Building Applications with TitanML: What can I build with Takeoff Server?

Breaking down barriers to AI adoption
The release of various open-source Large Language Models (LLMs) this year has democratised the access to AI and its associated technologies. Colossal models like the Llama-2 70B or even the Falcon 180B represent incredible opportunities for those who can harness their power.
While anyone can certainly download a copy of these models, numerous AI enthusiasts face many barriers tapping into the power of these powerful models. These barriers may seem daunting; not only would inferencing these models require huge amounts of compute power, deploying these models is also a complicated affair.
This is why we've built the Titan Takeoff Server: to break down these barriers to AI adoption and allow everyone to deploy and tap into the power of these LLMs easily, so they can focus on building the AI-powered apps they care about.
What exactly is Titan Takeoff Server?
In short, Titan Takeoff Server is a package that allows you to deploy and inference an LLMs easily and efficiently.
Simplified Deployment
Titan Takeoff Server takes care of the difficulties of deploying and serving large language models, so you don't have to spend endless hours worrying about setting the right configurations and compatibility with your deployment environment. With a few simple commands, you'll be able to deploy your LLMs to anywhere you want, be it on your local machine or on the cloud. Check out our guides showing you how to deploy them on AWS, Google Cloud and Kubernetes.
Control over Data and Models
In an era where data privacy and proprietary models are paramount, Titan Takeoff Server stands out, allowing you to retain full ownership and control over your data, ensuring that sensitive information remains on-premises and is never exposed to third-party vulnerabilities.
Inference Optimisation
Inferencing LLMs can be very compute intensive, so we've developed the Titan Takeoff Server to be memory efficient, using state of the art quantisation techniques to compress your LLMs. This also means that you will be able to support much larger models without upgrading your existing hardware.
How can I build apps with Takeoff?
Starting the Titan Takeoff Server
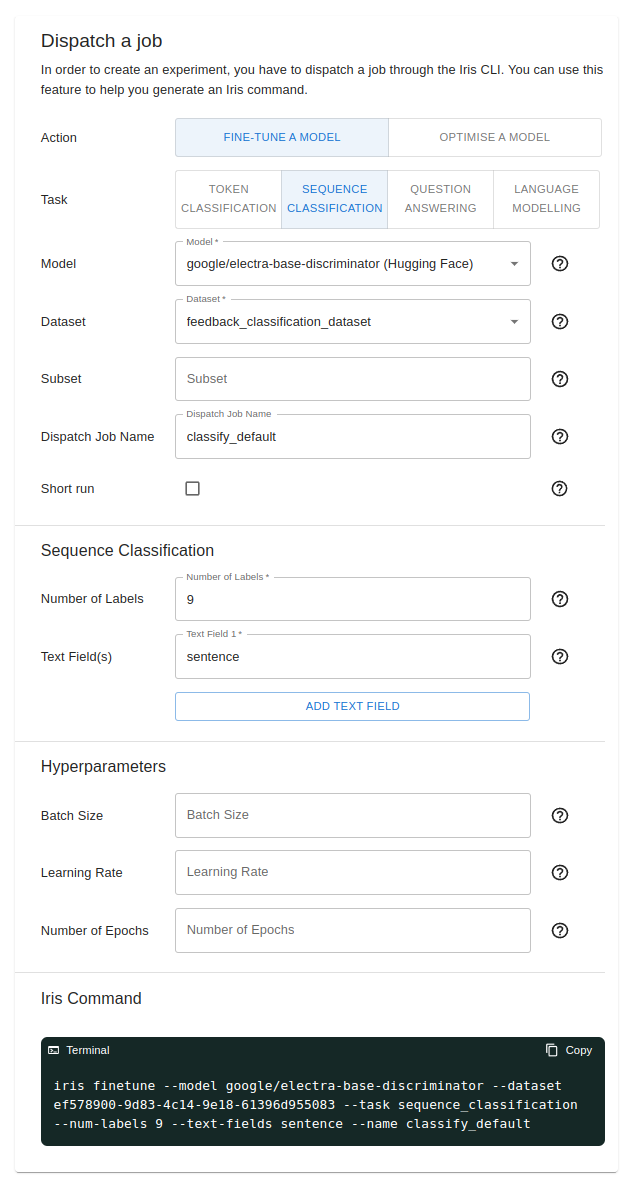
To get set up with the Titan Takeoff Server, there are only two commands that you need to run. The first command installs the Iris CLI, which interfaces with the Titan Takeoff Server.
pip install titan-iris
The second and final command is the takeoff command, which optimises and loads your model before starting up a server. Note that you'll have to specify the model name as well and will be given a choice of a few optional parameters.
iris takeoff
--model <model_name> # Specify model name
--device cuda # Select CPU or GPU(cuda)
--port 8000 # Specify port number for server
--token <token> # Needed for Llama-2 models
With the Titan Takeoff Server running, our model is ready to be inferenced on-demand, so it's time to start building apps. There are two main ways your app can interface with your model: through Titan Takeoff Server's own inference endpoints or the integration with LangChain.
Inference Endpoints
Titan Takeoff Server exposes two main inference endpoints: generate and generate_stream. If you want your response to be streamed back gradually, you should use the generate_stream endpoint, otherwise your response will only be returned as a whole chunk when it is ready. You can also specify your desired generation parameters, such as temperature, maximum token lengths etc.
LangChain Integration
Titan Takeoff Server also has an integration with LangChain, allowing you to access your model through LangChain's interface. This makes it easy to access a wealth of different tools and other integrations that may be needed for downstream processing. Click here to view our docs relating to the LangChain Integration. What kind of apps can you build with Titan Takeoff Server? During our dogfooding exercise, the TitanML team built several apps that showcased the breadth of what you can build with the Titan Takeoff Server:
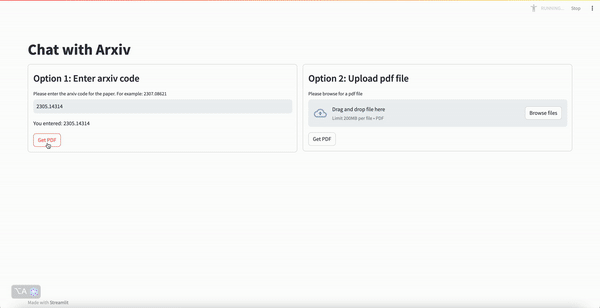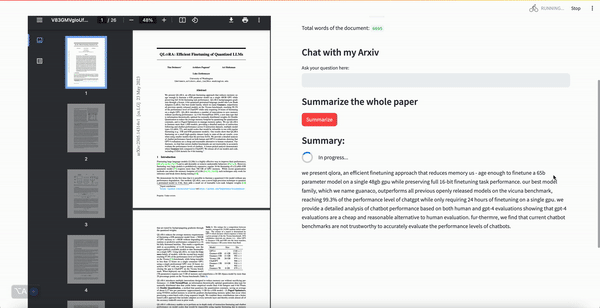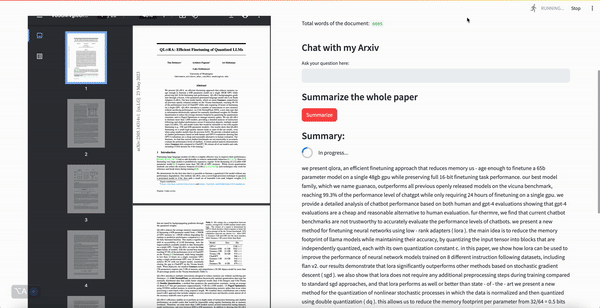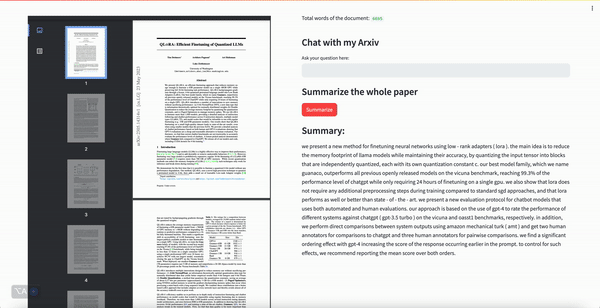
- Chatbot with summarization capabilities that can allow you to ask questions about an Arxiv academic paper
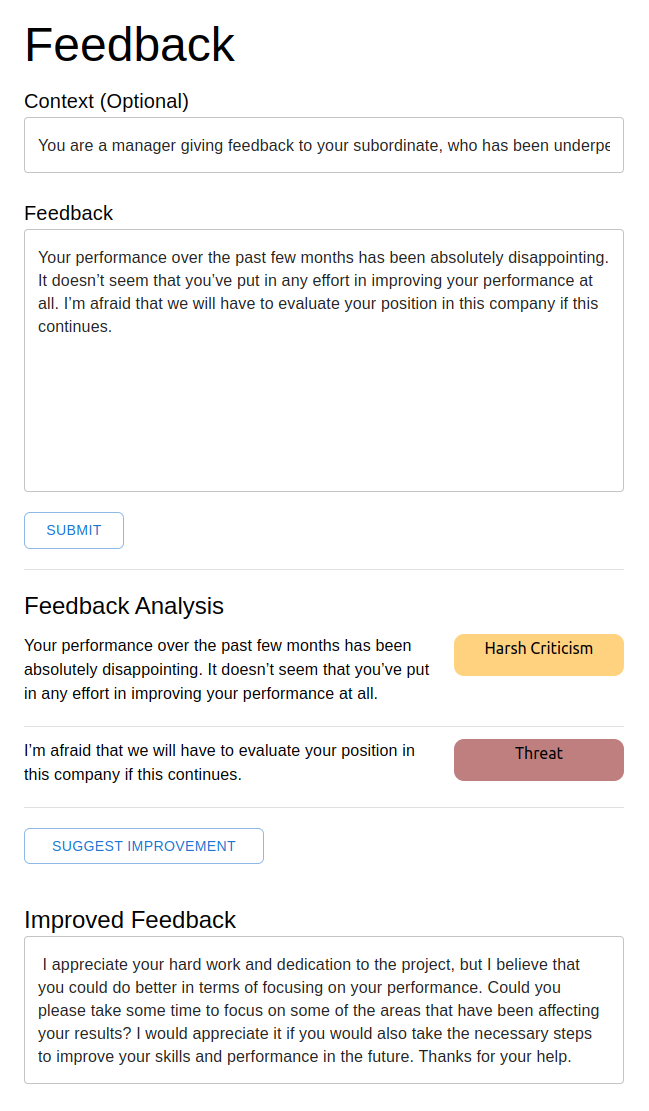
- Writing tool to detect critical feedback and turn them into constructive feedback
- App to generate Knowledge Graphs from news articles
The possibilities are endless with what you can create with LLMs. And if you're still struggling for ideas, here are some examples to stoke your imagination:
Conversational AI Chatbots
To power a chatbot with Titan Takeoff Server, begin by deploying a conversational model, possibly a variant of GPT or Falcon optimised for dialogue. Titan simplifies this deployment process by allowing you to load and serve the model locally. Once set up, you can integrate this server with your chat application's backend, ensuring efficient handling of user requests.
By coupling real-time processing capabilities of Titan with a user-friendly UI, you'll have a chatbot that can address user queries, engage in meaningful interactions, and provide context-aware solutions, all powered locally without the need for external APIs.
Content Creation & Enhancement
Content creators often struggle with writer's block or need assistance in refining their drafts. Using Titan Takeoff Server, you can deploy a language model tailored for content generation or enhancement. Integrate this with platforms like CMS or blogging tools, where users can input topic prompts or existing drafts. The Titan Takeoff server can suggest content drafts, refine sentences, or even generate catchy headlines in real-time. By doing this, you offer a dynamic writing assistant that not only aids in creating content but also ensures it's engaging and well-structured, all while ensuring data remains local and private.
Educational Tutor Apps
Modern learning experiences can be augmented with AI-powered tutors. Using Titan Takeoff Server, deploy a model trained for educational explanations. You can develop an interactive platform where students can input their questions or topics of confusion. Their queries can be sent to the Titan Takeoff Server, which then consults an educational model to produce coherent, easy-to-understand explanations. Such an app can be a boon for learners, providing them instant access to clarifications, supplementary content, and personalized learning resources, all while ensuring the data remains on-premises, preserving student privacy.
Bonus: Retrieval Augemented Generation with Vector Databases
If you have deployed an extremely large model unsuitable for fine-tuning or constantly require up to date information, you can consider implementing Retrieval Augmented Generation (RAG). RAG is a technique that combines the strengths of large pre-trained models with external knowledge databases. Instead of solely relying on the model's internal knowledge, which might be outdated or limited, RAG queries an external database in real-time to fetch relevant information or context before generating a response.
To enhance the accuracy of your results, as well as the speed of retrieval, you can even consider using a vector databases such as Weaviate or Pinecone. Vector databases enable rapid, real-time semantic searches, allowing systems to retrieve information based on conceptual similarity rather than just exact matches. This ensures faster, more contextually relevant results, bridging the gap between raw data and genuine understanding.
This approach can be particularly useful for chatbots in dynamic sectors where current data is paramount, such as finance, news, or technology trends. With Titan Takeoff Server's optimized inference capabilities, incorporating RAG can lead to more informed, up-to-date, and contextually aware responses, elevating the overall user experience of your conversational AI application.
Conclusion
In all of these applications, Titan Takeoff Server acts as the local powerhouse, offering real-time, efficient, and secure model inferencing, which can produce transformative solutions, when combined with tailored models and thoughtful user experience design. We can't wait to see what you choose to build!