Deploying LLMs on Small Devices: An Introduction to Quantization

One of the most notable features of large language models (LLMs) is actually in the name - they are large (shocking, I know). Up to the very recent past, even models as large as 10B parameters were considered cumbersomely large, and inconvenient to work with.
Now, all of a sudden, these models are popping up on Raspberry Pi's, laptops, and even mobile phones. How did this happen? How did we go from multi-billion parameter models being solely in the realm of compute-rich tech companies to being run on the edge. The release of powerful open-source LLMs also kicked off a plethora of research into ways to optimize these models for inference. One particular avenue of research that has proven extremely fruitful involves the concept of quantization. In this blog post we are going to explain:
- what the term means
- some peculiarities regarding quantizing LLMs
- and how we at TitanML use quantization to make deploying large language models easier for our clients.
What is Quantization
Language models, especially the large ones, are often trained using either 32-bit or 16-bit precision. What this means is that each parameter in the model is represented with either 32 or 16 bits. When we talk about a 32-bit model, it's stored using 32-bit floating point numbers. On the other hand, 16-bit models employ 16-bit floating point numbers or the 16-bit bfloat (brain-float, named after Google Brain, where the data type was first conceived) data type.
Now, why does this bit precision matter? Well, in terms of storage, a 32-bit model requires 4GB of memory for every 1 Billion parameters. Meanwhile, a 16-bit model halves that requirement to 2GB for the same number of parameters. Remember, this calculation only accounts for the storage of the model. Running the model in real-time requires additional memory. Moreover, while executing a large language model, temporary values called 'activations' can be quantized. This isn't predominantly to save memory but to harness the speed of 8-bit matrix multiplication operations that modern CPUs and GPUs support. Although this post sheds some light on activation quantization, our main focus will be on weight-only quantization.
Quantization is essentially a method to reduce the bit storage required for each model parameter. A prevalent approach is to bring it down to 8 bits per parameter. By this logic, a model with 1 Billion parameters would need just 1GB of memory. Translating this, a model with 7 Billion parameters (like a 'Llama' model) would necessitate at least 7GB of memory. Such a memory footprint is manageable on high-end laptops, but could challenge the capabilities of contemporary smartphones.
To put this into perspective, the most memory-endowed iPhones offer around 6GB, while the Google Pixel phones max out at approximately 8GB. So, if our goal is to facilitate large language models (LLMs) on mobile devices, we must push quantization boundaries. How? By venturing into even tinier bit-widths—7, 6, 5, 4, 3, 2, or even just a single bit per parameter. For instance, at 4-bit precision, our 7B parameter 'Llama' model would consume only 3.5GB, making it viable for today's smartphones. But delving into these lower bit-widths introduces complications. Striking the right balance among model quality, speed, and size becomes a nuanced challenge.
The quantization formula to quantize to int8 looks like this:
The Max parameter is a floating point number extracted from the weight to be quantized. 255 comes from the fact that we are using asymmetric quantization so we map all the values to a number between 0 and 255. If we were doing 4 bit quantization, this would end up being between 0 and 15.
Understanding the Impact of Quantization on Quality
When we delve into quantization, it's vital to recognize that it inherently reduces precision. In essence, by altering the model's weights through this process, there isn't a guarantee that the resulting weights will perform optimally. As a rule of thumb, there's often a performance dip post-quantization, especially when moving towards aggressive, low bit-widths. Large Language Models (LLMs) present a unique challenge in this arena. Empirical studies have revealed that LLMs often house extensive outlier features, meaning the model activations have certain values that are vastly different—often larger—than other values. During quantization, these outsized activations can become particularly vulnerable. Their sensitivity to quantization nuances means that aggressive methods might lead to significant quality loss. Thankfully, there are established best practices to navigate this terrain.
Grouped-Quantization
One approach to quantizing a model involves scaling and shifting its weight values so they fall between the range of 0 and 2^num-bits-1, then rounding down the weights to the closest integer value. This scale and shift process can be applied universally across an entire tensor, or alternatively, unique scale and shift parameters can be applied to specific weight groups.
For instance, it might be feasible to allocate separate scale and shift values for each matrix column. This strategy, known as "grouped quantization," underpins the 4-bit quantization methodologies employed by systems like GGML, exllama, bitsandbytes, and MLC. While grouped quantization offers considerable advantages, it does come with a minor downside—it slightly increases the bits-per-parameter required for storage.
If I store a 2 x 32bit values for every 64 4-bit numbers, then I effectively am effectively using 5 bits per parameter, not 4!
If we had an 8x8 matrix and wanted to quantize using a group-size of 4, then it would look something like this:

Each set of 4 values have their own max values calculated and are converted into 4-bit separately.
Protecting Important Weights
The other major direction of research is identifying the most important values in the LLMs, and somehow protecting them against the impacts of quantization. This is the approach adopted by a number of frameworks, including GPTQ, AWQ, LLM.int8(), and SpQR. All these approaches have different ways of identifying important weights, and different ways of ensuring that they are unaffected by quantization.
Our personal favourite at TitanML is AWQ. The authors identified that the important weights in a LLM are those that interact directly with the outlier features we spoke about earlier. If quantizing outliers has such a big impact on model quality, then surely there is some important signal locked up in the outliers that needs to be preserved. AWQ protects these weights by scaling the weights so that these so-called salient weights are protected against quantization errors by always being mapped losslessly to the largest value in the quantized range.
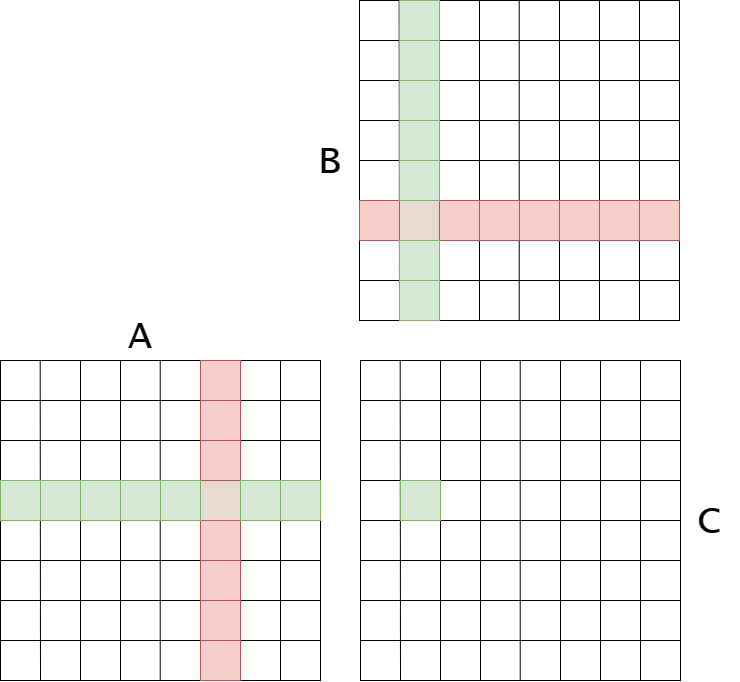
In the diagram above we have a schematic layout of a matrix multiplication. Each row of the matrix A is multiplied by the column of matrix B to create a single value in the output matrix, C. This is shown by the green values. It has been shown empirically that there are dimensions of A that are much larger than the others, these are the outlier features. These features form a column in matrix A, highlighted in red. This column identifies a row in matrix B, also highlighted in red. These are the salient weights that need to be protected during quantization.
Determining the Right Use for Quantization
It's crucial to discern when quantization is beneficial for your model, especially given its potential impact on accuracy. When you're designing vital downstream applications, here are some indicators suggesting that (weight-only) quantization might be a judicious choice for inference models.
Limited Compute Resources
The rationale here is pretty straightforward. When working with constrained computational capabilities, quantization can help. For instance, a Llama 13B model typically requires a GPU with at least 40GB of VRAM, such as Nvidia's A100 or A6000 GPU. But, by opting for 8-bit or 4-bit quantization, you could effectively run this on a more modest GPU like an A10 or even a T4. This can be a gamechanger for budding start-ups without high-end DGX setups or for applications run on edge data centres with legacy GPUs.
Small Batch Operations
If your models are processing only a handful of requests (less than 10) simultaneously, it's probable that memory bandwidth bound. This signifies that the mere act of transferring weights from memory to computation units becomes a rate-limiting step. In such scenarios, quantization might not only mitigate memory constraints but could also expedite inference—even considering the added dequantization computations. However, this advantage might wane in high batch scenarios. Without meticulously optimized quantization kernels, the inference process could decelerate markedly in these compute-intensive, high-batch situations. Thus, for localized LLMs processing individual requests or any application that requires limited simultaneous inferences, the dual benefits of enhanced speed and the feasibility of using modest GPUs make a compelling case.
Reliable Evaluation Metrics in Place
Assessing the performance of large language models is inherently challenging. Many developers resort to a rather subjective method—simply scrutinizing the outputs and deeming them "satisfactory" based on a visual check. While it's feasible to gauge perplexity scores post-quantization, such metrics aren't always reflective of subsequent application performance. Therefore, if you have robust evaluation measures at your disposal—whether that's classification metrics, multi-choice question assessments, or human evaluators—venturing into quantization becomes more defensible. With these tools, you can gain a clearer perspective on the implications for downstream application efficacy.
How we are using Quantization at TitanML
At TitanML we have built the Takeoff Server - our attempt at abstracting away the difficult and time consuming parts of LLM deployment and inference. The Takeoff Server includes 4-bit calibration using the same AWQ method mentioned above, and 4-bit inference for both GPU and CPU inference.
About TitanML
TitanML enables machine learning teams to effortlessly and efficiently deploy large language models (LLMs). Their flagship product Takeoff Inference Server is already supercharging the deployments of a number of ML teams.
Founded by Dr. James Dborin, Dr. Fergus Finn and Meryem Arik, and backed by key industry partners including AWS and Intel, TitanML is a team of dedicated deep learning engineers on a mission to supercharge the adoption of enterprise AI.