It is no secret that we built Titan Takeoff to make it easy for you to make inferences and deploy your models. With the nitty-gritty details of deployment and technical complications of running massive models abstracted away, you can stop worrying about performance issues and instead focus on what really matters - how to select the best model for your use case and get your desired model to product quality outputs.
We recognize that the model selection and prompt engineering process are essential as this can influence the user experience and satisfaction with your applications. We also realize that this process is complex, usually requiring many rounds of repeated experimentation.
Simplified Model Selection and Prompt Engineering with LLM Arena
In order to help you with this challenging process, we have built the LLM Arena. This interactive web application lets you quickly compare the outputs across different models and prompts. We’ve abstracted away all the technical complexities of deploying other models, so you can use our simple interface to compare different models and prompts, speeding up experimentation and development of your AI-powered application.
In the previous blog post, we talked about the Tournament Mode, where users can host a knockout-style tournament for Large Language Models, allowing them to judge and compare outputs between various models and find the ultimate winning model that produces the best output.
While this may be a helpful way of testing out a more comprehensive selection of models, we recognize that this may only be appropriate for some model comparison workflows. Therefore, we have included a Comparison mode in the LLM Arena that allows users to simply compare two models in-depth, side-by-side, without going through the process of playing a whole tournament and spinning up and down different models.
Model Selection: You can pick two model outputs to compare side-by-side, making evaluating the outputs of the models more convenient and straightforward.
Simultaneous Streaming: The responses from two models are streamed back in real-time, allowing you to compare the speed of responses as well.
Efficient Model Orchestration: The Comparison Mode is built with Hades, a Kubernetes-based orchestration system that efficiently spins up and down models on demand, based on which models you need.
We’re still working with the fictional NextGen Education, an Education Tech company, from the previous blog post. We’re helping their marketing department with their social media campaign this time. They want to use an LLM to create a promotional post for their new product, PlanlyAI, an AI-powered tool to help teachers make lesson plans (what we did in our previous blog post).
They have decided to pick a Llama-2 7B model and have secured enough budget to host it in full precision. However, they can also choose to save much more by hosting a quantized or compressed version of Llama 2 7B on a smaller AWS instance, allowing them to spend more on marketing campaigns. But they’re still a bit hesitant about the performance loss that comes with quantization. In order to reassure them about using quantized models, they will have to see an output that is not significantly worse than that of the unquantized model.
This is the prompt we’re going to use:
Craft a compelling and concise marketing tweet for NextGen Tech, promoting their new product, PlanlyAI. PlanlyAI is an innovative AI-powered platform designed to assist teachers in generating comprehensive and engaging lesson plans efficiently. The tweet should emphasize the benefits of PlanlyAI, such as its ability to save time, enhance lesson quality, and personalize learning experiences. Highlight the user-friendly nature of the platform and its alignment with modern teaching needs. Include a call to action encouraging educators to explore PlanlyAI for their lesson planning needs. The tone should be enthusiastic, professional, and focused on the transformative impact of PlanlyAI in the educational sector. Ensure the tweet is under 280 characters, making it suitable for Twitter.
Here’s what it looks like in Comparison Mode:
We see that the outputs from the quantized and unquantized models aren’t very different from each other, and the marketing department will be pleased to know that they will have saved some compute costs for their marketing costs.
The comparison mode is a lightweight and helpful way to compare the outputs of two models side-by-side. It allows for quick experimentation to select the better model or sometimes even to test a hypothesis (that quantized models do not differ much from those in full precision). If you’re keen to incorporate LLM Arena into your AI game plan, do reach out to us.
TitanML enables machine learning teams to deploy large language models (LLMs) effortlessly and efficiently. Our flagship product, Titan Takeoff Inference Server, is already supercharging the deployments of several ML teams.
Founded by Dr. James Dborin, Dr. Fergus Finn, and Meryem Arik and backed by key industry partners, including AWS and Intel, TitanML is a team of dedicated deep learning engineers on a mission to supercharge the adoption of enterprise AI.
It is no secret that we built Titan Takeoff to make it easy for you to make inferences and deploy your models. With the nitty-gritty details of deployment and technical complications of running massive models abstracted away, you can stop worrying about performance issues and instead focus on what really matters - how to select the best model for your use case and get your preferred model to product quality outputs.
We recognize that the model selection and prompt engineering process are critical as this can influence the user experience and satisfaction with your applications. We also know that this process is complex, usually requiring many rounds of repeated experimentation.
Simplified Model Selection and Prompt Engineering with LLM Arena
In order to help you with this challenging process, we have built the LLM Arena. This interactive web application allows you to quickly compare the outputs across different models, as well as prompts. We’ve abstracted away all the technical complexities of deploying other models so you can use our simple interface to compare different models and prompts, speeding up the experimentation and development of your AI-powered application.
In this article, we will be featuring one of the modes of LLM Arena, Tournament Mode, where users can host a knockout-style tournament for Large Language Models, allowing them to judge and compare outputs between various models and find the ultimate winning model that produces the best output. It is a fun but also useful way to select the most appropriate model.
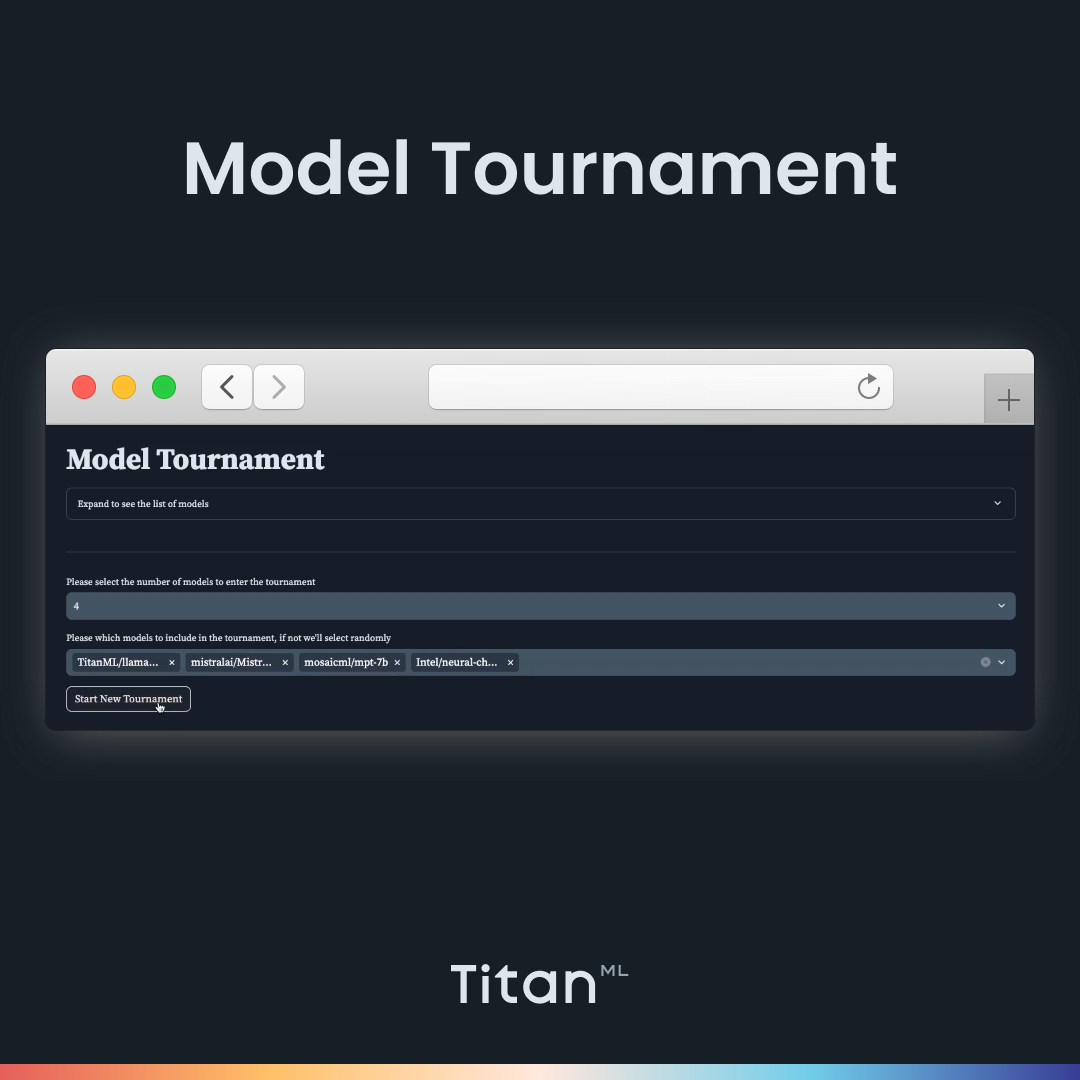
Model Selection: You can pick the number of models to be included in the tournament (4 or 8) and choose which models to have. It will automatically create a tournament bracket with your preferred models.
Knockout style Tournaments: Two models face each other in each battle, with the winner advancing to the next round and the other being eliminated
Blind Model Test: The names of the models are not revealed until the tournament ends to reduce bias when judging models.
Efficient Model Orchestration: The Tournament round is built with Hades, a Kubernetes-based orchestration system that efficiently spins up and down models on demand. It saves you the need to deploy many models simultaneously, which would be extremely expensive. It also saves you the hassle of manually spinning up and down models compared to just deciding to spin up one or two models at the same time.
Let’s say we’re an Education Tech company called NextGen Education. One of our internal tools is an AI-powered application that creates course materials for teachers and instructors. We’re looking to create a five-day lesson plan for high school students learning how to code with Python from scratch.
We have calculated that we have just enough budget to deploy an optimized 4-bit 7 Billion parameter LLM, but are not sure which LLM would be the most appropriate for our specific use case, so putting our four shortlisted 7 Billion models in a tournament to compare outputs and decide a winner sounds like a perfect way to determine how it works.
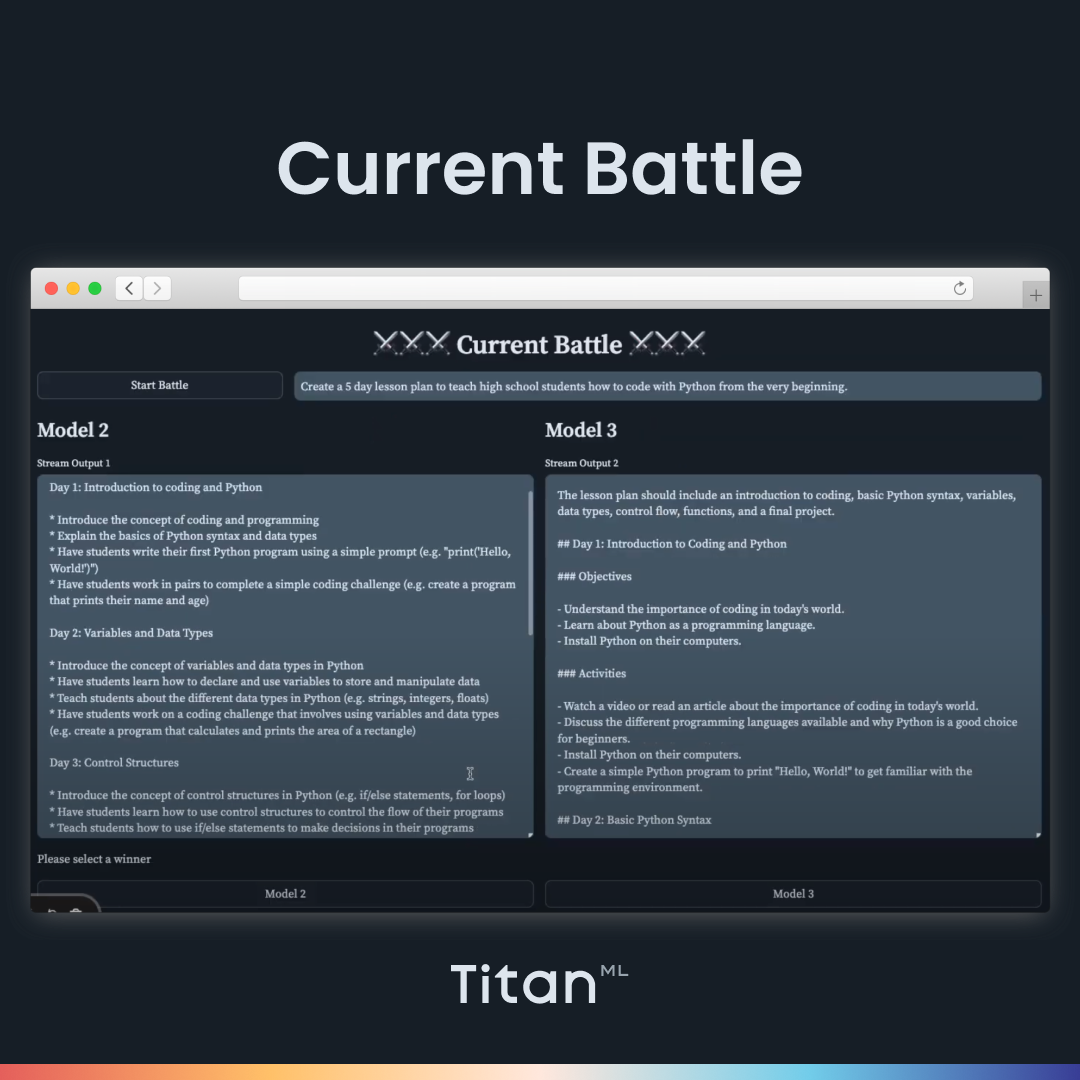
We can select four 7B models to compare. Here, we choose Intel’s Neural Chat, Llama-2, Mosaic ML’s MPT, and Intel’s NeuralChat. Then we can start the tournament. It pairs up the models into tournament brackets and loads up the first two models. In order to be impartial, the names of the models are not revealed until the end of the tournament. Let’s paste in our prompt (Create a five-day lesson plan to teach high school students how to code with Python from the very beginning).
Here, we can compare the outputs of the two models side-by-side very easily, evaluate their outputs, and pick the best one to advance to the next round. You will have a chance to assess each shortlisted model through the tournament bracket. Before each battle, our orchestration system, Hades, will spin down the old models and spin up the new models dynamically, saving you the need to deploy all the models at the same time.
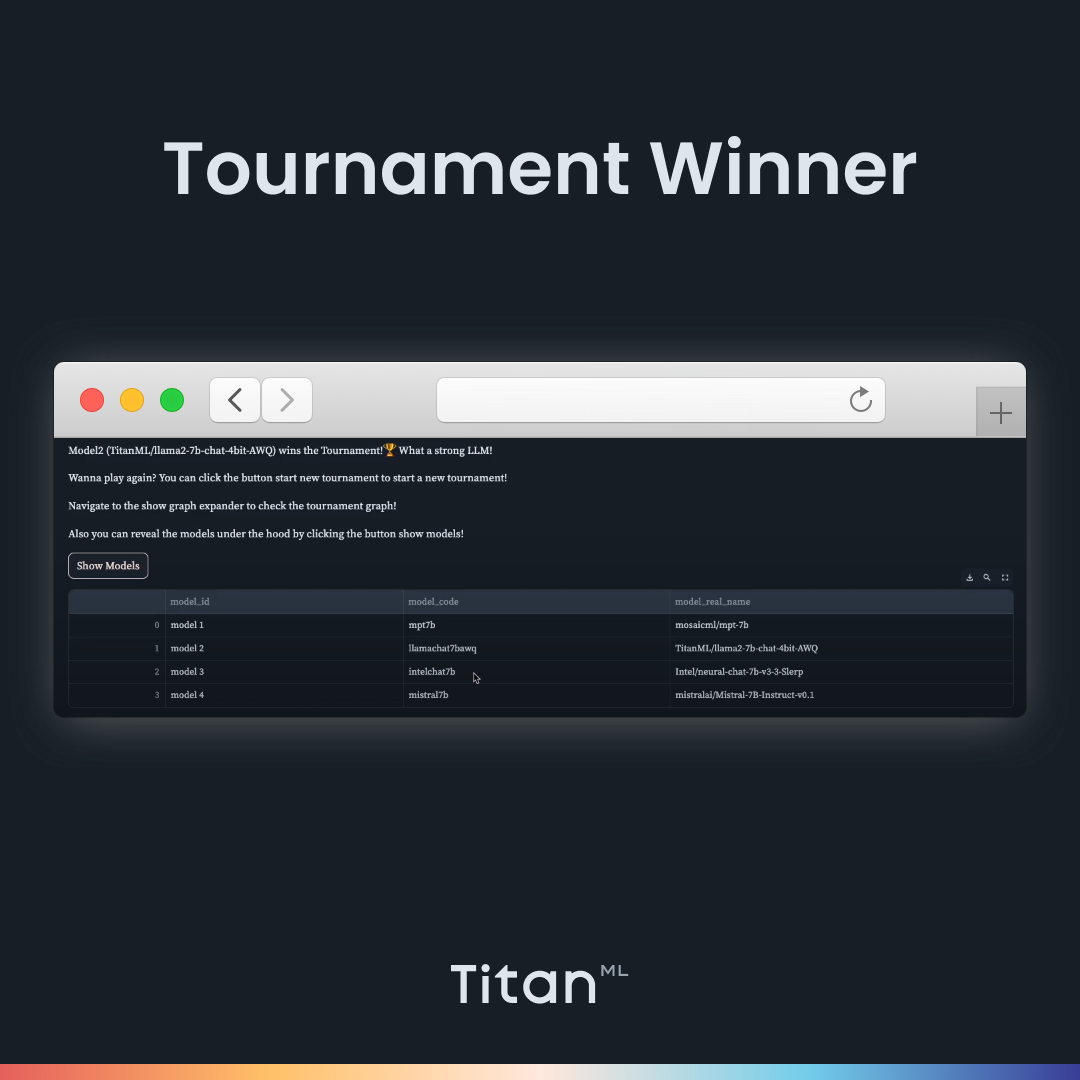
At the end of the tournament, the names of each model will be revealed, as well as the winning model. Congratulations, you have found a model most suited for your prompt. However, playing multiple tournaments is recommended before you select a suitable model to ensure outputs are consistent, reliable, and appropriate. You should battle-test your models to ensure that your models behave properly when receiving inappropriate or ambiguous requests.
Selecting a model best suited for your use case is essential as it can determine the quality of your outputs and user experience with your AI-powered app. It usually requires repeated experimentation that may be troublesome and impractical without suitable tools. The LLM Arena, built on Titan Takeoff, bridges this gap by allowing you to focus on experimentation to select the suitable model by abstracting the complex logic of model orchestration. If you want to incorporate LLM Arena into your AI game plan, do reach out to us.
TitanML enables machine learning teams to deploy large language models (LLMs) effortlessly and efficiently. Our flagship product, Titan Takeoff Inference Server, is already supercharging the deployments of several ML teams.
Founded by Dr. James Dborin, Dr. Fergus Finn, and Meryem Arik and backed by key industry partners, including AWS and Intel, TitanML is a team of dedicated deep learning engineers on a mission to supercharge the adoption of enterprise AI.
Welcome to the world of retrieval augmented generation (RAG) — a groundbreaking approach revolutionizing natural language processing applications. In the pursuit of creating more coherent, contextually relevant, and informative content, researchers have devised an innovative methodology that combines the prowess of retrieval-based techniques with the fluency of generative models. This combination enables machines to not only generate text but also retrieve and incorporate pertinent information from vast repositories, leading to a more refined, context-aware, and knowledgeable output. In this walkthrough, I hope to elucidate the
techniques involved in building a RAG application, and provide a template to emulate for your own projects. As always, we at TitanML take away the tricky parts of initialising, building, optimising and orchestrating your models, so you can get straight into coding the application around them, prototyping your product and iterating on your big ideas.
So, what is RAG? Simply put, it is a technique for providing extra information to our models before expecting back an answer. This may be necessary because you want:
it to answer questions based off of information outside of its knowledge base.
to ask questions about events after the model's cutoff date.
access to niche or specialised information (without the hassle of finetuning).
or most commonly: you want the model to be able to inference about private data. Think medical records, emails, company docs and contracts, IP, anything internal that never had a chance to appear in the public internet scrape that went into the initial training.
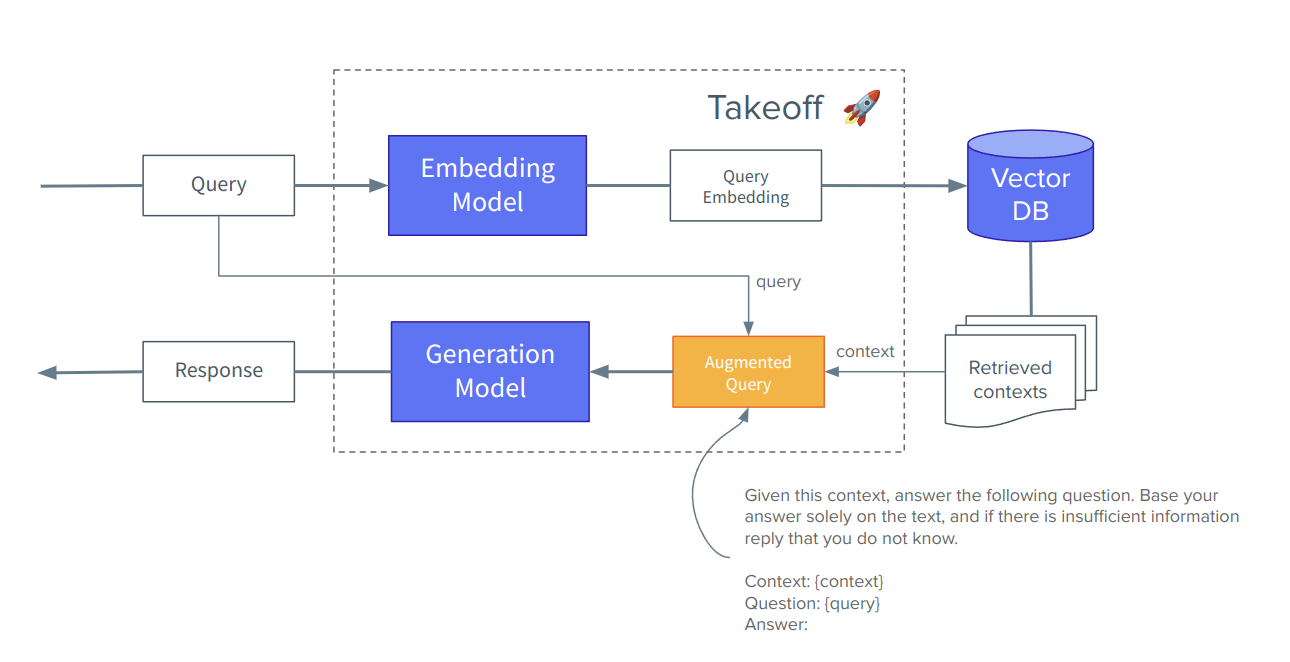
The idea behind RAG is to first go and collect the relevant bits of information from our large pool of documents and then add this text, hopefully containing the answer to the question, as an extension to our prompt of the generation model. Rather than make anything up, the model just has to read and extract the answer from the context provided. The
way we can make comparison between texts and queries is based off of the idea of textual embeddings - if done well, similar text (words, sentences, sections or whole documents) should be embedded into similar vectors. We can then rank text matches between our query and passages using simple vector comparison maths, and hopefully receive high scores when the
passage has similar content to what the question is alluding to.
A RAG workflow: a method to augment our prompts to help chat models answer questions on our personal data. Note our 'augmented' prompt is a combination of the context, the query and a prompt template.
For this demo we are switching industry - we are going to emulate a big bank with billions of assets under management - and importantly, our company information is split across a sea of distributed documents. For our application we need our chatbot to be able to retrieve and recall from these private documents, so the answers provided are correct, even though the corpus is not in the model's knowledge base.
documents =[ "Our research team has issued a comprehensive analysis of the current market trends. Please find the attached report for your review.", "The board meeting is scheduled for next Monday at 2:00 PM. Please confirm your availability and agenda items by end of day.", "Our quarterly earnings report will be released to the public on the 10th. Senior management is encouraged to prepare for potential investor inquiries.", "The due diligence process for the potential merger with XYZ Corp is underway. Please provide any relevant data to the M&A team by Friday.", "Please be informed that our compliance department has updated the trading policies. Ensure all employees are aware and compliant with the new regulations.", "We're hosting a client seminar on investment strategies next week. Marketing will share the event details for promotion.", "The credit risk assessment for ABC Corporation has been completed. Please review the report and advise on the lending decision.", "Our quarterly earnings for the last quarter amounted to $3.5 million, exceeding expectations with a 12% increase in net profit compared to the same period last year.", "The investment committee meeting will convene on Thursday to evaluate new opportunities in the emerging markets. Your insights are valuable.", "Our asset management division is launching a new fund. Marketing will roll out the promotional campaign in coordination with the release.", "An internal audit of our trading operations will commence next week. Please cooperate with the audit team and provide requested documents promptly.", ]
For this demo, orchestration and inference of both models is going to be handled by a Takeoff Server.
Our server runs inside Docker containers, so we can deploy and manage them from python using the docker-sdk. Reach out to us here to gain access to the Takeoff Pro image (all the SOTA features), or pull and build the community edition here and adapt your code accordingly.
TAKEOFF_IMAGE_BASE ='tytn/takeoff-pro' # Docker-sdk code defis_takeoff_loading(server_url:str)->bool: try: response = requests.get(server_url +"/healthz") returnnot response.ok except requests.exceptions.ConnectionError as e: returnTrue defstart_takeoff(name, model, backend, device, token=HF_TOKEN): print(f"\nStarting server for {model} with {backend} on {device}...") # Mount the cache directory to the container volumes =[f"{Path.home()}/.takeoff_cache:/code/models"] # Give the container access to the GPU device_requests =[docker.types.DeviceRequest(count=-1, capabilities=[["gpu"]])]if device =="cuda"elseNone client = docker.from_env() image =f"{TAKEOFF_IMAGE_BASE}:0.5.0-{'gpu'if device =='cuda'else'cpu'}" server_port =4000 management_port =4000+1 container = client.containers.run( image, detach=True, environment={ "TAKEOFF_MAX_BATCH_SIZE":10, "TAKEOFF_BATCH_DURATION_MILLIS":300, "TAKEOFF_BACKEND": backend, "TAKEOFF_DEVICE": device, "TAKEOFF_MODEL_NAME": model, "TAKEOFF_ACCESS_TOKEN": token, }, name=name, device_requests=device_requests, volumes=volumes, ports={"3000/tcp": server_port,"3001/tcp": management_port}, shm_size="4G", ) server_url =f"http://localhost:{server_port}" management_url =f"http://localhost:{management_port}" for _ inrange(10):# Give te server time to init and download models ifnot is_takeoff_loading(server_url): break print("building...") time.sleep(3) print('server ready!') return server_url, management_url
takeoff_url, takeoff_mgmt = start_takeoff( 'rag-engine',#container name chat_model,#model name 'compress-fast',#backend 'cuda'#device ) # in terminal run: 'docker logs rag-engine' to see status # first time running this may take a while as the image needs to be downloaded
Starting server for meta-llama/Llama-2-7b-chat-hf with compress-fast on cuda... building... building... building... server ready!
Takeoff streams generated tokens back from the server using Server Sent Events (SSE). These two utility functions help print the tokens in the response as they arrive.
defprint_sse(chunk, previous_line_blank=False): chunk = chunk.decode('utf-8') text = chunk.split('data:') iflen(text)==1: returnTrue text = text[1] ifnot previous_line_blank: print('\n') print(text, end='') returnFalse defstream_response(response): prev =True for line in response.iter_lines(): prev = print_sse(line, prev)
We now have an inference server setup and ready to answer our queries, but with no RAG included - this means our model is going to have to wing it. Let's see how it does:
Our quarterly earnings are as follows: Q1 (April-June) Revenue: $100,000 Net Income: $20,000 Q2 (July-September) Revenue: $120,000 Net Income: $30,000 Q3 (October-December) ... Total Net Income: $100,000 Note: These are fictional earnings and are used for demonstration purposes only.
The model even admits itself that its answers are completely made up! This is good honesty, but also makes the generations absolutely useless to our production applications.
Vector databases are specialized databases designed for handling and storing high-dimensional data points, often used in machine learning, geospatial applications, and recommendation systems. They organize information in a way that enables quick similarity searches and efficient retrieval of similar data points based on their mathematical representations, known as vectors, rather than traditional indexing methods used in relational databases. This architecture allows for swift computations of distances and similarities between vectors, facilitating tasks like recommendation algorithms or spatial queries.
One of the essential pieces of a RAG engine is the vector database, for storing and easy access to our text embeddings. It is an exciting space, and there are a number of options to pick from out in the ecosystem (Dedicated vector database solutions: Milvus, Weaviate, Pinecone. Classic databases with vector search functionality: PostgreSQL, OpenSearch, Cassandra). However, for this demo we don't need all the bells and whistles, so we're going to make our own minimal one right here, with all the functionality we need. The VectorDB in our app sits external to takeoff, so feel free to swap in/out and customise to fit your personal VectorDB solution.
Our VectorDB needs a place to store our embedding vectors and our texts; as well as two functions: one to add a vector/text pair (we track their colocation by shared index) and one to retrievek documents based off 'closeness' to a query embedding. The interfaces to our DB take in the vectors directly so we can seperate this from our inference server, but feel free to place the calls to the models via Takeoff within the VectorDB class.
We can now populate our makeshift database. To do so, we send our text in batches to the embedding endpoint in our Takeoff server to receive their respective embeddings to be stored together.
This example uses a conservative batch size to matcch our small demo - but feel free to tune to your own needs.
batch_size =3 for i inrange(0,len(documents), batch_size): end =min(i + batch_size,len(documents)) print(f"Processing {i} to {end -1}...") batch = documents[i:end] response = requests.post(takeoff_url +'/embed', json ={ 'text': batch, 'consumer_group':'embed' }) embeddings = response.json()['result'] print(f"Received {len(embeddings)} embeddings") for embedding, text inzip(embeddings, batch): db.add(embedding, text) db.stats()
Processing 0 to 2... Received 3 embeddings Processing 3 to 5... Received 3 embeddings Processing 6 to 8... Received 3 embeddings Processing 9 to 10... Received 2 embeddings {'vectors': torch.Size([11, 1024]), 'text': 11}
For each of our 11 documents, we have a (1, 1024) vector representation stored.
Let's quickly remind ourselves of our original query:
print(query)
What are our quarterly earnings?
This is the first part of our new RAG workflow: embed our query and use our db to match the most relevant documents:
response = requests.post(takeoff_url +"/embed", json ={ 'text': query, 'consumer_group':'embed' }) query_embedding = response.json()['result'] # Retrieve top k=3 most similar documents from our store contexts = db.query(query_embedding, k=3) print(contexts)
['Our quarterly earnings report will be released to the public on the 10th. Senior management is encouraged to prepare for potential investor inquiries.', 'The investment committee meeting will convene on Thursday to evaluate new opportunities in the emerging markets. Your insights are valuable.', 'Our quarterly earnings for the last quarter amounted to $3.5 million, exceeding expectations with a 12% increase in net profit compared to the same period last year.']
With this extra information, let's see if our model can provide the correct answer:
context ="\n".join(contexts) augmented_query =f"context: {context}\n be as precise in your answer as possible, just give the answer from the context\nquery: {query}?\nanswer:" response = requests.post(takeoff_url +"/generate", json={'text': augmented_query} ) answer = response.json()['text'] print(answer)
defget_contexts(question, db, k=5): response = requests.post(takeoff_url +'/embed', json ={ 'text': question, 'consumer_group':'embed' }) question_embedding = response.json()['result'] return db.query(question_embedding, k=k) defmake_query(question, context): user_prompt =f"context: {context}\n be as precise in your answer as possible, just give the answer from the context\nquestion: {question}\nanswer:" return requests.post(takeoff_url +'/generate_stream', json={'text': user_prompt}, stream=True) defask_question(question): contexts = get_contexts(question, db, k=5) contexts ="\n".join(reversed(contexts))# reversed so most relevant context closer to question return make_query(question, contexts)
stream_response(ask_question("what is the research team working on?"))
The research team is working on a comprehensive analysis of the current market trends.
queries =["Which corporation is doing our credit risk assessment?", "what is the research team working on?", "when is the board meeting?"] for query in queries: print(f"Question: {query}") stream_response(ask_question(query)) print("\n=======================================================")
Question: Which corporation is doing our credit risk assessment? ABC Corporation. ======================================================= Question: what is the research team working on? The research team is working on a comprehensive analysis of the current market trends. ======================================================= Question: when is the board meeting? Monday at 2:00 PM. =======================================================
And that is it! We have an end-to-end application that is capable of interpreting and then answering detailed questions based off of our private, internal data.
The beauty of RAG is that we get the perks of generative models: we can interface our application with human language, and our model understands and adapts to the nuances and intentions
of our question phrasing, and the model can explain and reason its answer; plus, we get the benefits of retrieval models: we can be confident that the answer is correct, based on context, has a source,
and is not an infamous hallucination. In fact, as more and more people start bringing generative models into their products, RAG workflows are rapidly becoming the de facto way to design an application around the model at the core.
While the landscape of model deployment and orchestration can be challenging, the integration of two interdependent models may seem like an added layer of complexity. Luckily, TitanML is here to help - our expertise lies in managing these intricacies, so you can focus on your application and accelerate your product development.
TitanML enables machine learning teams to effortlessly and efficiently deploy large language models (LLMs). Our flagship product Takeoff Inference Server is already supercharging the deployments of a number of ML teams.
Founded by Dr. James Dborin, Dr. Fergus Finn and Meryem Arik, and backed by key industry partners including AWS and Intel, TitanML is a team of dedicated deep learning engineers on a mission to supercharge the adoption of enterprise AI.
The release of various open-source Large Language Models (LLMs) this year has democratised the access to AI and its associated technologies. Colossal models like the Llama-2 70B or even the Falcon 180B represent incredible opportunities for those who can harness their power.
While anyone can certainly download a copy of these models, numerous AI enthusiasts face many barriers tapping into the power of these powerful models. These barriers may seem daunting; not only would inferencing these models require huge amounts of compute power, deploying these models is also a complicated affair.
This is why we've built the Titan Takeoff Server: to break down these barriers to AI adoption and allow everyone to deploy and tap into the power of these LLMs easily, so they can focus on building the AI-powered apps they care about.
Titan Takeoff Server takes care of the difficulties of deploying and serving large language models, so you don't have to spend endless hours worrying about setting the right configurations and compatibility with your deployment environment.
With a few simple commands, you'll be able to deploy your LLMs to anywhere you want, be it on your local machine or on the cloud. Check out our guides showing you how to deploy them on AWS, Google Cloud and Kubernetes.
In an era where data privacy and proprietary models are paramount, Titan Takeoff Server stands out, allowing you to retain full ownership and control over your data, ensuring that sensitive information remains on-premises and is never exposed to third-party vulnerabilities.
Inferencing LLMs can be very compute intensive, so we've developed the Titan Takeoff Server to be memory efficient, using state of the art quantisation techniques to compress your LLMs. This also means that you will be able to support much larger models without upgrading your existing hardware.
To get set up with the Titan Takeoff Server, there are only two commands that you need to run. The first command installs the Iris CLI, which interfaces with the Titan Takeoff Server.
pip install titan-iris
The second and final command is the takeoff command, which optimises and loads your model before starting up a server. Note that you'll have to specify the model name as well and will be given a choice of a few optional parameters.
iris takeoff --model <model_name> # Specify model name --device cuda # Select CPU or GPU(cuda) --port 8000 # Specify port number for server --token <token> # Needed for Llama-2 models
With the Titan Takeoff Server running, our model is ready to be inferenced on-demand, so it's time to start building apps.
There are two main ways your app can interface with your model: through Titan Takeoff Server's own inference endpoints or the integration with LangChain.
Titan Takeoff Server exposes two main inference endpoints: generate and generate_stream. If you want your response to be streamed back gradually, you should use the generate_stream endpoint, otherwise your response will only be returned as a whole chunk when it is ready. You can also specify your desired generation parameters, such as temperature, maximum token lengths etc.
Titan Takeoff Server also has an integration with LangChain, allowing you to access your model through LangChain's interface. This makes it easy to access a wealth of different tools and other integrations that may be needed for downstream processing. Click here to view our docs relating to the LangChain Integration.
What kind of apps can you build with Titan Takeoff Server?
During our dogfooding exercise, the TitanML team built several apps that showcased the breadth of what you can build with the Titan Takeoff Server:
App to generate Knowledge Graphs from news articles
The possibilities are endless with what you can create with LLMs. And if you're still struggling for ideas, here are some examples to stoke your imagination:
To power a chatbot with Titan Takeoff Server, begin by deploying a conversational model, possibly a variant of GPT or Falcon optimised for dialogue. Titan simplifies this deployment process by allowing you to load and serve the model locally. Once set up, you can integrate this server with your chat application's backend, ensuring efficient handling of user requests.
By coupling real-time processing capabilities of Titan with a user-friendly UI, you'll have a chatbot that can address user queries, engage in meaningful interactions, and provide context-aware solutions, all powered locally without the need for external APIs.
Content creators often struggle with writer's block or need assistance in refining their drafts. Using Titan Takeoff Server, you can deploy a language model tailored for content generation or enhancement. Integrate this with platforms like CMS or blogging tools, where users can input topic prompts or existing drafts. The Titan Takeoff server can suggest content drafts, refine sentences, or even generate catchy headlines in real-time. By doing this, you offer a dynamic writing assistant that not only aids in creating content but also ensures it's engaging and well-structured, all while ensuring data remains local and private.
Modern learning experiences can be augmented with AI-powered tutors. Using Titan Takeoff Server, deploy a model trained for educational explanations. You can develop an interactive platform where students can input their questions or topics of confusion. Their queries can be sent to the Titan Takeoff Server, which then consults an educational model to produce coherent, easy-to-understand explanations. Such an app can be a boon for learners, providing them instant access to clarifications, supplementary content, and personalized learning resources, all while ensuring the data remains on-premises, preserving student privacy.
Bonus: Retrieval Augemented Generation with Vector Databases
If you have deployed an extremely large model unsuitable for fine-tuning or constantly require up to date information, you can consider implementing Retrieval Augmented Generation (RAG). RAG is a technique that combines the strengths of large pre-trained models with external knowledge databases. Instead of solely relying on the model's internal knowledge, which might be outdated or limited, RAG queries an external database in real-time to fetch relevant information or context before generating a response.
To enhance the accuracy of your results, as well as the speed of retrieval, you can even consider using a vector databases such as Weaviate or Pinecone. Vector databases enable rapid, real-time semantic searches, allowing systems to retrieve information based on conceptual similarity rather than just exact matches. This ensures faster, more contextually relevant results, bridging the gap between raw data and genuine understanding.
This approach can be particularly useful for chatbots in dynamic sectors where current data is paramount, such as finance, news, or technology trends. With Titan Takeoff Server's optimized inference capabilities, incorporating RAG can lead to more informed, up-to-date, and contextually aware responses, elevating the overall user experience of your conversational AI application.
In all of these applications, Titan Takeoff Server acts as the local powerhouse, offering real-time, efficient, and secure model inferencing, which can produce transformative solutions, when combined with tailored models and thoughtful user experience design. We can't wait to see what you choose to build!
As the popularity and accessibility of Language Learning Models (LLMs) continue to grow among the general public, creative individuals are leveraging them to develop an extensive array of inventive applications.
In this post, we demonstrate how you can use the TitanML Platform to fine-tune your own LLMs for one such creative use-case: creating an app to detect the critical aspects of feedback and transform them into constructive, actionable and encouraging feedback.
This simple app would help people become more aware of how their words might affect others and give them examples on how to turn their feedback into constructive ones that would support healthy interpersonal relationships.
In order to give truly constructive feedback, it helps to understand the difference between constructive and critical feedback. Understanding this difference is crucial in turning feedback into a tool for learning and growth.
Critical feedback focuses on pointing out the problems without offering solutions. They can often be harsh, overly negative and directed at the qualities of a person rather than their work. They are often vague and can contain sweeping generalisations, as well as exaggerations, personal attacks and accusations. In addition, such feedback is usually emotionally charged and can often be demotivating and discouraging for the individual on the receiving end.
In contrast, constructive feedback is usually positive and uplifting with specific and actionable suggestions. The main aim of constructive feedback is to help the individual improve by objectively pointing out the strengths and weaknesses of the work done by the individual.
The application we want to build would have two simple features:
Identify instances of critical/constructive feedback and an explain why it is critical/constructive.
Improve the given feedback by providing a constructive version of the feedback.
While both features could be implemented easily with an overarching LLM such as GPT-3 with different prompts, it may be far more efficient to use the two smaller models that are geared towards certain tasks.
For the first feature, we can use a sequence classification model that can produce a class label such as “critical” or “constructive” for each sentence. We could even go further to split the labels into more finer categories that would explain why the text is critical or constructive, such as the following:
Positive Comment (constructive)
Helpful Suggestion (constructive)
Balanced Criticism (constructive)
Vague Criticism (critical)
Harsh Criticism (critical)
Sarcastic Comment (critical)
Blameful Accusation (critical)
Personal Attack (critical)
Threat (critical)
This is not meant to be an exhaustive list. There may be other categories of critical or constructive comments, or sentences that may fall into more than one category, but these categories would be more than helpful in identifying why a part of the feedback would be critical or constructive.
For the second feature, we can use an encoder-decoder model that would “translate” critical feedback into constructive feedback. One good model to use would be the T5 (Text to Text Transfer Transformer) model. The model would take in a string of text and produce another string of text.
Now that we’ve outlined the basic model to use, we can move on to finding datasets to fine-tune our models.
As there are no readily available labelled datasets relevant to our tasks, we will have to generate them with OpenAI’s API. This is a technique we have seen previously.
In order to train the two separate models, we have to generate one dataset for each model.
Dataset 1 (Classification dataset)
The first dataset will be used to train the sequence classification model, which will take in a piece of text and return its corresponding label. Thus, the dataset will require two columns: sentence and label. Here we are going to use OpenAI’s text-davinci-003 model as they are better at understanding more complex instructions and producing standardised outputs that will be easier to parse.
An example of the prompt we used to generate the dataset is as follows:
Details
Our prompt
You are an expert in providing constructive feedback and are conducting a workshop to teach people how to transform instances of negative feedback into constructive feedback. Critical feedback is usually vague, accusatory and often focuses on the negative qualities of a person without containing much details. Constructive feedback is uplifting, given with a compassionate and helpful attitude, and usually contains clear and actionable suggestions for improvement. Can you generate 10 examples of critical feedback that contains harsh criticism (this can be replaced with labels from other categories) ?
This should be the format of the json:
[ "Your work lacks the quality to meet the requirements.", "You seem clueless when it comes to executing this task." ]
Dataset 2 (Translation Dataset)
The second dataset will be used to train the T5 model, which will take in a text containing a critical feedback and return the constructive version of the same feedback.
While generating the datasets for the first time, we discovered that most of the critical feedback we generated pertained to presentations (e.g. your presentation lacked a sense of structure, your presentation was boring etc.). This was probably because the example feedback we gave to the prompt was about presentations. This instance of oversampling can lead to poor performance of the model with real-world data. In order to address this, we specifically requested these examples of feedback to be from a different workplace context.
We used the following improved prompt:
Details
Our improved prompt
You are an expert in providing constructive feedback and are conducting a workshop to teach people how to transform instances of negative feedback into constructive feedback. Negative feedback is usually vague, accusatory and often focuses on the negative qualities of a person without containing much details. Constructive feedback is uplifting, given with a compassionate and helpful attitude, and usually contains clear and actionable suggestions for improvement.
Here is an example:
Negative Feedback: “Why was your presentation so confusing? You know that not everyone thinks like you.”
Constructive Feedback: “I think your presentation was ambitious in terms of coverage but could have been structured better to help audience to follow your presentation better. Would you be able to restructure your presentation the next time?”
Can you generate 5 pairs of negative feedback and the constructive version of each feedback in a different workplace context and put it in json format?
This should be the format of the json:
[ { "Context":"You are a manager at a consulting firm and you are giving feedback to a junior consultant on their report.", "Negative Feedback":"You are spending too much time on meaningless tasks.", "Constructive Feedback":"I think you are doing a great job formatting the report and designing the charts, however, it would be great if you could first focus on getting the research to a good standard first." }, { "Context":"You are the portfolio manager of a hedge fund and you are giving feedback to an analyst on their stock pitch.", "Negative Feedback":"Why didn't you include the fundamentals of the company in your report?", "Constructive Feedback":"I liked how concise your report was in summarizing the main points, but the clients might demand a bit more research on the fundamentals of each stock. Could you include more information in your next version?" } ]
We used JSON as a default output format for OpenAI as it is relatively standardised and easy to parse. We then converted the data and compiled them into a single csv file. Afterwards, we shuffled the rows of the dataset to ensure the labels are distributed evenly throughout, before splitting the dataset into two files, train.csv and validation.
For the Translation dataset, we combined the context column and negative feedback column into a single column as an instruction.
An Example
{ "Context":"You are a manager at a consulting firm and you are giving feedback to a junior consultant on their report", "Negative Feedback":"You are spending too much time on meaningless tasks" }
becomes:
"Context: You are a manager at a consulting firm and you are giving feedback to a junior consultant on their report. Make the following feedback constructive: You are spending too much time on meaningless tasks."
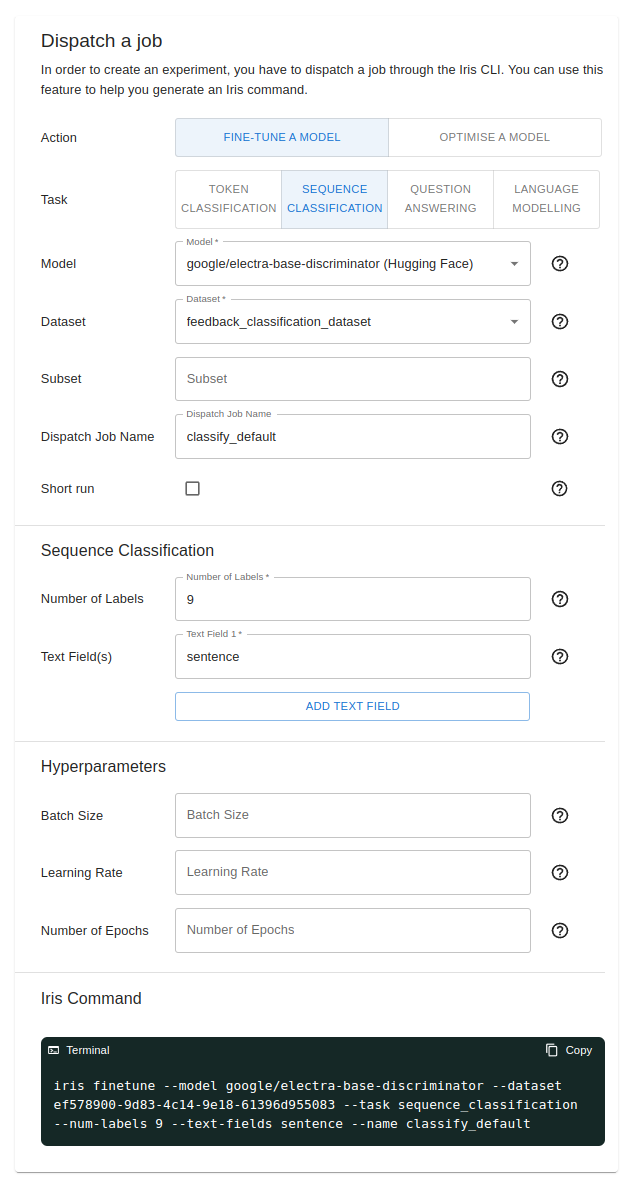
Next, we used the command generator feature to dispatch a new job/experiment. For this fine-tuning experiment, we are using the google/electra-base-discriminator model from HuggingFace. We can also select the dataset we previously uploaded with the dropdown.
As this is a sequence classification model, we had to fill in the number of labels and text field. We also have the option to provide configurations for hyperparameter tuning.
The TitanML Train command builder
We can then run the Iris command from the terminal to dispatch a fine-tuning experiment to our cluster. Alternatively, you may also try out the one-click dispatch feature that’s available if your models and datasets are already on HuggingFace or uploaded to Titan Hub.
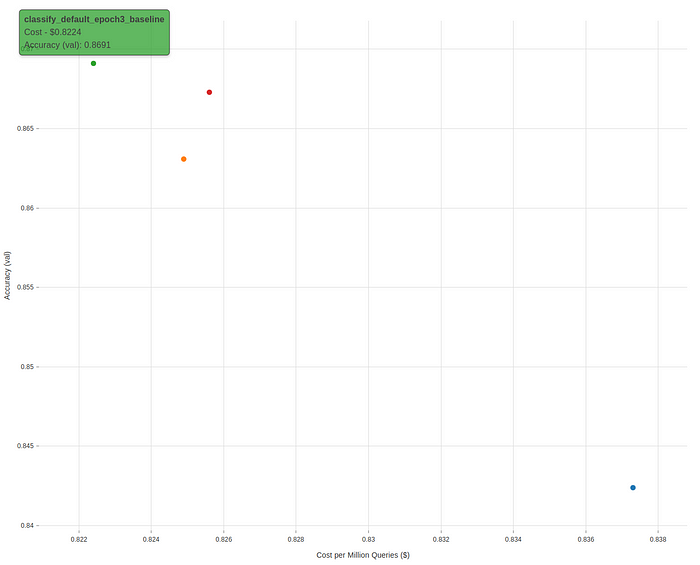
After running four different fine-tuning experiments, with a different number of epochs (1, 2, 3 and 4), we found that the model trained for 3 epochs give the optimal results (highest accuracy, lowest loss). We will use this model for our application to classify feedback.
The results of the fine-tuning experiments
For the T5 Model, the process is quite similar: we upload the dataset, then use the command generator to generate an Iris command to dispatch our experiment. However, in terms of evaluating the performance of models, it may be better to use the inference API by evaluating their outputs. This time, instead of focusing on hyperparameter tuning, we can try fine-tuning different variants of Google’s Flan T5 Model (Flan-T5-Small, Flan-T5-Large, Flan-T5-XL) to see which model gives us the best performance/size trade-off.
For generative models, we can use the Titan Inference API to test each models by giving them an input and judging them by the quality of their outputs.
We gave the models the following inputs to be made constructive:
Inputs
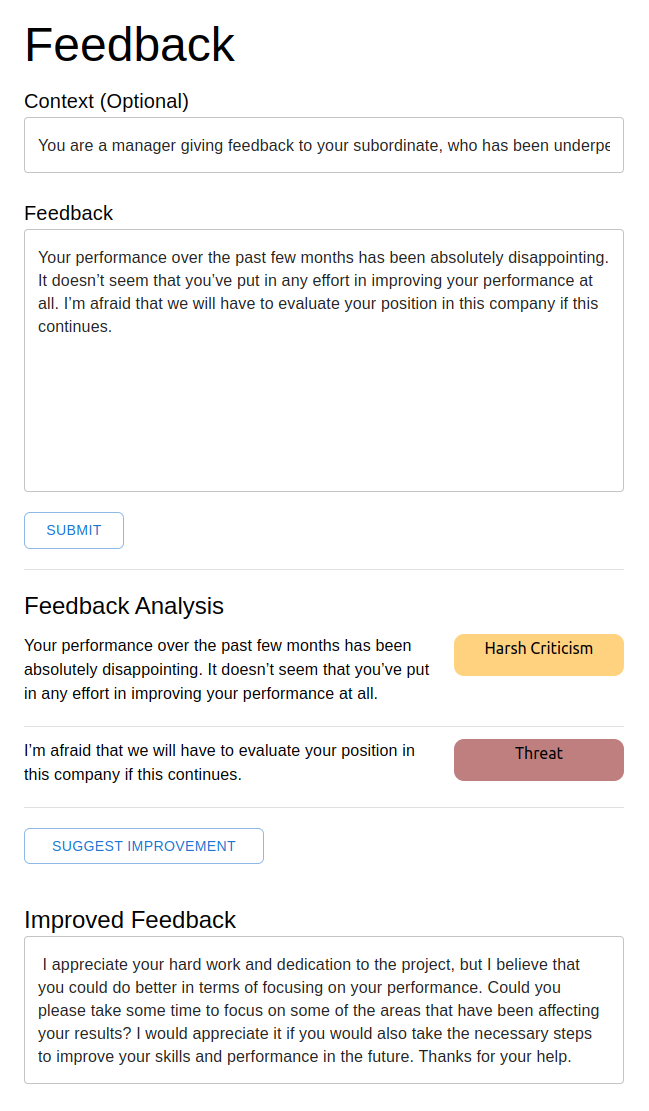
Context: You are a manager giving feedback to your subordinate, who has been underperforming severely over the past few months.
Critical text: Your performance over the past few months has been absolutely disappointing. It doesn’t seem that you’ve put in any effort in improving your performance at all. I’m afraid that we will have to evaluate your position in this company if this continues.
These are the outputs of the fine-tuned models:
Outputs
Flan-T5-small: I would suggest that your subordinate acted independently as he/she has been underperforming in the past. Please let me know if this is remedied.
Flan-T5-large: I hope this criticism shows that you’ve put your efforts in. Keep up the good job of managing your performance.
Flan-T5-XL: I think that you have tried your best to improve your performance, however, it would be beneficial for you to focus on your own strengths and learn from your mistakes to help improve your performance. Would you be able to set some time aside to focus on your own strengths and improve your performance?
From these examples, we see that the Flan-T5-small and Flan-T5-large models seem confused about the task, responding to the feedback rather than transforming it into a constructive version. Only the fine-tuned Flan-T5-XL model was able to produce coherent responses and thus this is what we will use for our application.
For our T5-Model, one of the most convenient options is to use the Titan Takeoff Server, accessible through our Iris CLI.
You can find detailed instructions on how to do this here.
Apart from a built-in CLI chatbot, you will also be able to spin up a server and make API requests to it, receiving either complete responses or streaming token by token.
After deploying our models, we can then use the associated endpoints to inference our models.
We have built a simple frontend where users can input their feedback and provide the context of their feedback.
Upon submission, each sentence would be analysed for its constructiveness and the user will be given a chance to improve the feedback with the click of a button.
With a few simple steps, users will be able to get a simple analysis of their feedback and an improved version of their feedback.
With the TitanML Platform, you can fine-tune LLMs easily for almost every use-case, and with the Titan Takeoff Inference Server, you can deploy them in production with ease.
To start applying cutting edge ML performance and latency optimisations to your own projects and models, checkout the TitanML platform!
If you have any questions, comments, or feedback on the TitanML platform, please reach out to us on our discord server. For help with LLM deployment in general, or to signup for the pro version of the Titan Takeoff Inference Server, with features like automatic batching, multi-gpu inference, monitoring, authorization, and more, please reach out at hello@titanml.co.
NVIDIA's stock price recently hit record levels1, on an earnings report that showed their data center sales had gone through the roof.
Those datacenter units were sold to companies trying to produce AI enabled applications.
But why has AI led to this rush to buy GPUs? Why Graphics Processing Units?
The answer lies in their potential for parallelising machine learning workloads by dividing them up and allowing multiple operations to be undertaken simultaneously.
We can answer this question by looking to language models, which can be thought of as a sophisticated tool designed to work with text. To illustrate, consider the autoregressive language models, whose primary task is to read a piece of text and predict the most fitting continuation.
Click the button below to see an example of an autoregressive language model in action2.
example
The quick brown fox
In order to achieve this, the language model will need to convert the input text into a list of numbers called a vector, that stores a information about a word. This process is called tokenization and is important as computers don't understand language the way humans do and can't intuitively know the meaning or sentiment of a word.
However, they are excellent at handling numbers. So, by representing words as vectors that encapsulate textual information such as semantic meaning, similarities with other words, contextual information, grammatical properties, we can feed this information into machine learning models that can then process, analyse, or even generate language.
At the heart of machine learning lies an operation called matrix multiplication, which underpin many of the key operations used in machine learning.
Matrix multiplication is the process of taking a grid of numbers called a matrix and using it to transform the input text vector from one vector to another.
This transformation turns one representation of our input text into another, rotating and skewing it in space until it looks completely different.
By transforming the input text in this way (interspersed with simple nonlinear transformations), we can capture the process of generating new text from old, by viewing it as a complicated transformation in a high-dimensional space.
When it comes to the forward operation of a machine learning model, the most resource-intensive step is computing the results of matrix multiplications[2].
This is where the role of GPUs becomes pivotal. Now, it's important to understand that matrix multiplications have a unique characteristic: they're inherently parallelisable.
In the example above, clicking the "Next Step" button only calculates a single element of the output vector.
Yet, each single calculation isn't dependent on the other. This means, if we have N computing units available, we could potentially compute N elements simultaneously, leading to a significant boost in the model's operational speed.
Here's where the difference between CPUs and GPUs becomes evident. CPUs are primarily designed to execute a limited set of operations at lightning speed, making them unsuitable for such parallel tasks.
GPUs, however, are specifically engineered for these extensive parallel workloads, making them indispensable in the realm of machine learning.
Thus, the solution to the NVIDIA mystery.
Why choose NVIDIA when there are numerous GPU providers out there? The consistent preference for NVIDIA in the machine learning arena can be attributed to its software. NVIDIA's CUDA software stack stands out as the most mature and widely-adopted platform. Notably, it seamlessly integrates with modern deep learning libraries like PyTorch, JAX, and Tensorflow. Programming with CUDA is straightforward, and the powerful abstraction layers built atop it make the process even more efficient.
NVIDIA manufactures two distinct types of GPUs: those designed for consumers and those tailored for data centers. The most recent and advanced consumer GPU series for deep learning is the RTX 40xx. On the other hand, NVIDIA's datacenter GPUs, which are available through cloud providers, represent a pricier yet significantly more potent option.
The A100, for exmple, is a previous generation datacenter GPU that was foundational in the training and inference of Large Language Models. The latest generation, the H100, is even more powerful. If you are looking for a comprehensive analysis on which consumer GPU to invest in for machine learning development, you can read more about it here.
The most common and most dreaded experience people have when working with deep learning on GPUs is the Out Of Memory (OOM) error. This occurs when the model that you're trying to work with is too large for the memory on your GPU.
So what are your options when you get an OOM error?
To most people, the most straightforward option is to procure a better GPU or rent one from a cloud provider, but this is often costly and unneccessary. The more sustainable alternative is to optimise your model.
This refers to the process of making your model smaller, faster, and more efficient. There are many different inference optimisation techniques that we use to bring you the best performance on our Titan Takeoff Server. As this is a huge topic, and we'll be writing more about it in the future, so do stay tuned!
In this post, we've seen how GPUs are the best option for machine learning workloads.
We've talked about what GPUs are available, and how to choose between them.
Finally, we've talked about the importance of inference optimization, to make sure that your model is running as efficiently as possible.
Simplified: in practise, the generated fragments don't correspond to words, but instead text fragments, called tokens: this process is called tokenization. For an example of how words are broken down, see openAI's tokenization demo. ↩
The pace of ML research is accelerating, and the amount of information available is growing exponentially.
It's becoming increasingly difficult to keep up with the latest developments in your field, let alone the wider world of research.
The TitanML platform incorporates the techniques from this fast-moving field to make it easy, fast, and efficient to build NLP applications.
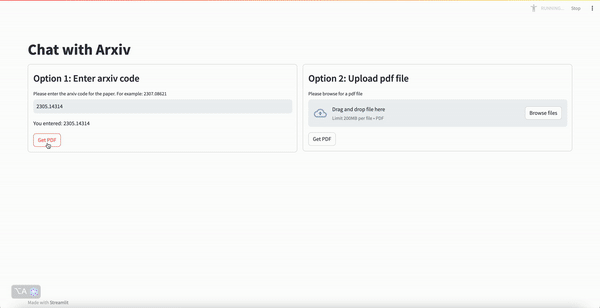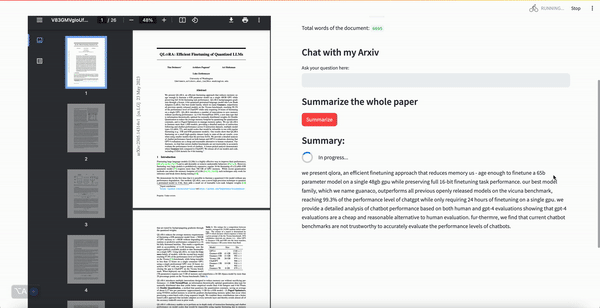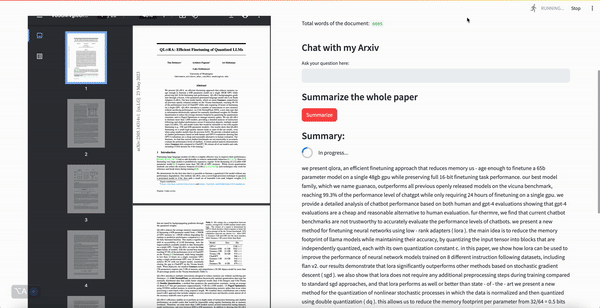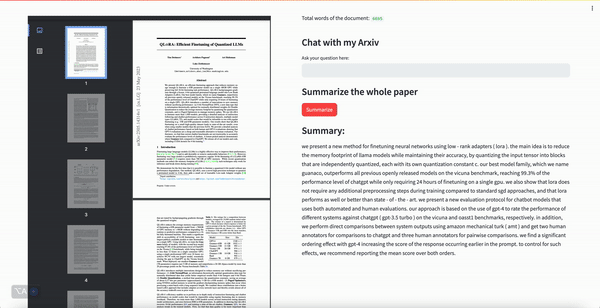
To help us keep up with the firehose of information, we can use NLP to summarise and answer questions about papers.
Interact with Arxiv papers: see the demo at http://54.167.108.88:8501/