of a engineer who is trying to deploy their language model to production - why their first instincts may not be the best and how they can use Rust to supercharge their inference server.
Let's pretend you are an ML Engineer who is working on a new chatbot for a customer facing website. You have spent the last few weeks training a new language model and are ready to deploy it. It's a masterpiece and you've got highly performant benchmarks. You're running tight to deadlines and your product owner is breathing heavily down your neck. But armed with your benchmarks you present your work and they are delighted. You now need to get this model into production fast. The last step is creating a user interface to the model - an inference API.
You're familiar in Python so look to its stack and see there are some exciting options to build with: Flask, FastAPI, Django, etc. From reading online you see most buzz around FastAPI, so you select that and manage to follow the relatively simple setup and produce a working API. You're happy with your work and deploy it as the interface to your model. You confidently inform your product owner who is delighted and start planning out your next holiday with the massive performance bonus sure to come your way.
A couple weeks go by and you receive feedback that the model is not performing as expected - it's slow and customers are complaining. You're confused as your benchmarking showed how fast and performant your model was. You start to dig into the issue and realise that the API is the bottleneck. You calmly inform your product owner you'll sort it out.
You see that the problem is that the API is pushing prompts to the model individually although your model is capable of processing a number of prompts simultaneously. You then start implementing some batching in the API, collating requests to the API together so you can maximise the throughput of the model. This is done by spinning up an async (asynchronous) Python thread with a queue to batch requests (batching daemon). Each route handler of the API then pushes its requests to this thread, which is pushed to the model once it is filled. You then write out some testing, deploy the new solution to production and inform your product owner about your impressive fixes you managed to turn around in a week.
A few days go by and to your dismay, your product owner comes back and says the fix has not worked as the number of complaints from users is persisting. You try to explain the nuance that the problem is not your model but the inference server, which is slightly out of your expertise. Your superior doesn't want to hear it. They only care about the customer complaints and getting out of hot water with their bosses. It's back to the drawing board and you try to understand why this batching isn't as effective as you thought.
From further research you start to discover the pitfalls of the simple Python API framework. You read that Python async library is non-preemptive: simply meaning that while an async task is running, nothing else can run. Furthermore, when async programming Python still uses an underlying thread or process for the event loop. This means that if you have blocking or CPU-bound code in your async application, it can potentially affect the performance of other asynchronous tasks running in the event loop. So your batching approach when implemented in Python is not as clean or simple as you thought. Then the questions start rolling in: do you rip it up and start again? Should you change tech stack? Are there other solutions out there? How long will this take?....
While you've been distracted all other projects you were meant to be doing are on hold. Other product owners are not happy, there is no obvious solution and you are going to have to tell your product owner that the benchmarks you quoted are not going to be met. You're not sure what to do and start to panic, the holiday you were planning is now a distant dream.
You may dismiss this warning as hyperbole but this is currently happening across the industry. ML Engineers are having to hack together solutions to get their models deployed. They are not experts in API development and do not have the time to be aware of the pitfalls. This is completely understandable as they are ML Engineers not DevOps/Software Developers!
Let's take a breath and step back from the problem. We have a model that is performing well but the inference server is not. We need to find a way to maximise the throughput of the inference server without hitting the pitfalls of Python async. So what would the ideal solution look like:
Fast: We want to maximise the throughput of the ML Model so we can serve as many requests as possible. To do this we need a fully async server that can effectively batch requests to reach a high throughput.
Safety: In implementing our async batching server we want to be thread and memory safe, so requests are returned correctly.
Thread Safe: We want the server to be able to handle a large number of requests concurrently while accessing the same ML model. Therefore, it is imperative that the server is thread safe, so we don't end up in race conditions, deadlocks, or other unexpected behaviour.
Memory Safe: We want to avoid memory leaks and other memory related issues that can cause the server to crash or subtler bugs such as incorrect responses being returned.
Speed of Iteration: As stressed the typical ML Engineer is inundated with deadlines and projects, so we need a solution that is easy to implement and maintain. We don't want to have to spend weeks learning a new languages or framework to get our model deployed.
Sadly, like most things in life there is no perfect solution. The most common languages an ML Engineer would typically work with are Python, R and maybe Java/Javascript. None of them are inherently Thread Safe. For instance, Python has a global interpreter lock, which only allows one thread to run at one time (per process). On the other hadn, the safer and more performant languages such as Rust or Go may be unfamiliar to the typical engineer and would take a longer time to develop in. It seems that there is a tradeoff between spending more time learning an unfamiliar new language and accepting substandard performance.
Now we know the pitfalls of building an inference server, let's choose the best tool for the job. The standout languages for this job are Rust and Go.
Rust is a systems programming language that runs fast, and is purpose build for async programming guaranteeing thread and memory safety. Although Rust is a compiled language and can be more time-consuming to write, this is offset by less time fixing runtme errors and increased performance at runtime.
Go (or Golang) is a statically typed, compiled programming language designed for simplicity and efficiency. It features a built-in concurrency model (Goroutine) and a rich standard library, priding itself on its useability.
Both are fast, safe and have a number of web frameworks to choose from. Comparing the two, Rust has a steeper learning curve but is safer. This is due to the strictness of the Rust compiler and other safeguards in Rust such as reference lifetimes. The simplicity of Go to learn leading to a slight trade off in safety/performance for speed of iteration. We are ignoring speed of iteration for now so we are going to pick Rust as our language of choice.
Naturally we're partial to Rust but we would need to evaluate if it is fit for purpose? We can start by consulting third party independent body: Techempower, who benchmarked hundreds of web frameworks. From their most recent testing, Rust frameworks have consistently scored highest across the board (color coded purple). Specifically, the Rust frameworks excelled at the multiple queries which is the most relevant to inference server throughput. So it seems like Rust is a good choice.
Similarly to Python, there are numerous web frameworks out there in Rust which are easy to work with such as Salvo, Axum and Actix. We chose Axum which is built on top of Tokio, Rust's most popular async runtime. So this enabled us to implement batching requests truly asynchronously using Tokio ecosystem.
Now we have our ideal inference server we want to test its limits before we can feel confident about deploying it to a real-world production environment. We will use the FastAPI framework in Python as our control to compare the performance of Rust. Both servers implement the same batching logic and were ran with the same 125 million parameter model, on the same machine, with the same configuration. We used Locust to facilitate the load tests.
Device: cuda (Nvidia GA106 [GeForce RTX 3060 Lite Hash Rate])
Max batch size: 50
Batch timeout: 100ms
Request body:
{ "text":"Hello World, what is your name dog?", "max_new_tokens":10 }
Our load test spun up 40 concurrent users all firing requests as fast as possible to the server. Each user dispatched prompts to our /generate endpoint with a max_new_tokens of 10 to ensure consistency of output. The throughput was quantified by the rate of simultaneous requests the server could handle. This is slightly different from the frequently used tokens per second statistic to quantify benchmark model throughput and is a more specific metric focusing on the API's performance.
This is a great result but we have ignored one of our key criteria to achieve this solution: speed of iteration. How do we expect an ML Engineer to learn Rust and start building Rust servers on top of their normal responsibilities? The answer is we don't and that's why we built Titan Takeoff Server! The Pro version of Titan Takeoff Server features a fully optimised Rust batching inference server to maximise the throughput of your models. This is a great example of how TitanML is helping ML Engineers focus on what they do best: building amazing language models and not worrying about deployments. Get in touch with us at hello@titanml.co to find out more about Takeoff and how it can help your business.
TitanML enables machine learning teams to effortlessly and efficiently deploy large language models (LLMs). Their flagship product, Titan Takeoff Inference Server, is already supercharging the deployments of a number of ML teams.
Founded by Dr. James Dborin, Dr. Fergus Finn and Meryem Arik, and backed by key industry partners including AWS and Intel, TitanML is a team of dedicated deep learning engineers on a mission to supercharge the adoption of enterprise AI.
Massively parallel hardware accelerators, such as GPUs, have played a key role in providing the computational power required to train modern machine learning models, especially recent Large Language Models (LLMs). Training these models can still take several months, regardless of the amount of resources allocated to them.
The problems, however, don't stop at training - these models are so large and unwieldy that just interacting with and inferring from them can also be a challenge. This is particularly pertinent for language modelling use cases which need almost real-time responses to not frustrate users - no one wants to talk
to a chatbot that takes a few seconds to send each word. Now imagine how tricky this gets as you scale your application to thousands of concurrent users! Fortunately, in these situations where the models are too big or the request traffic too high, we can turn back to the same hardware that built these models in the first place: large,
massively parallel clusters of GPUs.
To begin, we need to start with a reality check on the computational speed ups available to us through parallelisation. Equation 1 is Amdahl’s law, and relates the fraction of our program that can be parallelised with the number of parallel nodes we have available, to calculate our potential speed up. This speed up is a theoretical limit as it doesn’t include any communication costs between our processes, which will apply heavily in our multi-gpu environment for result reconciliation and aggregation.
Speedup(S)<=(1−f)+Nf1
Equation 1:
S
is the theoretical speedup,
f
is the fraction of our program that can be parallelised and
N
is the number of nodes we have to parallelise across.
Fig 1: Visualisation of how the nature of our program dictates how we can parallelise it.
Here we visualize distributing our ML program across a number of parallel devices. Parts of the program (in blue) must inevitably run in series, such as data retrieval and preprocessing, initialising the parallel nodes and closing the program with some postprocessing. Likewise, the orange blocks represent computations
that can happen simultaneously, such as passing a single input through our model, and we are capped by our available nodes as to how many units can run simultaneously. If these units exceed our number of devices,
they must execute consecutively on our devices.
This means using the absolute theoretical limit, when splitting our program over 2 GPUs, we cannot expect to pass the limit of half of the original time taken - and should expect a time somewhat greater than this due to the serial parts of our program, pre- and post-processing, plus the communication overheads required between our parallel processes.
So, while any speed up is good news, to appreciate the real appeal of stacking our GPUs, we need to segue into some more inference metrics.
Latency and throughput are two fundamental performance metrics used to grade computing systems, and while we usually want competitive values in both, our use case can prioritise one over the other.
Latency: often referred to as response time, measures the time it takes for a single unit of data to traverse a system from source to destination - in the context of our LLMs this is the time we see between each subsequent token returning from our models.
Throughput: on the other hand, quantifies the rate at which data can be processed or transmitted within a given time frame - for our LLMs this value describes our output tokens per second. Higher throughput indicates our system's ability to handle a larger volume of requests efficiently.
Fig 2: Latency vs. Throughput vs. Bandwidth.
While these two values may appear similar and are, in fact, inherently interconnected (reducing latency typically leads to increased throughput), there are subtle ways we can tweak them individually.
Batch size: LLMs consist of numerous consecutive matrix multiplications, and when processed on massively parallel devices like GPUs, the time required to handle a batch of inputs through these operations is negligibly increased compared to a single input (to an extent). See Fig 3: if we can process multiple inputs simultaneously, at low cost to the execution time, we can multiply the tokens passing through and outputting from our model per unit time - this is a big boost to our throughput. (Note: on a sequential processor like a CPU, these steps have to execute consecutively and you lose the benefit).
Fig 3: GPUs parallelise matrix multiplication by tiling the input matrices and processing them simultaneously in individual threads. If matrix A is our batches of inputs, B our weights, and each tile runs concurrently, we can get a lot extra computation done in the same time by increasing our batch size (height of A) with just a small cost to recompose the output from the sub units.
Quantization: a lot of time is spent moving large chunks of data around to be processed in a system with limited bandwidth, causing queues and bottlenecks. One of the big advantages to quantizing our models, apart from allowing use of bigger models, is massively reducing the size of our data, and increasing the speed it can be transferred. This is a win for latency.
Caches: There are many repetitious calculations that occur during the inference process, and if we can store the results of these calculations in a cache, we can save time by not having to recompute them. This is a win for latency, and improves our throughput in the process.
To summarize, latency measures speed and throughput measures volume - and the latter is where we're going to see our dramatic results! Bigger batch sizes is a significant opportunity for boosting our throughput, and allowing our deployed model to serve many users concurrently while keeping performance competitive. The problem is these batches need space to work with:
Fitting a model (and some space to work with) on our device
Firstly, lets calculate the raw size of our model:
Size (in Gb) = Parameters (in billions) * Size of data (in bytes)
And let’s see how these numbers look for some of the most popular models:
Model
fp32
fp16
int8
OPT-1.3b
5.2
2.6
1.3
Llama2-7b
28.0
14.0
7.0
Llama2-13b
52.0
26.0
13.0
Flan-T5-L
3.1
1.6
0.8
Flan-T5-XL
12.0
6.0
3.0
BERT-L
1.2
0.6
0.3
BERT-XL
5.2
2.6
1.3
Table 1: Model sizes in Gb for different precisions.
Our first imperative for working with GPUs is that the model itself needs to be able to fit within the devices’ VRAM. So looking at the following range of common GPUs, we can see that for a Llama-7b at fp16, some GPUs are inaccessible and for Llama-13b at fp16 all but the A100s are unusable, unless we can find a way to split the model across more than one device. So our first lesson: for large models, it may be a necessity to split it across a multi-gpu backend just to be able to run it.
GPU prices also grow exponentially with their size, so chances are you are more likely to be able to afford multiple smaller GPUs than a single large one.
GPU
VRAM
3060
12
V100
16
4090
24
A10
24
A100
40/80
Table 2: GPU memory capacity in Gb.
Next we need to think about how much extra space we need reserved for our rolling calculations. There is a back of the envelope esimate1 that for a 13b parameter model, each token requires 1mb of additional space for continuous values.
So a prompt of 128 tokens, with a desired generation of 128 tokens will require 256mb of additional space. This seems like a low amount, but that means a batch size of 48 would max out our 3060 GPU without even the model present!
But to increase our throughput and the amount of users we can serve concurrently, we know we need to up our batch size. This is the next argument for splitting our model across GPUs: it leaves more space on each device for running the
inference on an increased amount of inputs.
There are a couple of ways we can approach our multi-gpu environment:
Repeat our model on multiple devices: this is the simplest approach, and will afford us throughput increases without any inter-gpu communication costs. The technique involves simply loading the model
individually onto each of our GPUs, and using a queue system to distribute incoming requests to each of the models. The main advantage to this approach is simplicity, but some downsides are evident. For one, there is a lot of redundant
information wasting precious GPU space by repeating the same weights across all the devices. This approach also stuffs a large model into each GPU, reducing the capacity left to fit in our runtime data, forcing us to operate at lower batch sizes.
Split our model: the alternative is to chunk our model and split it across the devices. This way is much more complex to code, and also comes with some communication overheads, as the model needs to costantly combine calculation outputs before moving on to the next stage.
However, this way allows us to access massive models that can't normally fit on our available hardware, and also allows us to operate at much larger batch sizes, as we have more space to work with on each device.
The latter approach is particularly exciting: it is known that large models typically outperform their smaller counterparts, so if we can use our distributed hardware to unlock previously inaccessible models like llama-13b then this is a big win.
Fig 4: Multiple replicas of a model vs. a sharded model.
How to split a model: pipeline vs tensor (vs data) parallelism
Data parallelism is option 1) in the previous section, whereby different chunks of our data are processed in parallel on replicas of the model. For reasons
previously discussed, we wish to split our model across our devices and there are a few ways we can achieve this, the most common being pipeline or tensor parallelism.
This involves splitting our model layers across our devices. After one device has finished processing its chunk of the model, it passes the intermediate values to the next device to continue the computation. While this is a simple approach, it is limited by the sequential nature of the model, and the fact that the each device must wait for the previous to finish before it can move on to the next layer. This means both devices can sit idle for a large portion of the time, while the other is processing. We have managed to split our model across devices, but have lost our parallel execution.
Someone smart noticed the above approach was underutilizing the GPUs because of bubbles of idle wait time in their computation graphs. To maximise the computation occuring, ideally we want our GPUs operating as close to 100% utilization as possible for as much time as possible.
We can achieve this by splitting our model in a slightly more ingenious way. Instead of splitting our model by layer, we split up the large matrices internal to our layers such as the big MLPs or attention modules. Different parts of the output matrix can be calcuated simultaneously and the intermediate tensors concated for the full result. As you can see in the following diagram
this calculation is equivalent so no results are compromised.
Fig 6: Matrix multiplications can be done in parts and recombined for the same result.
By following this method we can have all of our devices crunching away on heavy computation (what they are best at) at all times, at the cost of some communication overheads to synchronize tensors. Despite its added complexity,
tensor parallelism is the way to go if you want ultra competitive performance from your multi-gpu setup.
The above taster is a brief introduction to the complexities of distributed computing, and the challenges of deploying large models in production. Luckily, we at TitanML are on a mission to make this easier for you.
The following graph is a demonstration of the trials and tribulations of working with multiple GPUs. Its not as easy as just throwing more hardware at the problem, we need to assess and benchmark if its right for
the type of application we are planning to build.
Fig 8. Inference throughput achieved for different models on different GPU clusters, at different batch sizes.
Off the bat, we can see that a multi-gpu environment is wasted for a small model. The communication overheads and the fact that the model can fit on a single device means we are better off just using a single GPU. The larger GPU can work with bigger batch sizes, but the token/s is so high for the single GPU,
that the throughput is likely maintained just because of the very low latency. In this scenario, we are better off using the data parallel regime and using each GPU to host its own model.
Fig 8 also demonstrates to us how our model size can outright reject potential hardware setups - where datapoints are missing, the setup failed with dreaded Out of Memory(OOM) errors. As we can see, if you want to run a Llama-13b you're going to need more than 1 GPU.
The most dramatic effect of a 4 GPU cluster is unlocking the 256 batch size. The reduced throughput is a second hand effect of the slower latency within the cluster, but this does mean 256 individual users are receiving output simultaneously (even if at a slower rate than on the 4090s). This may be a tradeoff
that is worth it for your application. Unless you are using some very exotic batching methods such as continuous or piggyback batching (coming to Titan soon!), your next set of requests will sit queuing while the current batch is being processed. Sometimes serving more requests concurrently, even if it seems like it lowers your throughput, can
be necessary, as the total average wait time for the user is still lower - this depends on the wider context of your whole application architecture.
Running a model distributed across multiple GPUs, with all the previously discussed optimizations, can be achieved using Titan Takeoff Server2 with a single command:
docker run -e TAKEOFF_BACKEND=multi-gpu # Specify multi-gpu backend -e TAKEOFF_MODEL_NAME=meta-llama/llama-2-13b # Specify which model -e TAKEOFF_ACCESS_TOKEN=<token> # Needed for Llama-2 models -e CUDA_VISIBLE_DEVICES=<'0,1...'> # Decide which of our GPUs to use --num-gpus all # Let the docker container access these --shm-size=2gb -p 3000:3000 # Port forward takeoff-pro:gpu # The takeoff pro image
You can now send inference requests to your model using the following command, and the takeoff runtime will handle distributing the inputs, the parallel computation and aggregating the results:
curl http://localhost:8000/generate_stream \ -X POST \ -N \ -H "Content-Type: application/json" \ -d '{"text": "List 3 things you can do in London"}'
The text field can be an array of inputs with dimension matching your desired batch size, and the response will be an array of outputs of the same length.
If you wish to watch your GPU utilisation during the process, you can run the following command in a separate terminal:
watch -n0.2 nvidia-smi
Here we can see what it looks like when our model is distributed across 4 devices, and how much memory a large batch size uses up!
Fig 9: GPU utilization during parallelized inference on a cluster of 4x A10s.
The eagle eyed amongst you may have noticed that the gains going from 2 to 4 GPUs for the llama-13b model are not dramatic enough to really justify doubling our expensive hardware resources.
But! We can use our 4 GPU cluster more wisely, combining both tensor parallelism and the previously discussed data parallelism to eke much better performance out of our setup. If we split our model
across 2 GPUs, and replicate this setup twice we can utilise all 4 of our GPUs, and achieve almost double the throughput of a 4 way tensor parallel model.
Fig 10: The best performance comes from a hybrid of tensor and data parallelism. Here we get the best throughput from our cluster by halving and distributing the Llama-13b on two devices and replicating this setup on the remaining 2 GPUs. Incoming requests are greedily taken off the queue by whichever cluster of the 2 is ready to process them.
For this, now even more complex situation, we at TitanML have got you covered again! With Takeoff we can manage control groups of clustered GPUs so your requests can all hit a single endpoint (our highly optimised rust server) and we will organise
distributing these requests across multiple sets of GPUs, each holding split up models. Finding the optimal setup for your application can be a mixture of intuition and trial and error,
but with Takeoff we do as much of the initialisation and orchestration as possible, so that you can focus on rapidly prototyping and benchmarking your options.
TitanML enables machine learning teams to effortlessly and efficiently deploy large language models (LLMs). Their flagship product Takeoff Inference Server is already supercharging the deployments of a number of ML teams.
Founded by Dr. James Dborin, Dr. Fergus Finn and Meryem Arik, and backed by key industry partners including AWS and Intel, TitanML is a team of dedicated deep learning engineers on a mission to supercharge the adoption of enterprise AI.
In today's rapidly evolving tech landscape, language models like ChatGPT have taken centre stage. There's a buzz in the air as enthusiasts and researchers race to harness the full power of AI. To produce coherent and high-quality responses, these models are constructed with a colossal number of parameters, sometimes in the realm of hundreds of billions. These parameters are the essential building blocks that enable the models to interpret our queries and craft contextually relevant answers.
However, the astronomical number of parameters can be a double-edged sword. They increase computational demands, leading to slower deployment times. No one has time to wait endlessly for an AI-generated response. Hence, research is in full swing to speed up response times without sacrificing the quality of the answers.
In this article, we'll first explore the basics of text generation, before introducing an innovative decoding method designed to speed up text generation significantly, all while maintaining high-quality results.
Text generation is an iteration of two consecutive processes: forward pass and decoding.
During the forward pass, the input is processed through a sequence of layers in the model. Within these layers, specific weights and biases are applied to shape the input. At the end of this pass, the model produces a set of potential tokens, each accompanied by its probability, indicating how likely it is to follow the given input. For instance, the higher the probability, the more likely the token is to follow the input.
After the forward pass comes decoding. This is where we select a token from the list of possible tokens obtained from forward pass. Several decoding methods exist, but the most common is "greedy decoding," where we simply choose the token with the highest probability.
An illustration of the text generation process. The input is fed into the large language model, where it undergoes the forward pass. The model returns a list of potential tokens with their associated probabilities. Then, we decode by selecting the token with the highest probability and appending it to the input. This updated input then goes through the entire process once more.
After selecting the token, we append it to the existing input and pass it through the forward pass and decoding again. This iterative process forms the foundation of text generation in modern language models.
The primary reason for delayed response times in large language models becomes evident: the forward pass in these models can be time-consuming. When these models are locally hosted or are served to a limited number of users, they often use smaller batch sizes. In these cases, performing matrix multiplications to apply weights and biases is relatively easy. But the real challenge arises when loading layer weights onto local devices. This process is heavily restricted by memory bandwidth, referred to as being 'memory (or bandwidth) bound'. It's worth mentioning that for larger batch sizes, the bottleneck often shifts towards compute-bound processes. Here, techniques such as quantization might not always speed things up and could even slow down performance.
Now that we've pinpointed the bottleneck, let's see how speculative decoding offers a solution. But first, we need to take a slight detour to discuss caching.
A full text generation process, where the large language model iteratively generates a full sentence with the given input.
Caching is a strategy where temporary memory storage is used to hold copies of data, allowing future requests for that data to be accessed much more rapidly than from the main storage. In the realm of model forward passes, caching speeds up the process by storing the list of potential tokens generated so far.
Consequently, the forward pass only has to compute probabilities for the next potential token. Without caching, the forward pass has to recalculate probabilities for each token in the input again. This ability to store and rapidly access previously calculated probabilities is instrumental for speculative decoding. In speculative decoding, we not only use the forward pass to predict the next token, but also evaluate whether the selected tokens are a good choice.
Caching reduces the redundant computation by skipping tokens that have already been processed, focusing solely on calculating probabilities for potential new tokens. In contrast, disabling caching entails computing probabilities for all tokens, including the input tokens.
While small models offer low latency, they often produce text of poorer quality. In contrast, larger models may be able to produce a text of high quality, but may suffer from slow response times. Are we forced to pick our poison here? Not necessarily. Speculative decoding bridges this gap, producing content that mirrors the sophistication of larger models but at faster speeds. If you're keen on giving it a shot, here's a guide to set you on the right track:
Select a small model and a large one of your preference. Make sure they share the same tokenizer, so that we can meaningfully compare the logits of the two models.
Generate a specific number of candidate new tokens with the small model, say 3. This involves running the forward pass on the small model 3 times.
Use the larger model to forward pass the prospective new input (combining the original with the 3 new tokens). This returns lists of potential tokens with their corresponding probabilities for all input tokens.
Decode the last 4 tokens using greedy decoding (3 new tokens plus an additional one from the forward pass of the large model). Compare the decoded tokens from the large model with the candidate new tokens, starting from left to right. If the tokens match, we accept them and append them to the original input. Continue this process until the first mismatch occurs, at which point we append the token from the large model to the input. This updated input is then passed through the small model to generate 3 more tokens, and the entire process is repeated.
In the above process, each step of the iteration ensures the generation of new tokens, ranging from 1 to 4. In other words, we generate between 1 to 4 new tokens with just one forward pass from the large model. Naturally, we can experiment with varying the number of new tokens generated by the small model per iteration and choosing different decoding methods for further optimisation.
To delve deeper into the capabilities of speculative decoding, we integrated it with the AWQ inference engine and subjected it to tests across three distinct hardware platforms: Nvidia A10, RTX 3060, and RTX 4090. The AWQ framework represents a cutting-edge approach to model compression and execution in 4-bit. The weights of a model are adjusted to minimize errors, and its rapid inference kernels ensure that 4-bit inferencing can outpace its 16-bit counterpart. This is achieved even though the model is dequantized on the fly to perform matrix operations in 16-bit.
The beauty of 4-bit inference is its ability to host larger models on smaller devices. When paired with speculative decoding, these larger models can be executed as quickly or even more quickly than their smaller counterparts that are optimised for the device. You can have your cake and eat it too: now, you don’t have to choose between size and speed. You can deploy a significantly larger without compromising on speed!
For a comprehensive understanding, we compared the performance of the combination of AWQ and Speculative Decoding against other engines such as Hugging Face and CTranslate2. We chose the OPT-125m as our 'small model' benchmark for speculative decoding. The findings were nothing short of remarkable: speculative decoding sped up the OPT-13b model to deliver response times that mirrored a model that's 10x smaller on Hugging Face and one that's half its size on CTranslate2.
Speculative decoding, coupled with the AWQ engine, speeds up the OPT-13b model to a similar speed as a model 10 times smaller on Hugging Face and twice as small on CTranslate2. Pretty cool, right?!
For the sake of completeness, we've got a detailed benchmark table right below to give you the full scoop!
A benchmark table illustrating the performance of models in 3 different sizes across 3 GPUs. The values in the table indicate number of tokens generated per second.
Speculative decoding introduces an innovative strategy for enhancing the performance of large language models. By deftly navigating around memory bandwidth constraints, it accelerates text generation without compromising on quality. Yet, there is still plenty more room for improvement.
Future avenues of exploration might include using a range of decoding methods, incorporating early exits when outputs seem confidently accurate, and even venturing into speculative decoding with the LLM itself, termed as 'self-speculative decoding'.
TitanML enables machine learning teams to effortlessly and efficiently deploy large language models (LLMs). Their flagship product Takeoff Inference Server is already supercharging the deployments of a number of ML teams.
Founded by Dr. James Dborin, Dr. Fergus Finn and Meryem Arik, and backed by key industry partners including AWS and Intel, TitanML is a team of dedicated deep learning engineers on a mission to supercharge the adoption of enterprise AI.
One of the most notable features of large language models (LLMs) is actually in the name - they are large (shocking, I know). Up to the very recent past, even models as large as 10B parameters were considered cumbersomely large, and inconvenient to work with.
Now, all of a sudden, these models are popping up on Raspberry Pi's, laptops, and even mobile phones. How did this happen? How did we go from multi-billion parameter models being solely in the realm of compute-rich tech companies to being run on the edge. The release of powerful open-source LLMs also kicked off a plethora of research into ways to optimize these models for inference. One particular avenue of research that has proven extremely fruitful involves the concept of quantization. In this blog post we are going to explain:
Language models, especially the large ones, are often trained using either 32-bit or 16-bit precision. What this means is that each parameter in the model is represented with either 32 or 16 bits. When we talk about a 32-bit model, it's stored using 32-bit floating point numbers. On the other hand, 16-bit models employ 16-bit floating point numbers or the 16-bit bfloat (brain-float, named after Google Brain, where the data type was first conceived) data type.
Now, why does this bit precision matter? Well, in terms of storage, a 32-bit model requires 4GB of memory for every 1 Billion parameters. Meanwhile, a 16-bit model halves that requirement to 2GB for the same number of parameters. Remember, this calculation only accounts for the storage of the model. Running the model in real-time requires additional memory. Moreover, while executing a large language model, temporary values called 'activations' can be quantized. This isn't predominantly to save memory but to harness the speed of 8-bit matrix multiplication operations that modern CPUs and GPUs support. Although this post sheds some light on activation quantization, our main focus will be on weight-only quantization.
Quantization is essentially a method to reduce the bit storage required for each model parameter. A prevalent approach is to bring it down to 8 bits per parameter. By this logic, a model with 1 Billion parameters would need just 1GB of memory. Translating this, a model with 7 Billion parameters (like a 'Llama' model) would necessitate at least 7GB of memory. Such a memory footprint is manageable on high-end laptops, but could challenge the capabilities of contemporary smartphones.
To put this into perspective, the most memory-endowed iPhones offer around 6GB, while the Google Pixel phones max out at approximately 8GB. So, if our goal is to facilitate large language models (LLMs) on mobile devices, we must push quantization boundaries. How? By venturing into even tinier bit-widths—7, 6, 5, 4, 3, 2, or even just a single bit per parameter. For instance, at 4-bit precision, our 7B parameter 'Llama' model would consume only 3.5GB, making it viable for today's smartphones. But delving into these lower bit-widths introduces complications. Striking the right balance among model quality, speed, and size becomes a nuanced challenge.
The quantization formula to quantize to int8 looks like this:
WQ=⌊MaxWF×255⌋
The Max parameter is a floating point number extracted from the weight to be quantized. 255 comes from the fact that we are using asymmetric quantization so we map all the values to a number between 0 and 255. If we were doing 4 bit quantization, this would end up being between 0 and 15.
Understanding the Impact of Quantization on Quality
When we delve into quantization, it's vital to recognize that it inherently reduces precision. In essence, by altering the model's weights through this process, there isn't a guarantee that the resulting weights will perform optimally. As a rule of thumb, there's often a performance dip post-quantization, especially when moving towards aggressive, low bit-widths. Large Language Models (LLMs) present a unique challenge in this arena. Empirical studies have revealed that LLMs often house extensive outlier features, meaning the model activations have certain values that are vastly different—often larger—than other values. During quantization, these outsized activations can become particularly vulnerable. Their sensitivity to quantization nuances means that aggressive methods might lead to significant quality loss. Thankfully, there are established best practices to navigate this terrain.
One approach to quantizing a model involves scaling and shifting its weight values so they fall between the range of 0 and 2^num-bits-1, then rounding down the weights to the closest integer value. This scale and shift process can be applied universally across an entire tensor, or alternatively, unique scale and shift parameters can be applied to specific weight groups.
For instance, it might be feasible to allocate separate scale and shift values for each matrix column. This strategy, known as "grouped quantization," underpins the 4-bit quantization methodologies employed by systems like GGML, exllama, bitsandbytes, and MLC. While grouped quantization offers considerable advantages, it does come with a minor downside—it slightly increases the bits-per-parameter required for storage.
If I store a 2 x 32bit values for every 64 4-bit numbers, then I effectively am effectively using 5 bits per parameter, not 4!
64(4×64+64)=5 bits per parameter
If we had an 8x8 matrix and wanted to quantize using a group-size of 4, then it would look something like this:
Each set of 4 values have their own max values calculated and are converted into 4-bit separately.
The other major direction of research is identifying the most important values in the LLMs, and somehow protecting them against the impacts of quantization. This is the approach adopted by a number of frameworks, including GPTQ, AWQ, LLM.int8(), and SpQR. All these approaches have different ways of identifying important weights, and different ways of ensuring that they are unaffected by quantization.
Our personal favourite at TitanML is AWQ. The authors identified that the important weights in a LLM are those that interact directly with the outlier features we spoke about earlier. If quantizing outliers has such a big impact on model quality, then surely there is some important signal locked up in the outliers that needs to be preserved. AWQ protects these weights by scaling the weights so that these so-called salient weights are protected against quantization errors by always being mapped losslessly to the largest value in the quantized range.
In the diagram above we have a schematic layout of a matrix multiplication. Each row of the matrix A is multiplied by the column of matrix B to create a single value in the output matrix, C. This is shown by the green values. It has been shown empirically that there are dimensions of A that are much larger than the others, these are the outlier features. These features form a column in matrix A, highlighted in red. This column identifies a row in matrix B, also highlighted in red. These are the salient weights that need to be protected during quantization.
It's crucial to discern when quantization is beneficial for your model, especially given its potential impact on accuracy. When you're designing vital downstream applications, here are some indicators suggesting that (weight-only) quantization might be a judicious choice for inference models.
The rationale here is pretty straightforward. When working with constrained computational capabilities, quantization can help. For instance, a Llama 13B model typically requires a GPU with at least 40GB of VRAM, such as Nvidia's A100 or A6000 GPU. But, by opting for 8-bit or 4-bit quantization, you could effectively run this on a more modest GPU like an A10 or even a T4. This can be a gamechanger for budding start-ups without high-end DGX setups or for applications run on edge data centres with legacy GPUs.
If your models are processing only a handful of requests (less than 10) simultaneously, it's probable that memory bandwidth bound. This signifies that the mere act of transferring weights from memory to computation units becomes a rate-limiting step. In such scenarios, quantization might not only mitigate memory constraints but could also expedite inference—even considering the added dequantization computations. However, this advantage might wane in high batch scenarios. Without meticulously optimized quantization kernels, the inference process could decelerate markedly in these compute-intensive, high-batch situations. Thus, for localized LLMs processing individual requests or any application that requires limited simultaneous inferences, the dual benefits of enhanced speed and the feasibility of using modest GPUs make a compelling case.
Assessing the performance of large language models is inherently challenging. Many developers resort to a rather subjective method—simply scrutinizing the outputs and deeming them "satisfactory" based on a visual check. While it's feasible to gauge perplexity scores post-quantization, such metrics aren't always reflective of subsequent application performance. Therefore, if you have robust evaluation measures at your disposal—whether that's classification metrics, multi-choice question assessments, or human evaluators—venturing into quantization becomes more defensible. With these tools, you can gain a clearer perspective on the implications for downstream application efficacy.
At TitanML we have built the Takeoff Server - our attempt at abstracting away the difficult and time consuming parts of LLM deployment and inference. The Takeoff Server includes 4-bit calibration using the same AWQ method mentioned above, and 4-bit inference for both GPU and CPU inference.
TitanML enables machine learning teams to effortlessly and efficiently deploy large language models (LLMs). Their flagship product Takeoff Inference Server is already supercharging the deployments of a number of ML teams.
Founded by Dr. James Dborin, Dr. Fergus Finn and Meryem Arik, and backed by key industry partners including AWS and Intel, TitanML is a team of dedicated deep learning engineers on a mission to supercharge the adoption of enterprise AI.
The release of various open-source Large Language Models (LLMs) this year has democratised the access to AI and its associated technologies. Colossal models like the Llama-2 70B or even the Falcon 180B represent incredible opportunities for those who can harness their power.
While anyone can certainly download a copy of these models, numerous AI enthusiasts face many barriers tapping into the power of these powerful models. These barriers may seem daunting; not only would inferencing these models require huge amounts of compute power, deploying these models is also a complicated affair.
This is why we've built the Titan Takeoff Server: to break down these barriers to AI adoption and allow everyone to deploy and tap into the power of these LLMs easily, so they can focus on building the AI-powered apps they care about.
Titan Takeoff Server takes care of the difficulties of deploying and serving large language models, so you don't have to spend endless hours worrying about setting the right configurations and compatibility with your deployment environment.
With a few simple commands, you'll be able to deploy your LLMs to anywhere you want, be it on your local machine or on the cloud. Check out our guides showing you how to deploy them on AWS, Google Cloud and Kubernetes.
In an era where data privacy and proprietary models are paramount, Titan Takeoff Server stands out, allowing you to retain full ownership and control over your data, ensuring that sensitive information remains on-premises and is never exposed to third-party vulnerabilities.
Inferencing LLMs can be very compute intensive, so we've developed the Titan Takeoff Server to be memory efficient, using state of the art quantisation techniques to compress your LLMs. This also means that you will be able to support much larger models without upgrading your existing hardware.
To get set up with the Titan Takeoff Server, there are only two commands that you need to run. The first command installs the Iris CLI, which interfaces with the Titan Takeoff Server.
pip install titan-iris
The second and final command is the takeoff command, which optimises and loads your model before starting up a server. Note that you'll have to specify the model name as well and will be given a choice of a few optional parameters.
iris takeoff --model <model_name> # Specify model name --device cuda # Select CPU or GPU(cuda) --port 8000 # Specify port number for server --token <token> # Needed for Llama-2 models
With the Titan Takeoff Server running, our model is ready to be inferenced on-demand, so it's time to start building apps.
There are two main ways your app can interface with your model: through Titan Takeoff Server's own inference endpoints or the integration with LangChain.
Titan Takeoff Server exposes two main inference endpoints: generate and generate_stream. If you want your response to be streamed back gradually, you should use the generate_stream endpoint, otherwise your response will only be returned as a whole chunk when it is ready. You can also specify your desired generation parameters, such as temperature, maximum token lengths etc.
Titan Takeoff Server also has an integration with LangChain, allowing you to access your model through LangChain's interface. This makes it easy to access a wealth of different tools and other integrations that may be needed for downstream processing. Click here to view our docs relating to the LangChain Integration.
What kind of apps can you build with Titan Takeoff Server?
During our dogfooding exercise, the TitanML team built several apps that showcased the breadth of what you can build with the Titan Takeoff Server:
App to generate Knowledge Graphs from news articles
The possibilities are endless with what you can create with LLMs. And if you're still struggling for ideas, here are some examples to stoke your imagination:
To power a chatbot with Titan Takeoff Server, begin by deploying a conversational model, possibly a variant of GPT or Falcon optimised for dialogue. Titan simplifies this deployment process by allowing you to load and serve the model locally. Once set up, you can integrate this server with your chat application's backend, ensuring efficient handling of user requests.
By coupling real-time processing capabilities of Titan with a user-friendly UI, you'll have a chatbot that can address user queries, engage in meaningful interactions, and provide context-aware solutions, all powered locally without the need for external APIs.
Content creators often struggle with writer's block or need assistance in refining their drafts. Using Titan Takeoff Server, you can deploy a language model tailored for content generation or enhancement. Integrate this with platforms like CMS or blogging tools, where users can input topic prompts or existing drafts. The Titan Takeoff server can suggest content drafts, refine sentences, or even generate catchy headlines in real-time. By doing this, you offer a dynamic writing assistant that not only aids in creating content but also ensures it's engaging and well-structured, all while ensuring data remains local and private.
Modern learning experiences can be augmented with AI-powered tutors. Using Titan Takeoff Server, deploy a model trained for educational explanations. You can develop an interactive platform where students can input their questions or topics of confusion. Their queries can be sent to the Titan Takeoff Server, which then consults an educational model to produce coherent, easy-to-understand explanations. Such an app can be a boon for learners, providing them instant access to clarifications, supplementary content, and personalized learning resources, all while ensuring the data remains on-premises, preserving student privacy.
Bonus: Retrieval Augemented Generation with Vector Databases
If you have deployed an extremely large model unsuitable for fine-tuning or constantly require up to date information, you can consider implementing Retrieval Augmented Generation (RAG). RAG is a technique that combines the strengths of large pre-trained models with external knowledge databases. Instead of solely relying on the model's internal knowledge, which might be outdated or limited, RAG queries an external database in real-time to fetch relevant information or context before generating a response.
To enhance the accuracy of your results, as well as the speed of retrieval, you can even consider using a vector databases such as Weaviate or Pinecone. Vector databases enable rapid, real-time semantic searches, allowing systems to retrieve information based on conceptual similarity rather than just exact matches. This ensures faster, more contextually relevant results, bridging the gap between raw data and genuine understanding.
This approach can be particularly useful for chatbots in dynamic sectors where current data is paramount, such as finance, news, or technology trends. With Titan Takeoff Server's optimized inference capabilities, incorporating RAG can lead to more informed, up-to-date, and contextually aware responses, elevating the overall user experience of your conversational AI application.
In all of these applications, Titan Takeoff Server acts as the local powerhouse, offering real-time, efficient, and secure model inferencing, which can produce transformative solutions, when combined with tailored models and thoughtful user experience design. We can't wait to see what you choose to build!
Its has never been more exciting, rewarding, and challenging to be a data scientist. Advancements in foundation models have enabled new applications to be built in text, image, and multimodal domains. However this has come with a cost. The infrastructural challenges of working with large foundation models are larger than they have ever been. Data scientists are increasingly asked to become experts in building and managing the infrastructure needed to train and serve large foundation models, while also deeply understanding and modelling the data in front of them.
It is going to be increasingly important for data scientists to be equipped with the right tools, so they can manage the growing infrastructural demands of modern deep learning while still being able to focus on the core skill set of data science. DeterminedAI and Titan Takeoff are two such tools which take a data scientist the full distance training to model serving.
In this article we will show how to fine tune a generative model (GPT2) on your own data using Determined, and then efficiently serve it on GPU with int8 quantization using Takeoff.
To demonstrate how to use the Takeoff server with models trained using Determined we will walk through an example. We will be doing the following:
Training a GPT2 model with DeterminedAI
Downloading the saved checkpoint and converting it to a format that Takeoff can use.
Deploying the model with Titan Takeoff.
Both DeterminedAI and Titan Takeoff are easy to use and don’t require a lot of code or configuration to get started. The trickiest step is mapping the weights that are downloaded by Determined to a format that Takeoff accepts. Let's delve into an end-to-end tutorial for transitioning from DeterminedAI to Titan Takeoff.
This will extract the contents to a folder called /language-modeling . Navigate to the folder and there should be a config file: /language-modeling/clm_config.yaml.
Be sure to set the correct number of GPUs for your machine in clm_config.yaml
resources: slots_per_trial: <your number of gpus>
To initiate the fine tuning job, navigate to the folder with the yaml and run the experiment create command:
cd language-modeling det experiment create -f clm_config.yaml .
After the task is successfully dispatched we can view all the training info and stats on the same dashboard as before at localhost:8080. This is also where we track the training progress and view other relevant details. After this, just wait for the training to complete.
Now that training is done we need to download to the model.
Navigate to the Checkpoints Under your experiment:
Record the UUID for the checkpoint you would like to download.
Use the following command to download the model:
det checkpoint download <your_checkpoint_model_uuid>
Converting to the HuggingFace Model Format
Once downloaded, the model can be found in the checkpoints folder, identified by its unique UUID. The model weights are saved in the state_dict.pth file. Our next task is to convert this model into the HuggingFace format. This is done by initializing a model using the HuggingFace transformers package, loading the weights into the model class, and then saving it to a directory.
Here's a script to guide you through this process:
import torch from transformers import GPT2LMHeadModel, GPT2Tokenizer checkpoint = torch.load('checkpoints/<your_checkpoint_model_uuid>/state_dict.pth') model_state_dict =dict(checkpoint['models_state_dict'][0]) # Remove unexpected keys from state_dict_as_dict unexpected_keys =[ "transformer.h."+str(i)+".attn.bias"for i inrange(12) ]+[ "transformer.h."+str(i)+".attn.masked_bias"for i inrange(12) ] for key in unexpected_keys: if key in model_state_dict: del model_state_dict[key] model = GPT2LMHeadModel.from_pretrained('gpt2')# Instantiate GPT-2 model model.load_state_dict(model_state_dict)# Load your weights tokenizer = GPT2Tokenizer.from_pretrained('gpt2')# Instantiate tokenizer model.save_pretrained('gpt2_hf')# Save model to gpt2_hf tokenizer.save_pretrained('gpt2_hf')# Save tokenizer to gpt2_hf
We need to remove some weights since the model used by Determined has a different set of weights as the Huggingface implementation of GPT2.
Once the model and tokenizer are saved in the 'gpt2_hf' directory, the conversion phase is complete!
Deploying the fine-tuned model on the Titan Takeoff server is easy. Begin by moving or copying the model's folder to ~/.takeoff_cache. On a Linux system, this can be accomplished with:
cp -r gpt_hf ~/.takeoff_cache
Deploy with Titan Takeoff
To deploy your model, simply use the following command:
iris takeoff --model gpt_hf --device cuda
The --device flag is optional. If you omit this argument, the model will run on the CPU by default. Once executed, you'll have an optimized GPT-2 model running on your local server.
Using the takeoff server you have the option to deploy using a range of quantization types, from bfloat16 to int4, on cpu and gpu, optimized for throughput or latency as needed. This makes it easy to take advantage of all the hardware available to data science teams, and be able to build high performance, scalable applications on top of LLMs.
Model Inference
You can inference the model using the API:
curl http://localhost:8000/generate_stream \ -X POST \ -N \ -H "Content-Type: application/json" \ -d '{"text":"List 3 things you can do in London"}'
To wrap things up, we have seen the seamless integration of DeterminedAI and Titan Takeoff allows for a smooth transition from model training to deployment. With a three-phase process that involves model training, conversion, and deployment, users can easily transition from a DeterminedAI-trained model to being fully operational with Titan Takeoff. Keep this guide handy, and remember: from training wheels to full throttle, your model's journey has never been this streamlined! 🚀






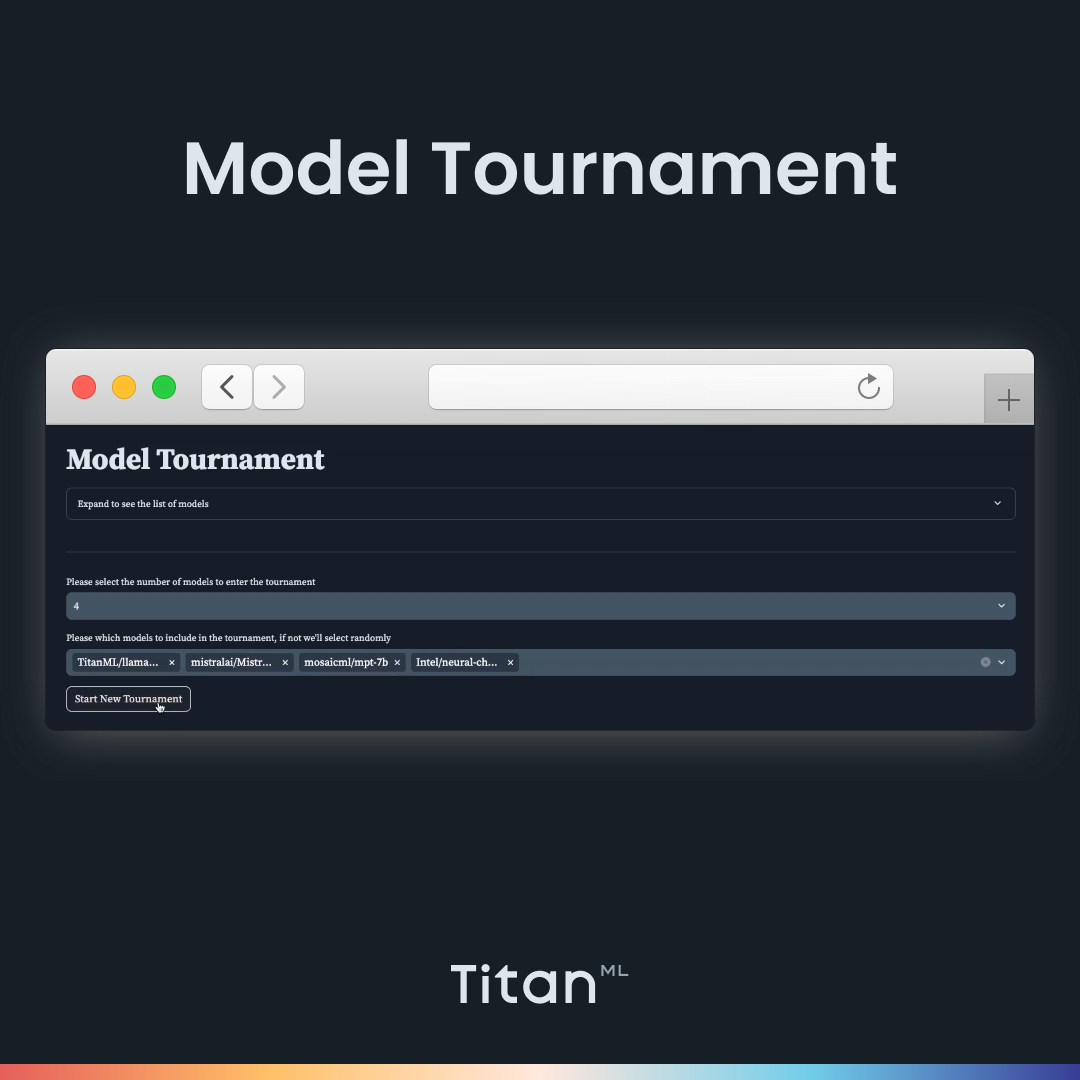

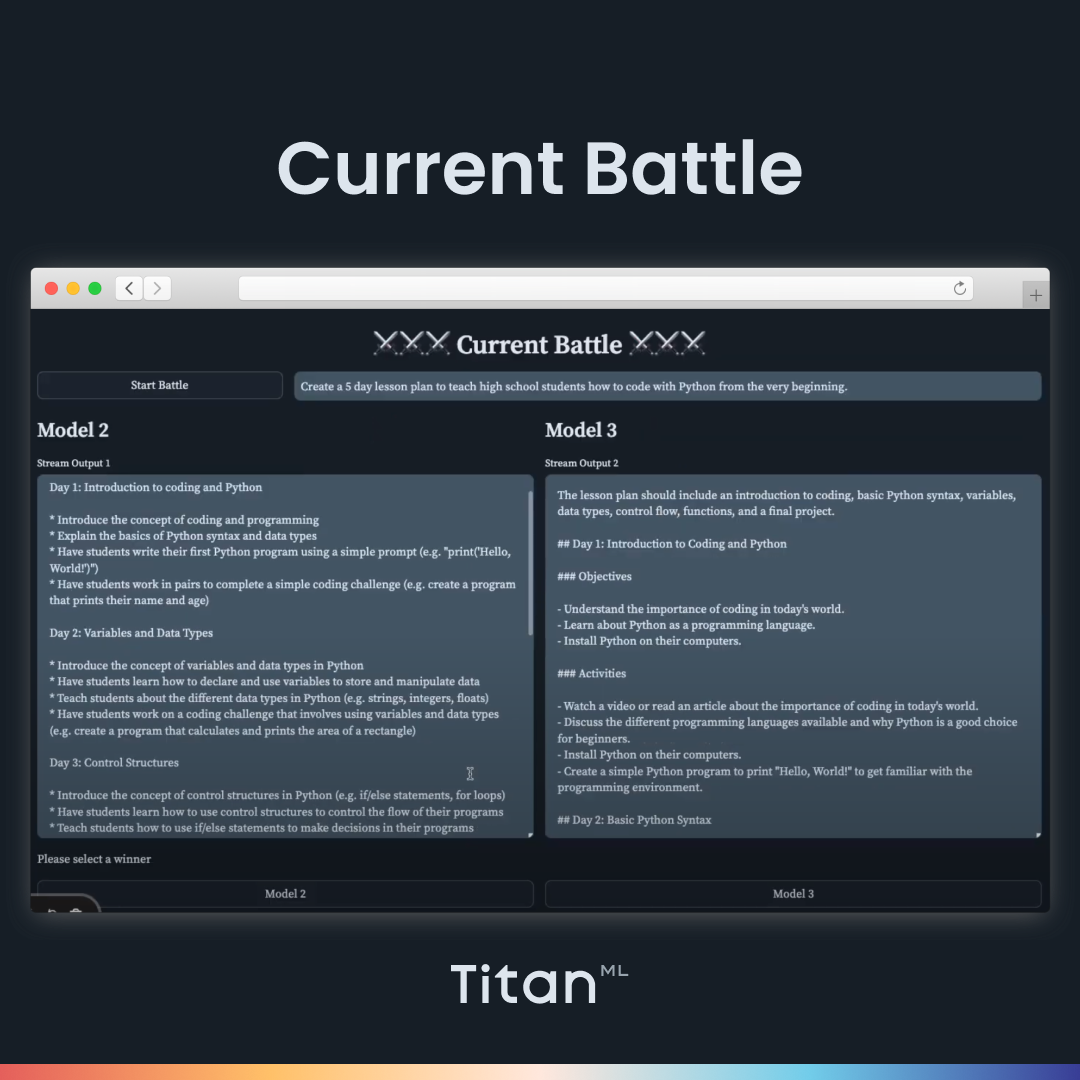
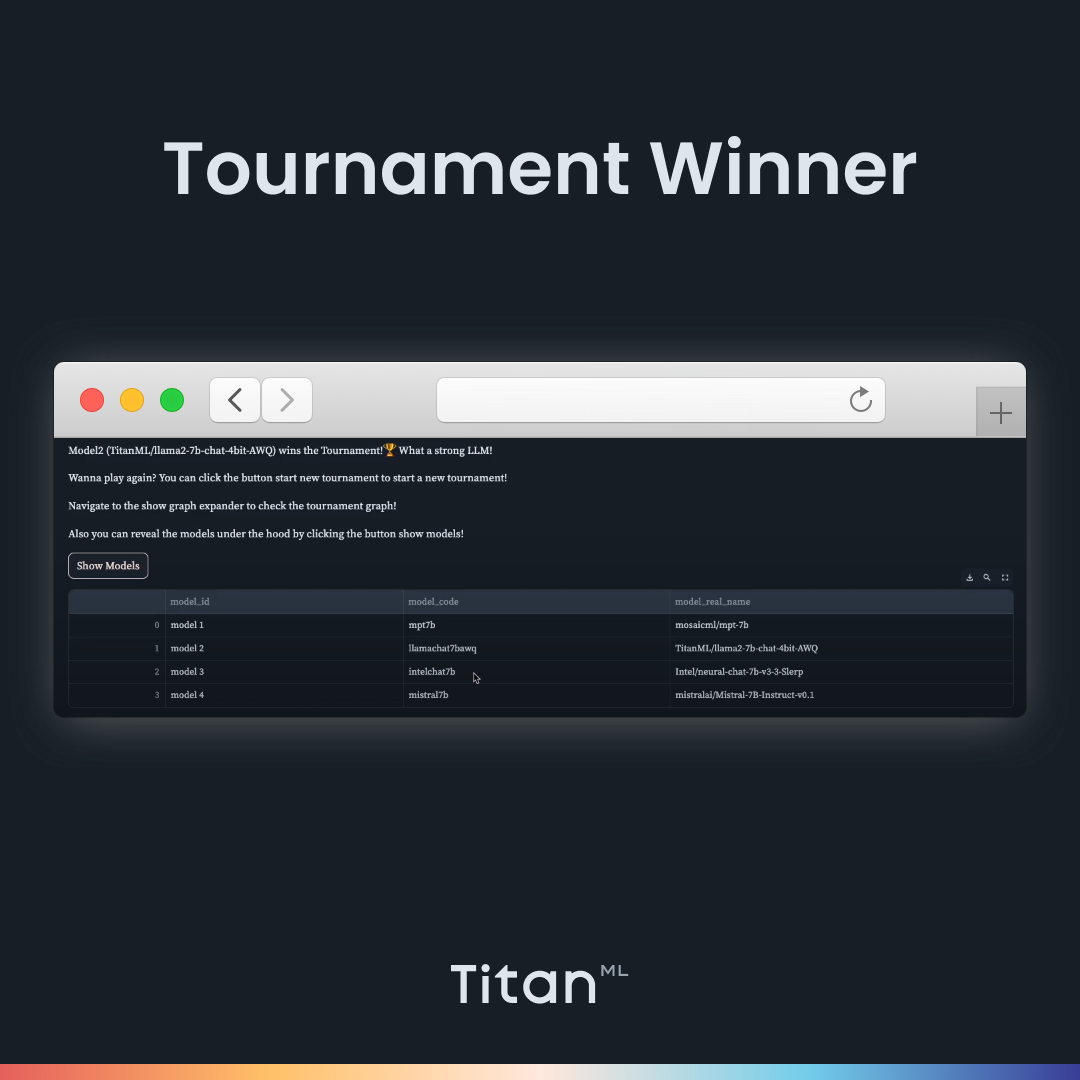



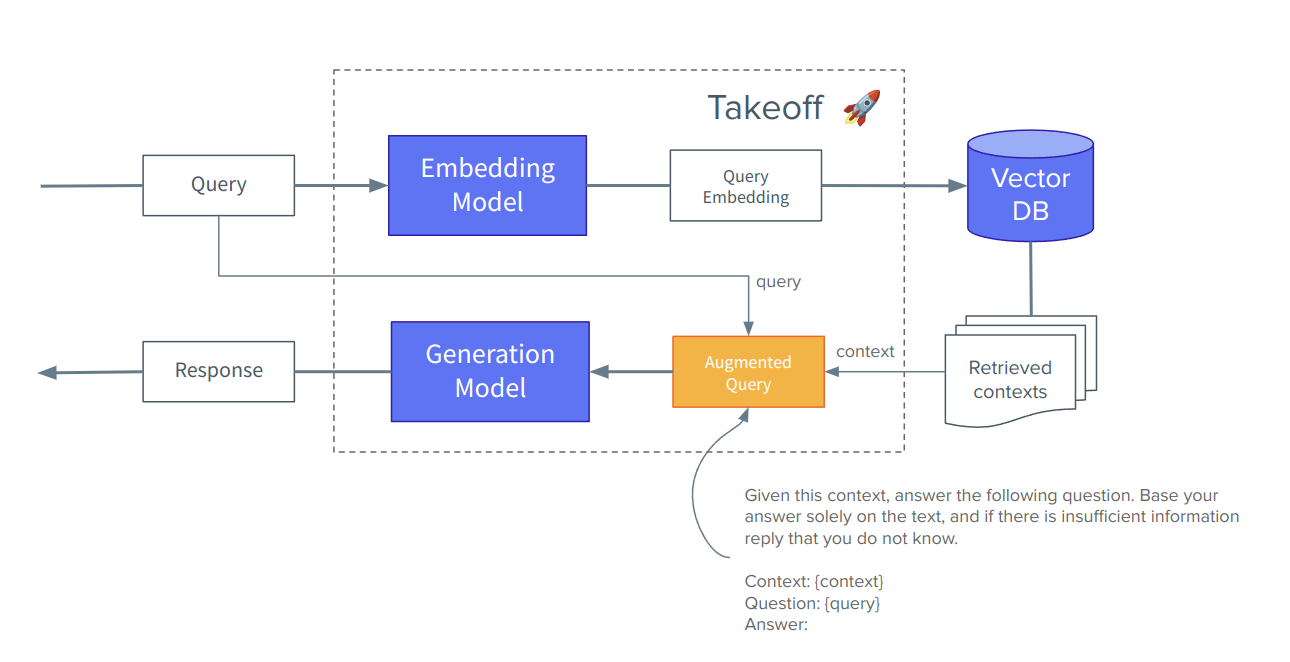
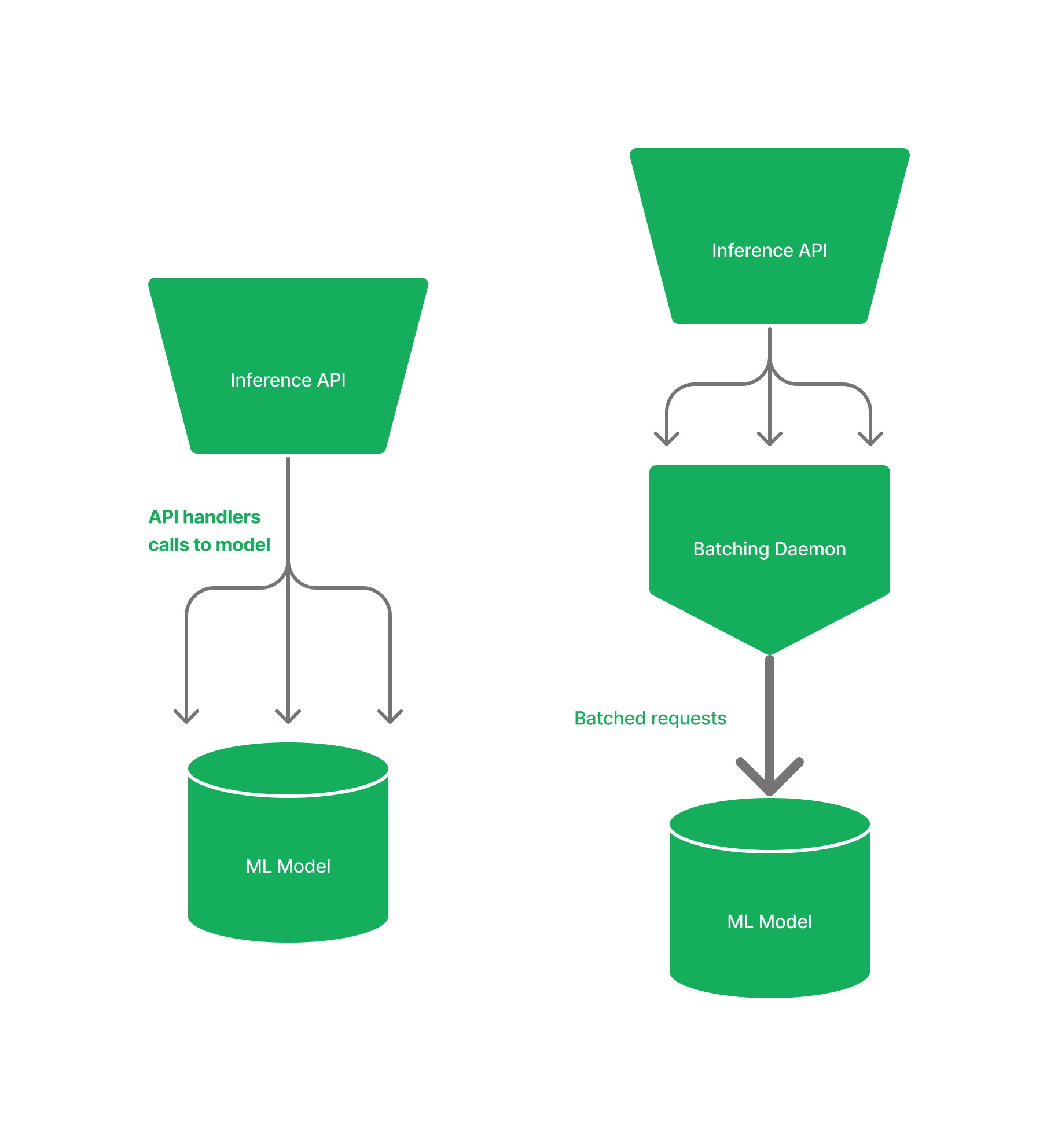
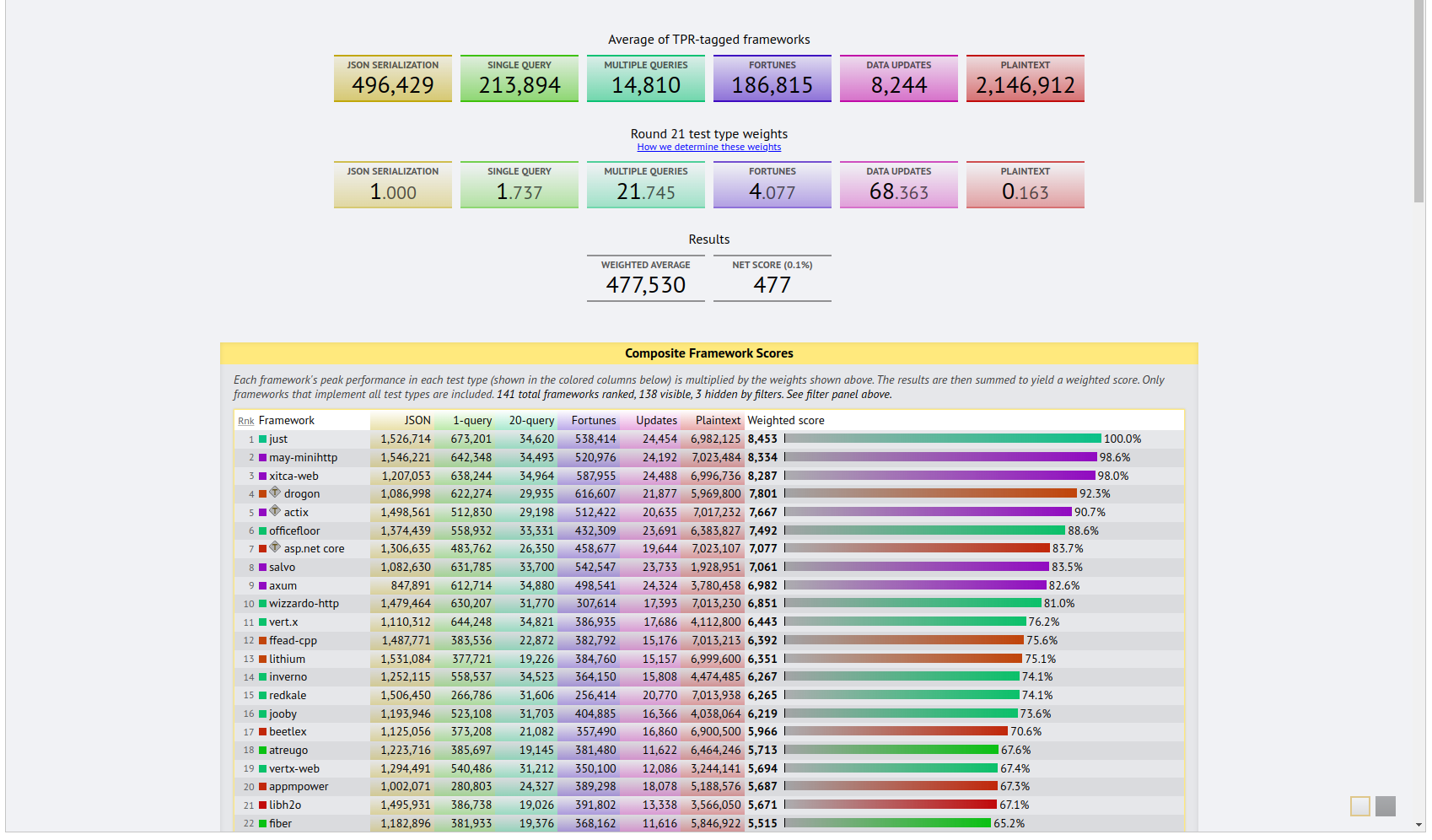
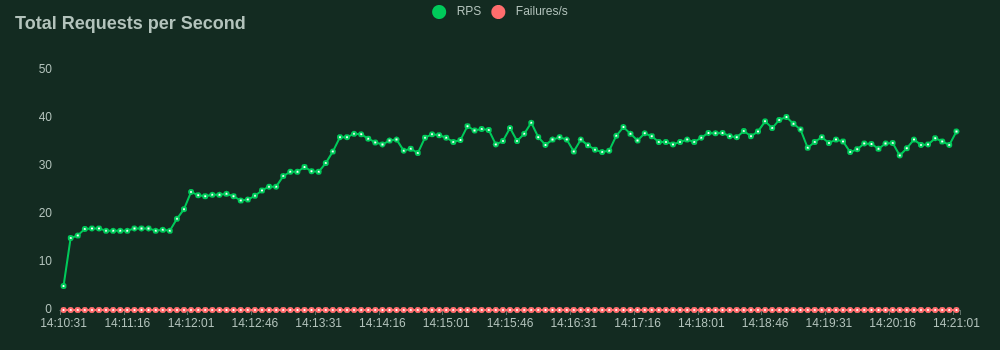
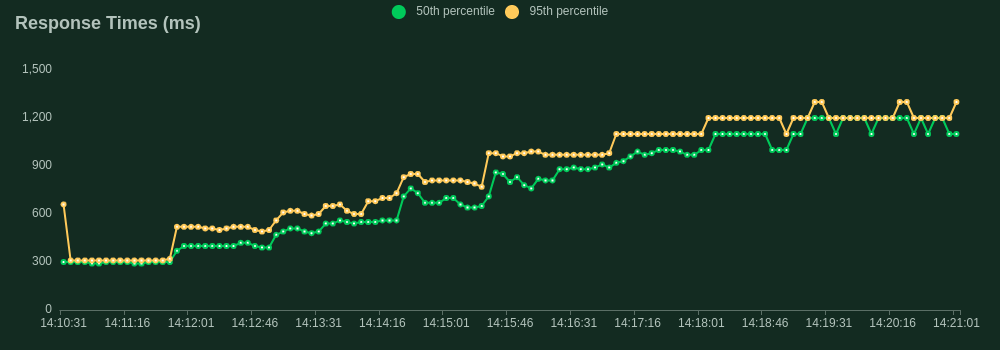
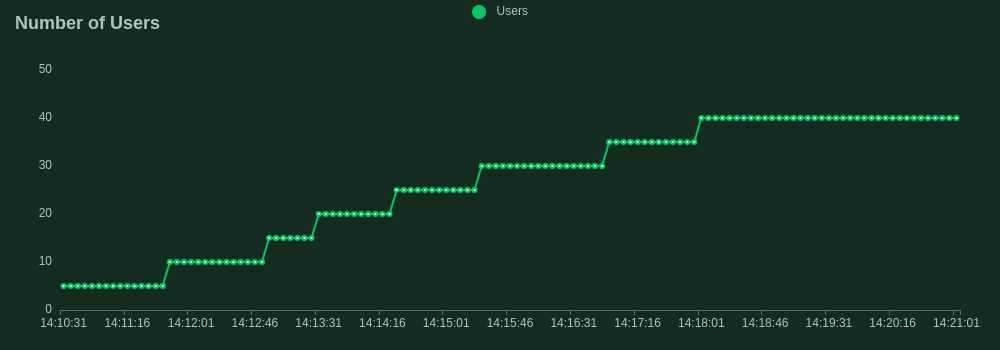
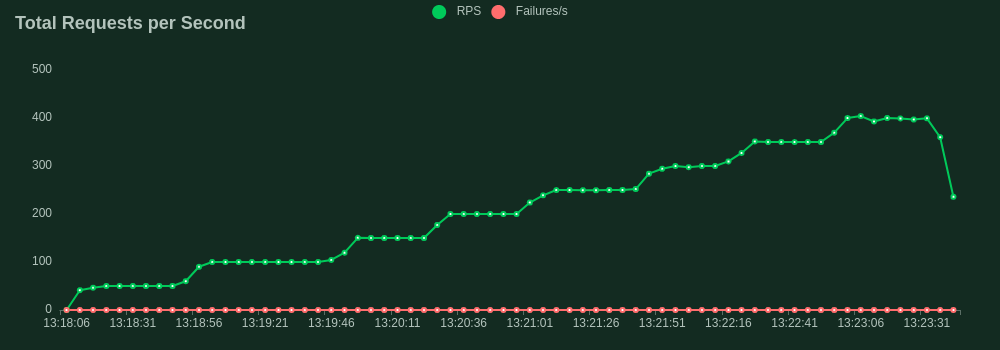
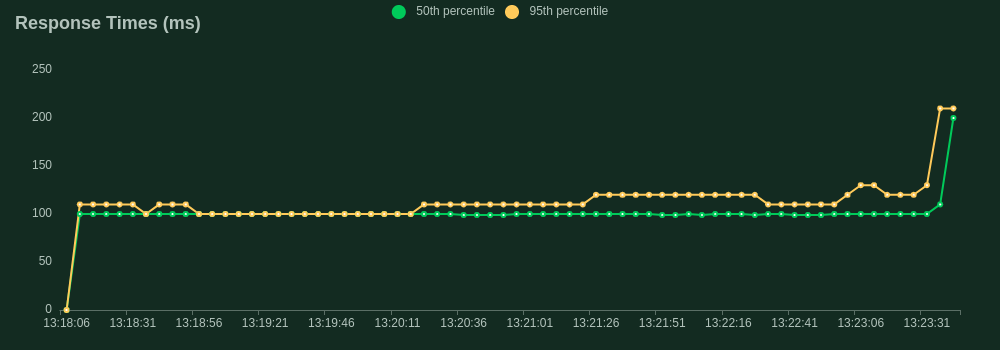
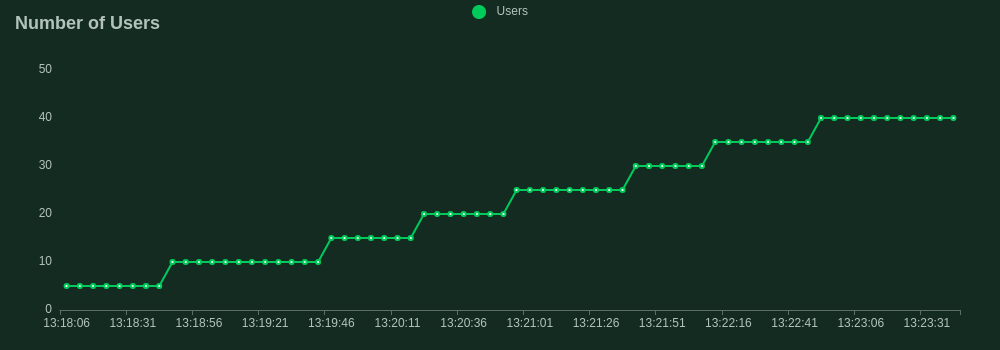
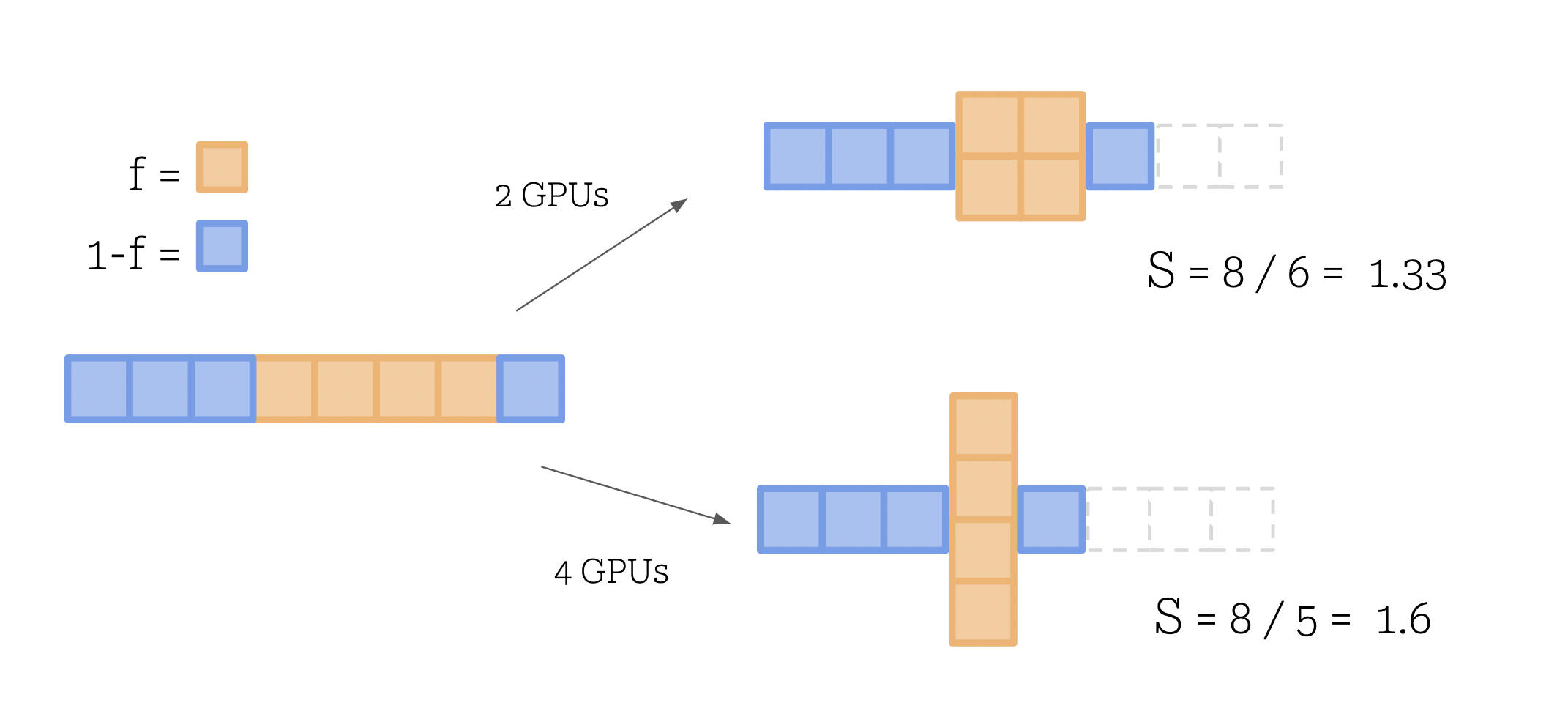
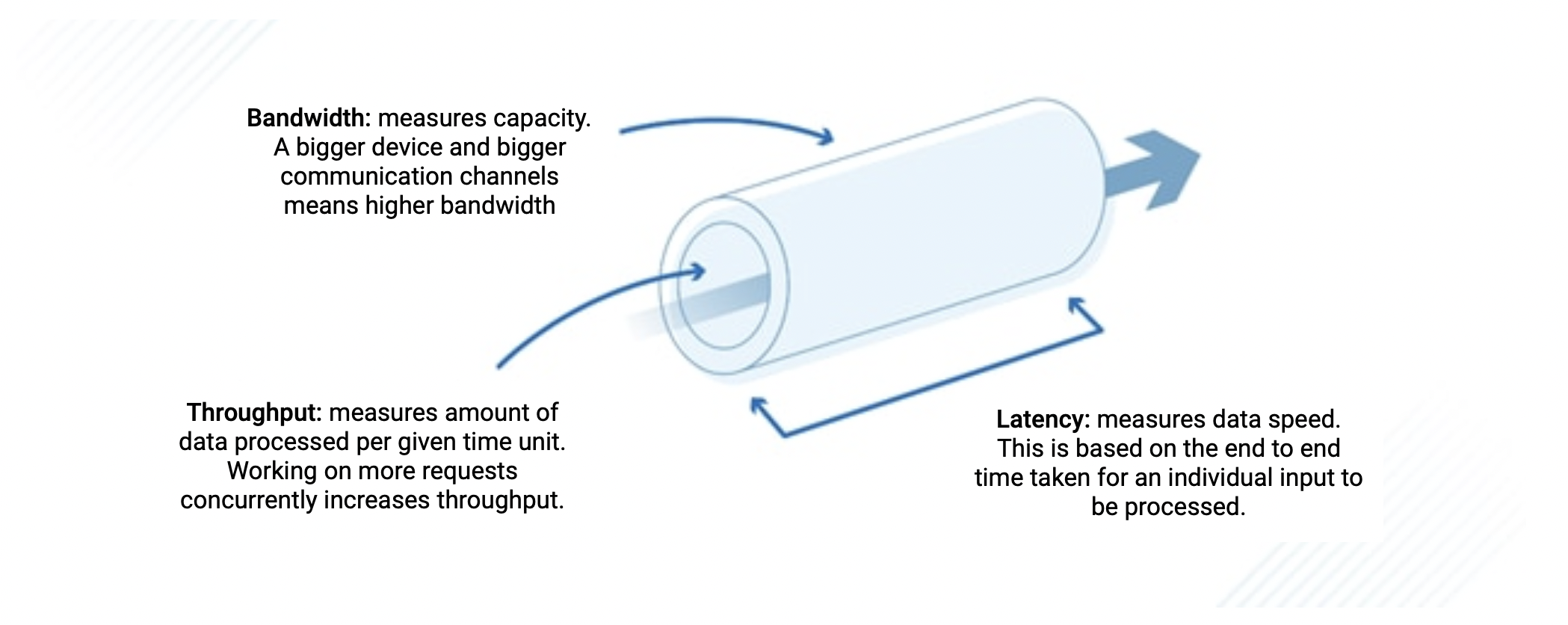
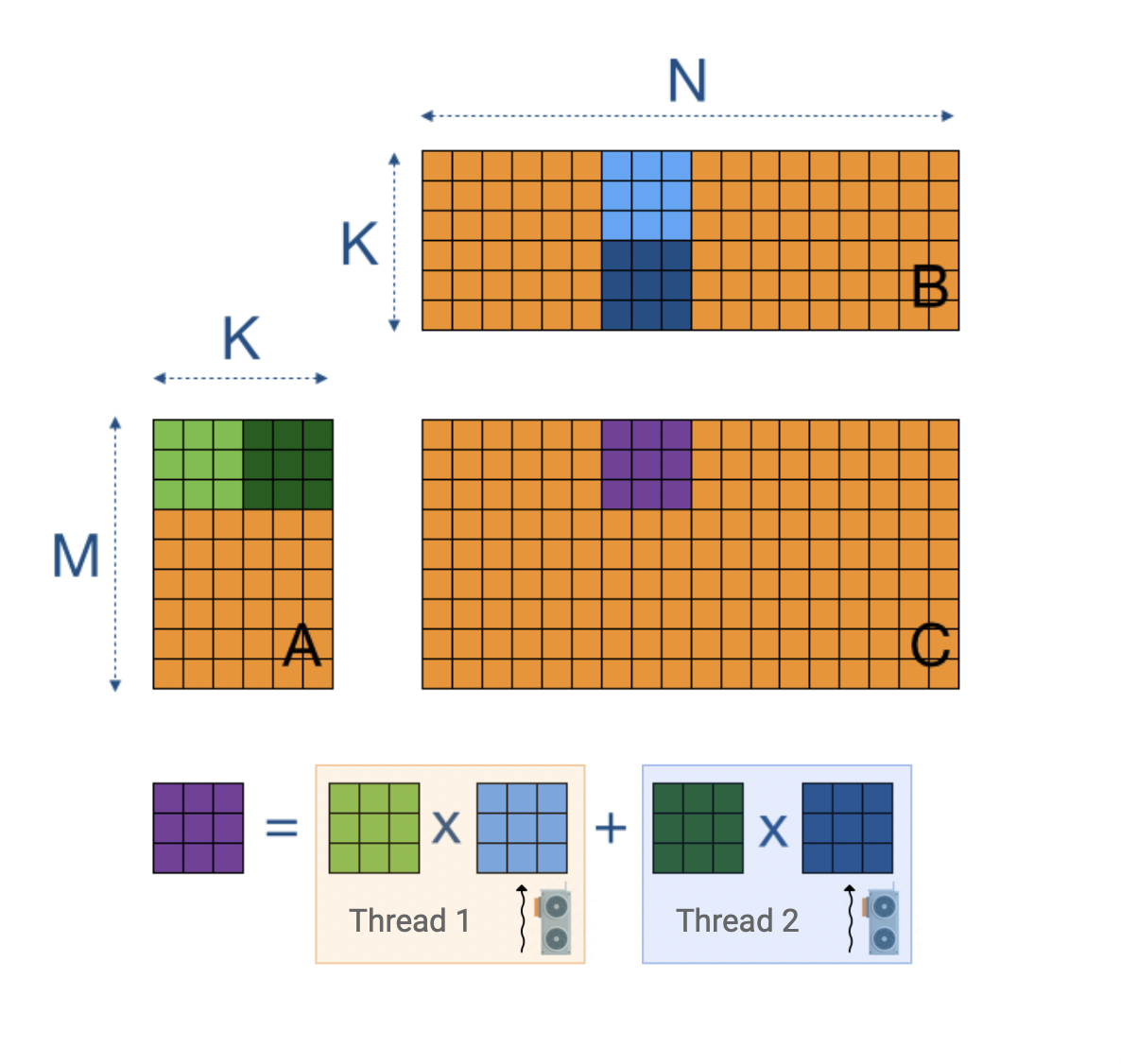
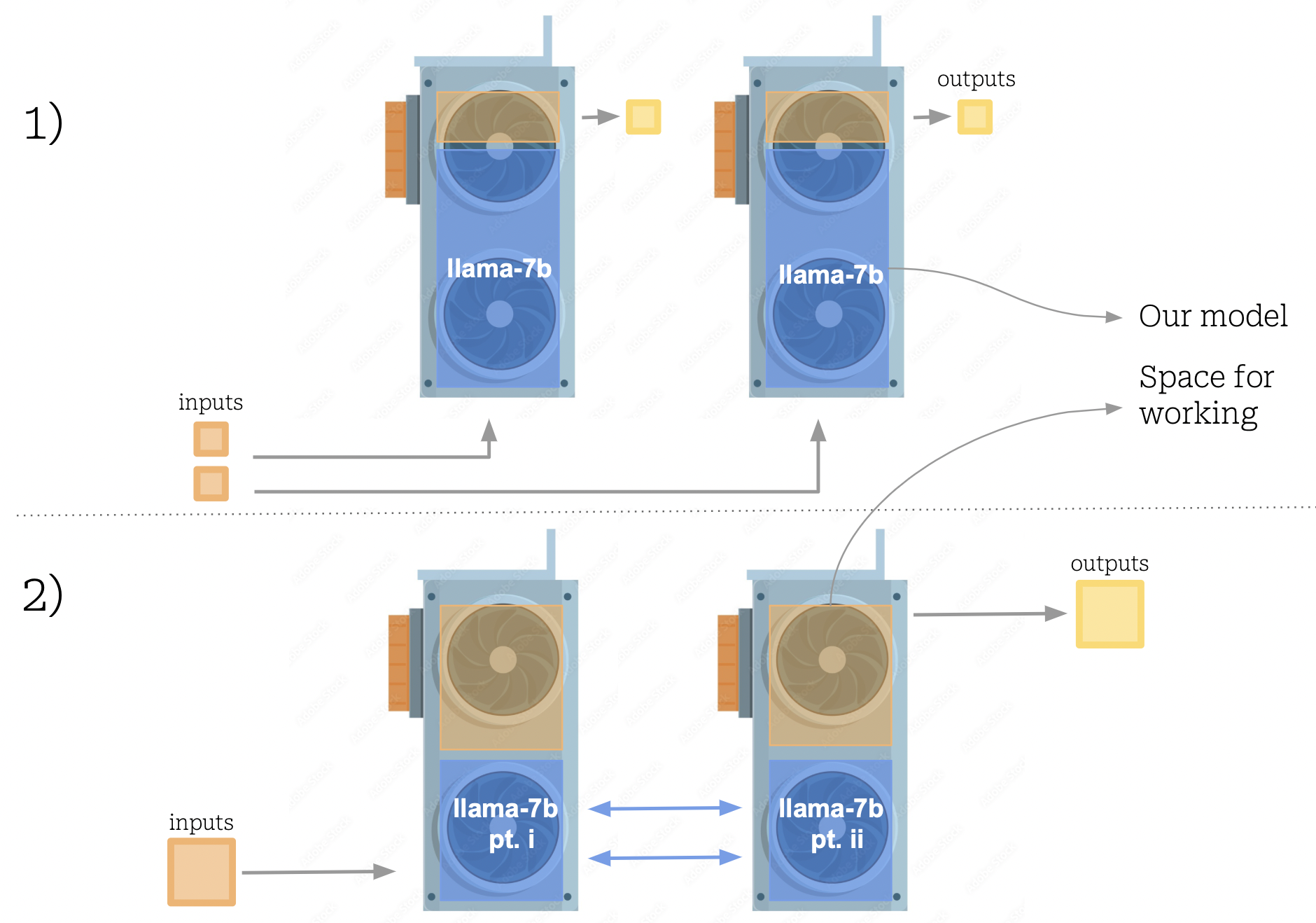
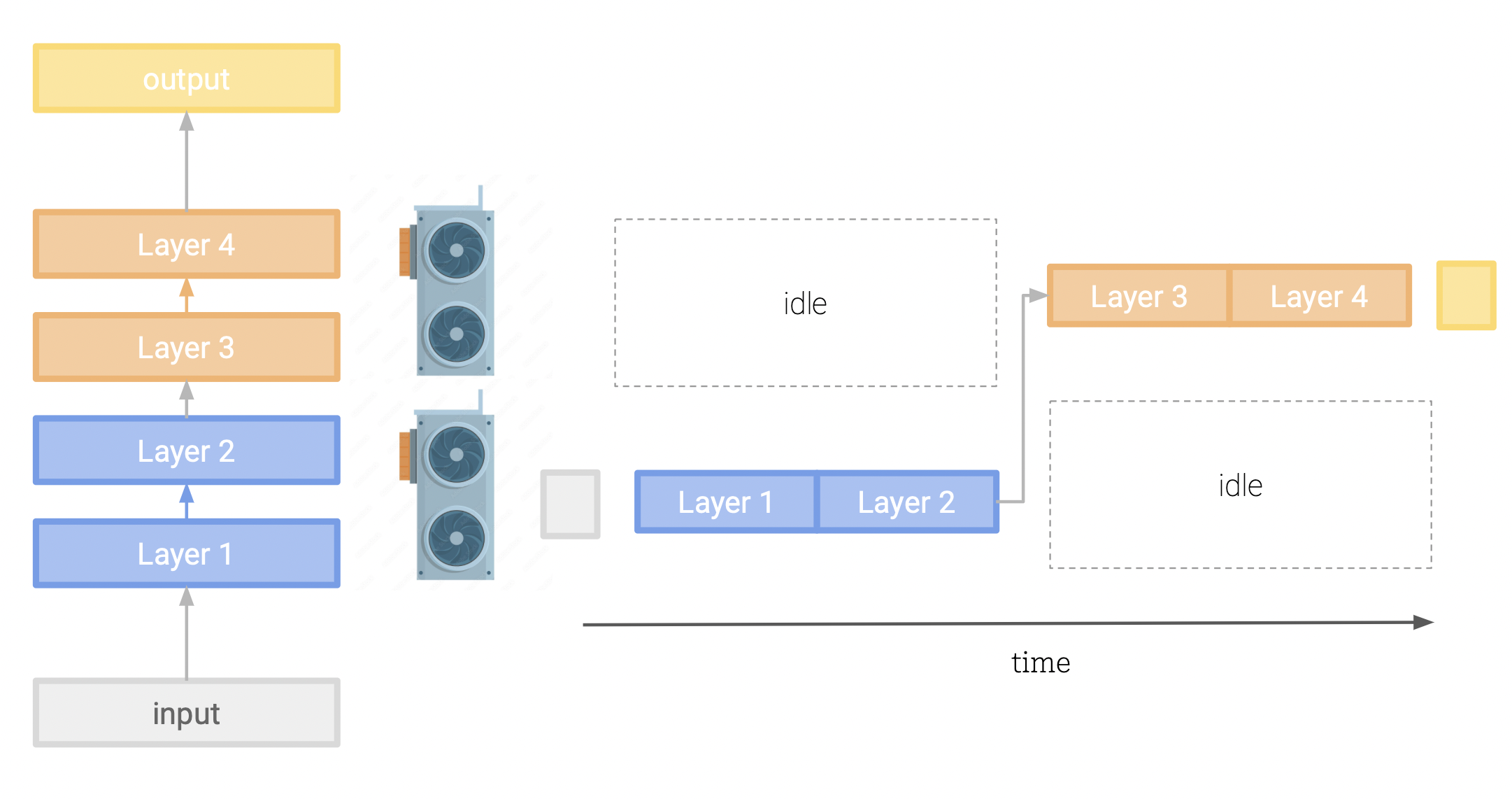
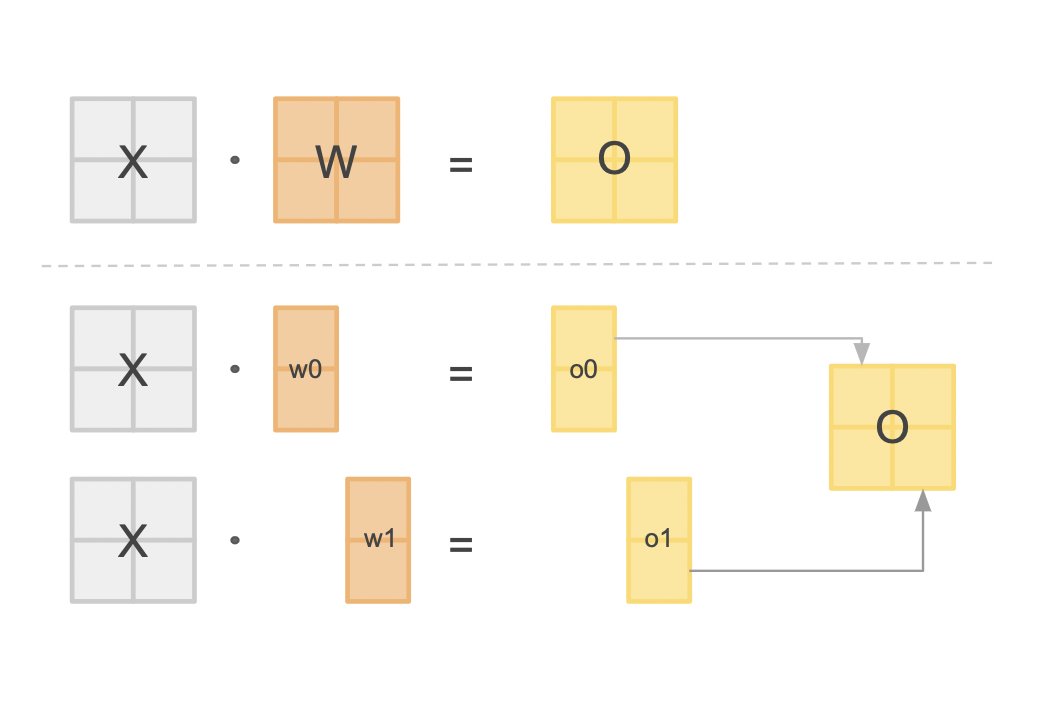
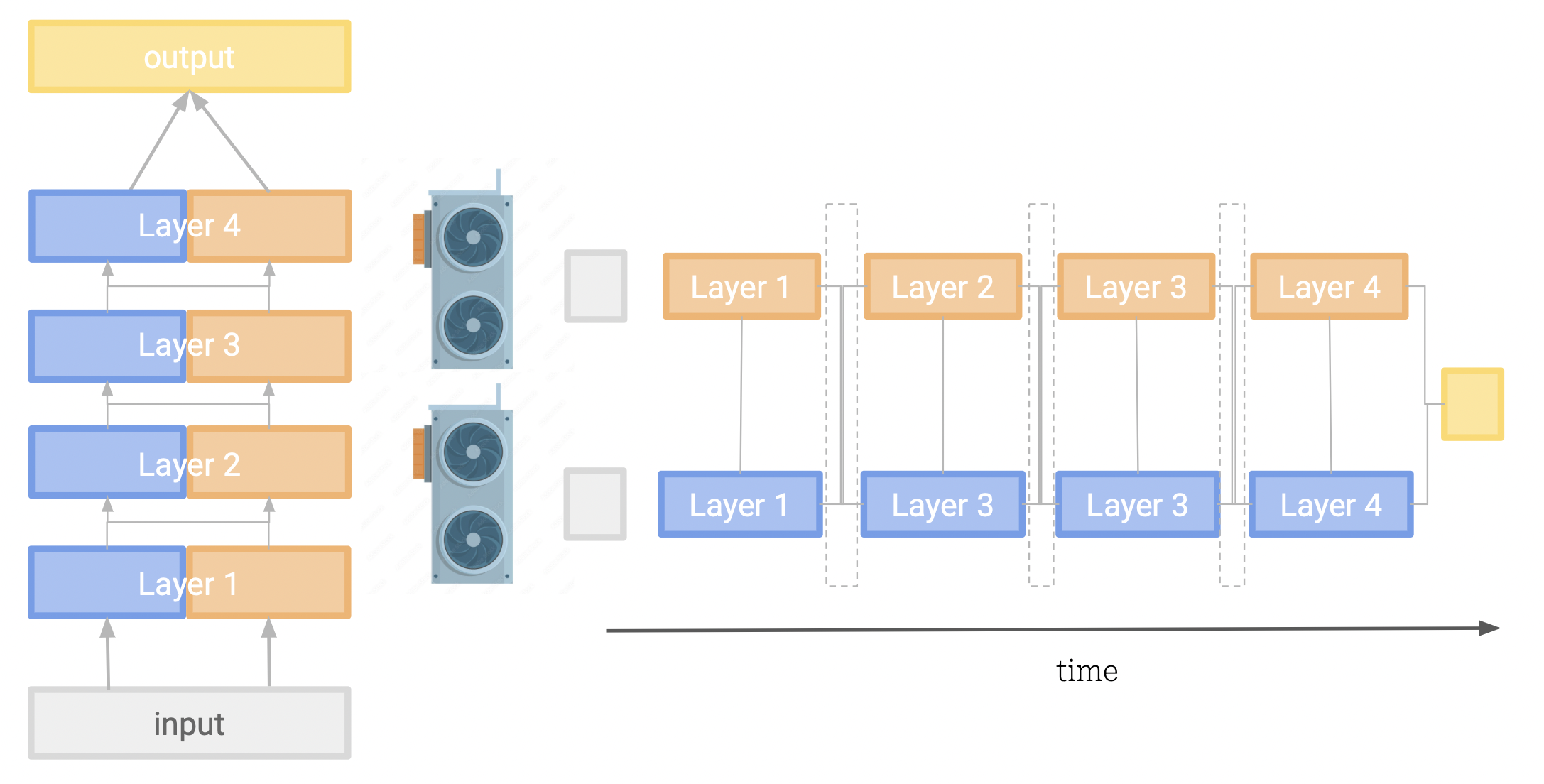
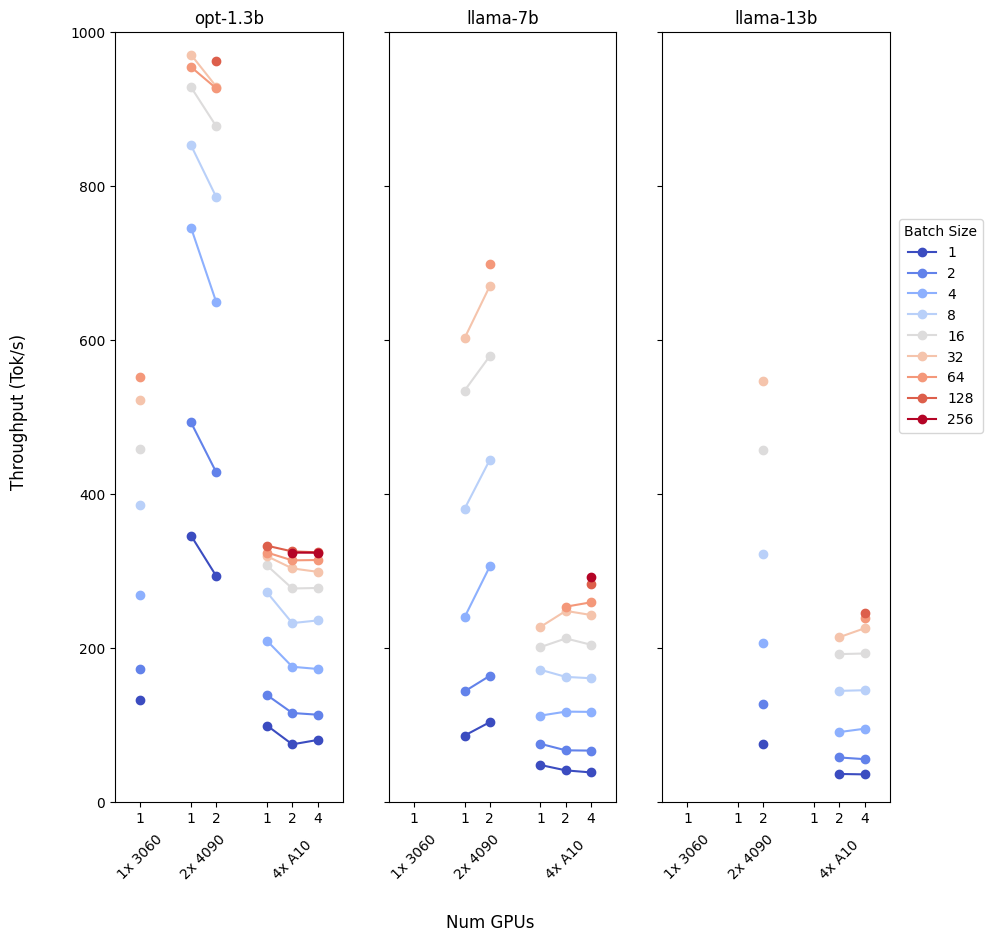

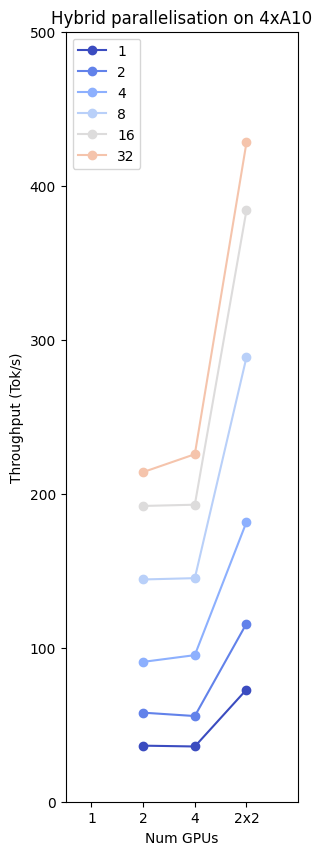

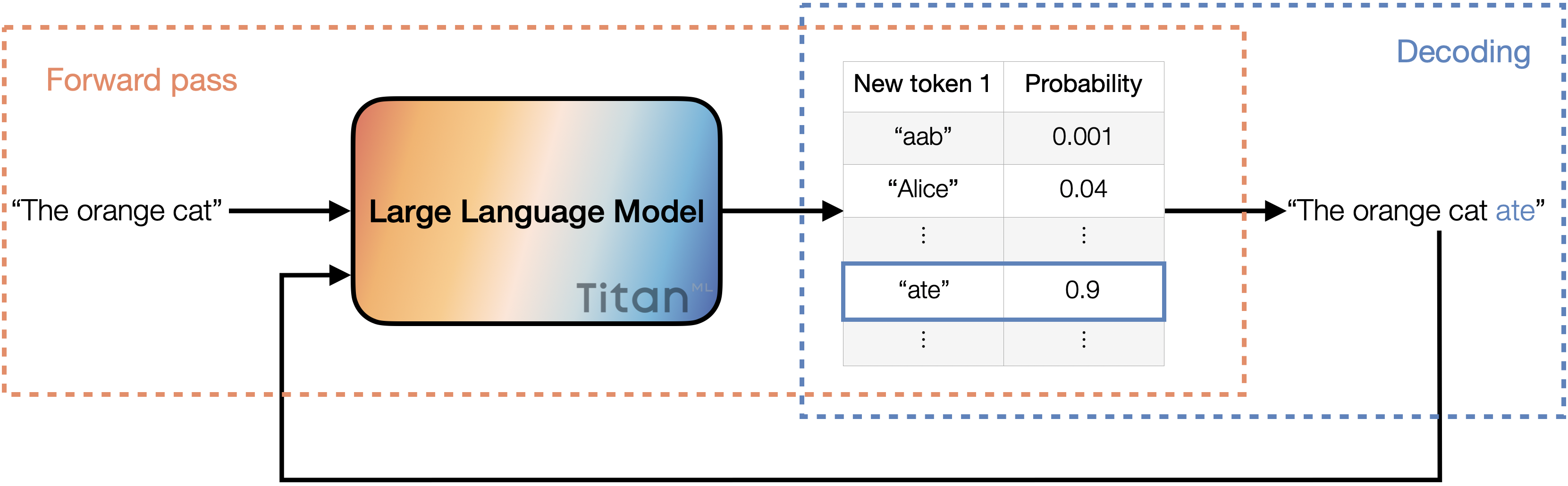 An illustration of the text generation process. The input is fed into the large language model, where it undergoes the forward pass. The model returns a list of potential tokens with their associated probabilities. Then, we decode by selecting the token with the highest probability and appending it to the input. This updated input then goes through the entire process once more.
An illustration of the text generation process. The input is fed into the large language model, where it undergoes the forward pass. The model returns a list of potential tokens with their associated probabilities. Then, we decode by selecting the token with the highest probability and appending it to the input. This updated input then goes through the entire process once more. A full text generation process, where the large language model iteratively generates a full sentence with the given input.
A full text generation process, where the large language model iteratively generates a full sentence with the given input.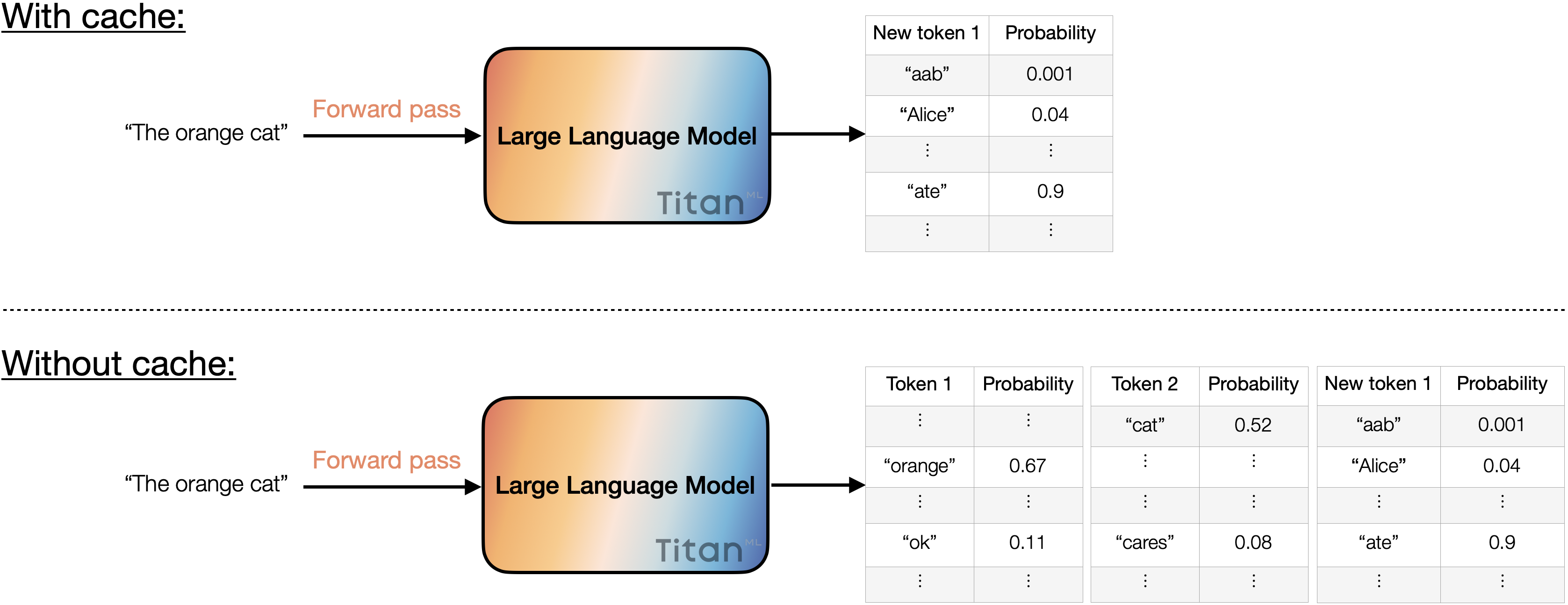 Caching reduces the redundant computation by skipping tokens that have already been processed, focusing solely on calculating probabilities for potential new tokens. In contrast, disabling caching entails computing probabilities for all tokens, including the input tokens.
Caching reduces the redundant computation by skipping tokens that have already been processed, focusing solely on calculating probabilities for potential new tokens. In contrast, disabling caching entails computing probabilities for all tokens, including the input tokens.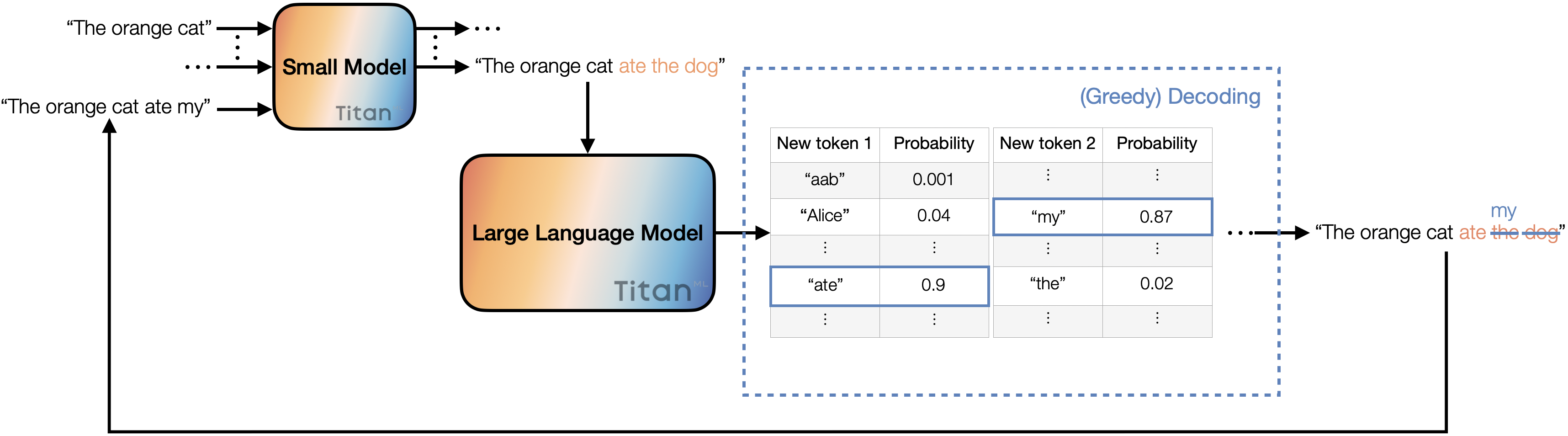 Speculative decoding.
Speculative decoding.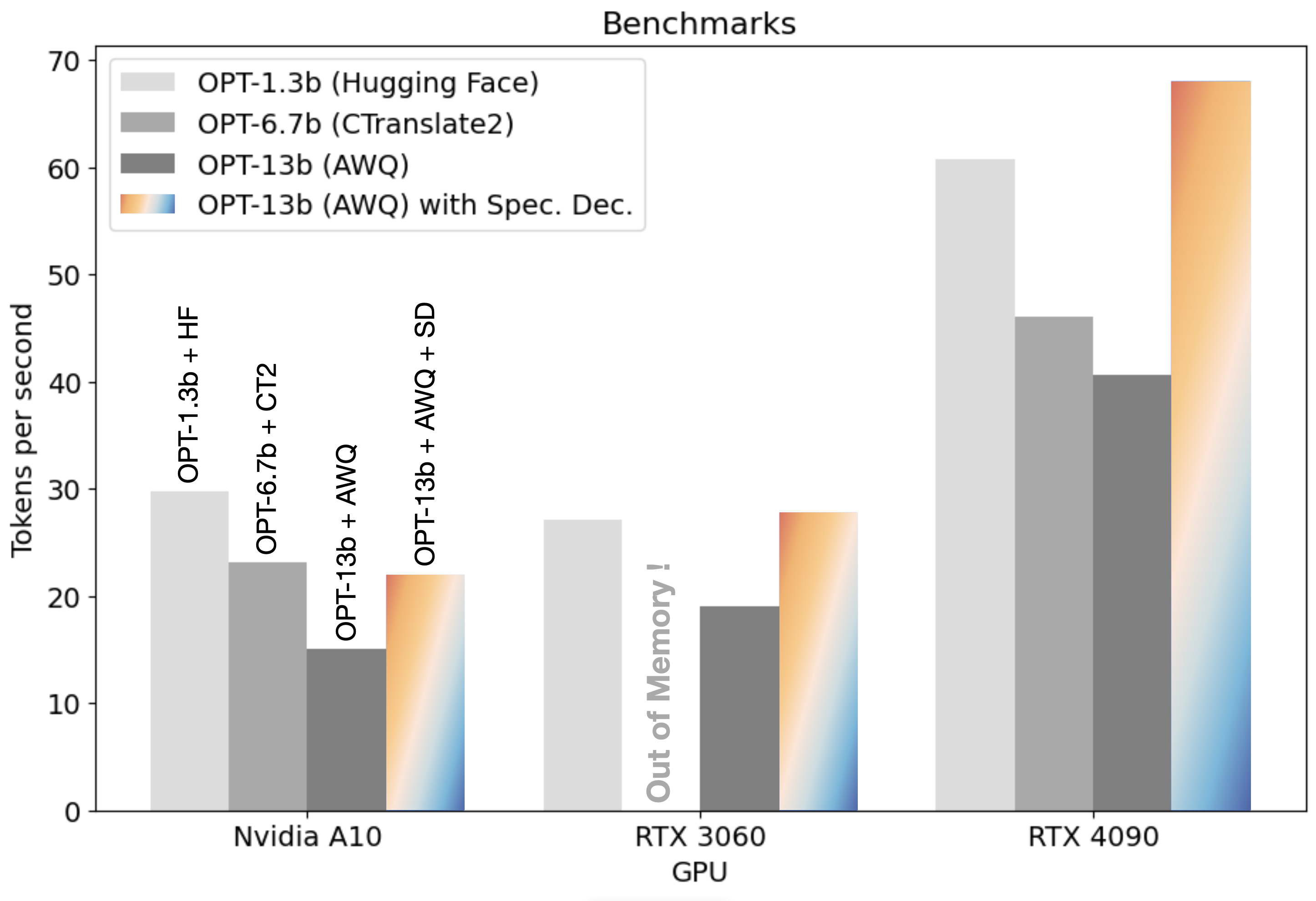 Speculative decoding, coupled with the AWQ engine, speeds up the OPT-13b model to a similar speed as a model 10 times smaller on Hugging Face and twice as small on CTranslate2. Pretty cool, right?!
Speculative decoding, coupled with the AWQ engine, speeds up the OPT-13b model to a similar speed as a model 10 times smaller on Hugging Face and twice as small on CTranslate2. Pretty cool, right?!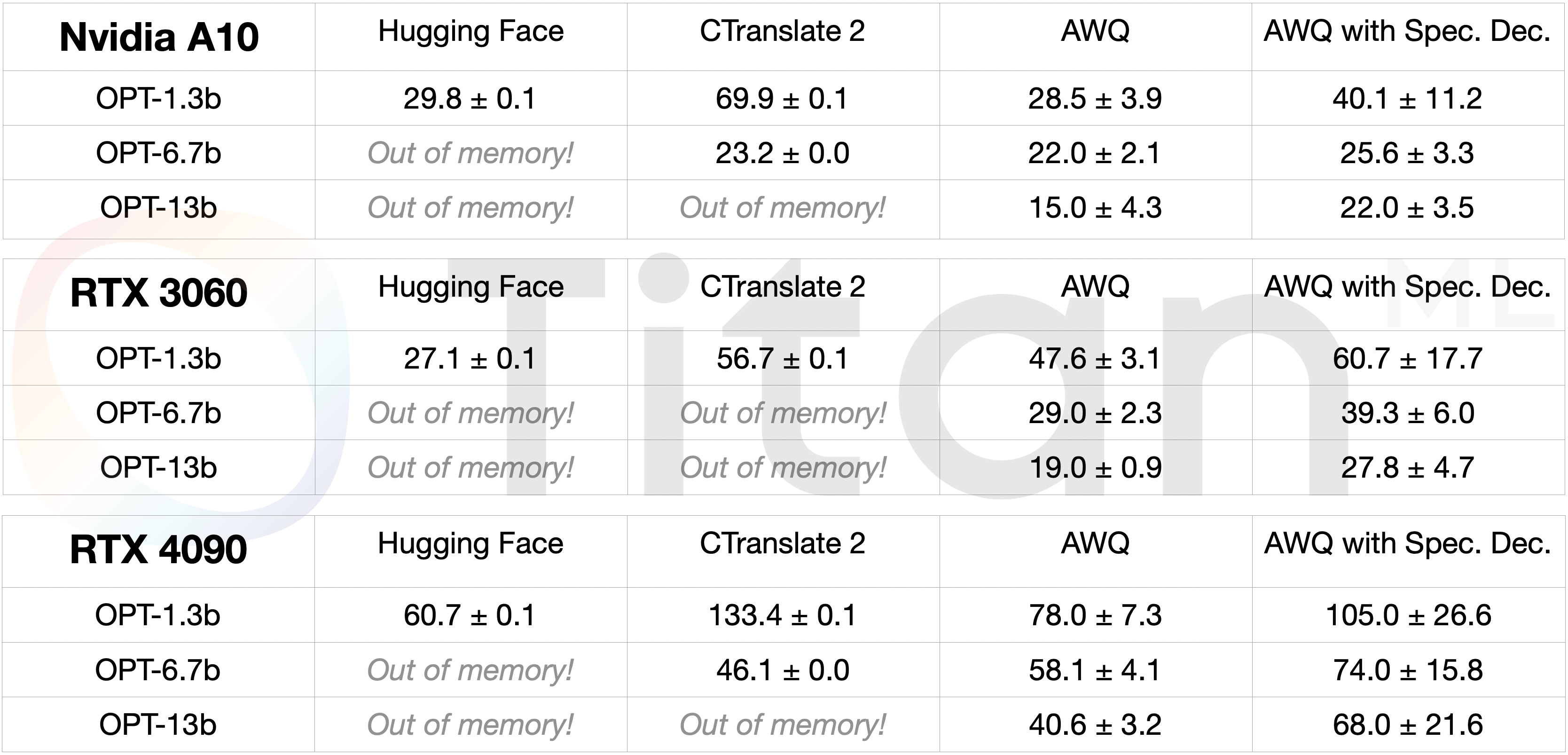 A benchmark table illustrating the performance of models in 3 different sizes across 3 GPUs. The values in the table indicate number of tokens generated per second.
A benchmark table illustrating the performance of models in 3 different sizes across 3 GPUs. The values in the table indicate number of tokens generated per second.