Supercharge Inference Server Throughput with Rust!

In the race to build amazing AI-powered applications, it is no secret that Machine Learning (ML) engineers spend most of their time and efforts on optimising their models and improving the quality of their outputs. Working in a fast paced industry with pressing deadlines, they usually overlook the importance of creating an efficient inference server. As a result, they end up hacking together a poorly designed inference server that doesn't do justice to their amazing models.
Since the inference server sits between the user and the model, its poor performance would offer users a poor user experience either through slow response times and low capacity. To use an analogy, just imagine the absurdity of listening to high quality Audiophile music with your low budget supermarket earphones! Your inference server is just like your earphones, you can't enjoy the high throughput (how many requests a system can process in a given amount of time) and low latency (time the system takes to respond to a single request) of your models if your inference server is inefficient!
We're going to step through the mind of a engineer who is trying to deploy their language model to production - why their first instincts may not be the best and how they can use Rust to supercharge their inference server.
ML Engineer's Journey building a New Chat Bot
Initial Solution
Let's pretend you are an ML Engineer who is working on a new chatbot for a customer facing website. You have spent the last few weeks training a new language model and are ready to deploy it. It's a masterpiece and you've got highly performant benchmarks. You're running tight to deadlines and your product owner is breathing heavily down your neck. But armed with your benchmarks you present your work and they are delighted. You now need to get this model into production fast. The last step is creating a user interface to the model - an inference API.
You're familiar in Python so look to its stack and see there are some exciting options to build with: Flask, FastAPI, Django, etc. From reading online you see most buzz around FastAPI, so you select that and manage to follow the relatively simple setup and produce a working API. You're happy with your work and deploy it as the interface to your model. You confidently inform your product owner who is delighted and start planning out your next holiday with the massive performance bonus sure to come your way.
Unexpected Issues
A couple weeks go by and you receive feedback that the model is not performing as expected - it's slow and customers are complaining. You're confused as your benchmarking showed how fast and performant your model was. You start to dig into the issue and realise that the API is the bottleneck. You calmly inform your product owner you'll sort it out.
You see that the problem is that the API is pushing prompts to the model individually although your model is capable of processing a number of prompts simultaneously. You then start implementing some batching in the API, collating requests to the API together so you can maximise the throughput of the model. This is done by spinning up an async (asynchronous) Python thread with a queue to batch requests (batching daemon). Each route handler of the API then pushes its requests to this thread, which is pushed to the model once it is filled. You then write out some testing, deploy the new solution to production and inform your product owner about your impressive fixes you managed to turn around in a week.
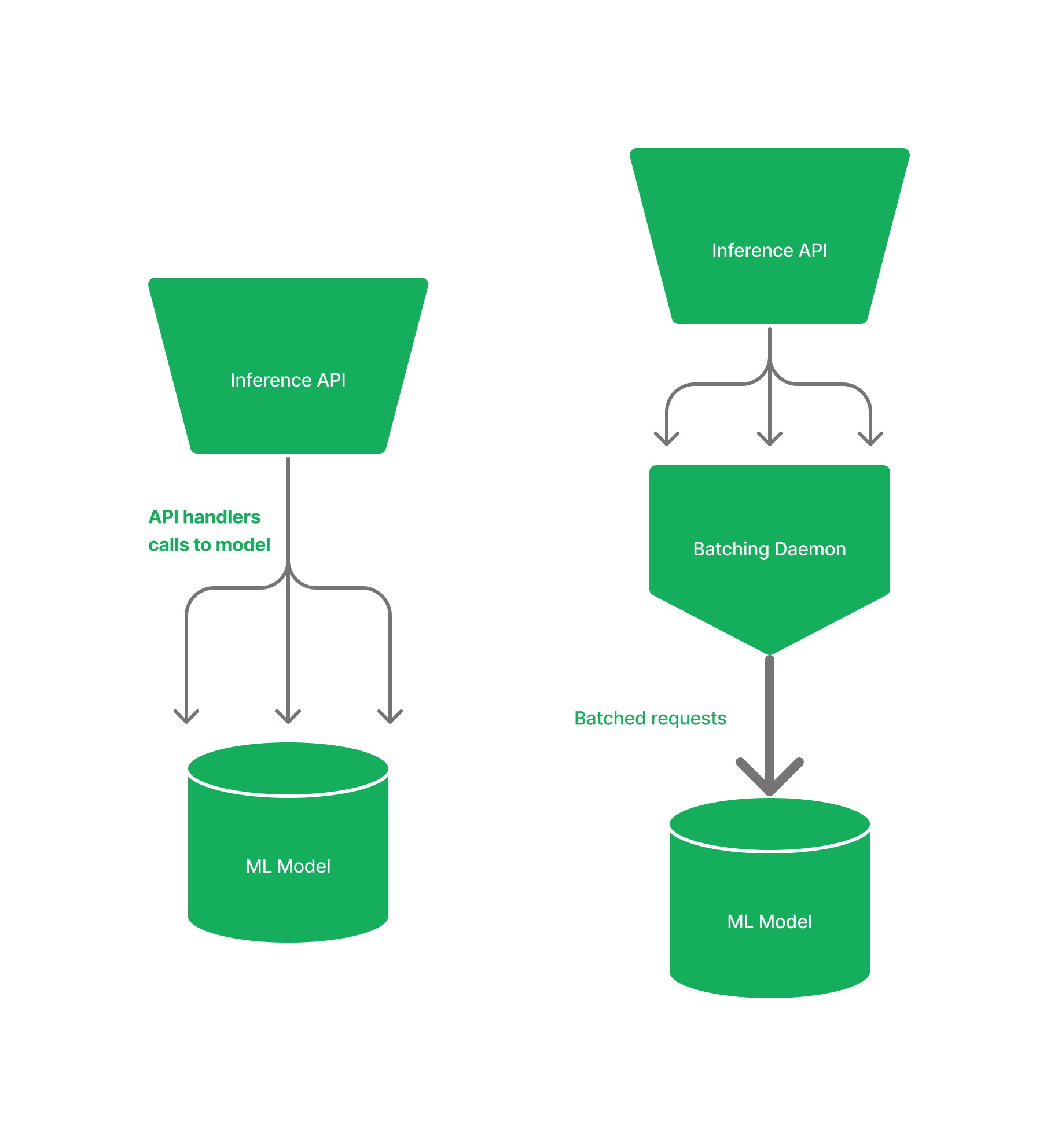
Problems Persist
A few days go by and to your dismay, your product owner comes back and says the fix has not worked as the number of complaints from users is persisting. You try to explain the nuance that the problem is not your model but the inference server, which is slightly out of your expertise. Your superior doesn't want to hear it. They only care about the customer complaints and getting out of hot water with their bosses. It's back to the drawing board and you try to understand why this batching isn't as effective as you thought.
From further research you start to discover the pitfalls of the simple Python API framework. You read that Python async library is non-preemptive: simply meaning that while an async task is running, nothing else can run. Furthermore, when async programming Python still uses an underlying thread or process for the event loop. This means that if you have blocking or CPU-bound code in your async application, it can potentially affect the performance of other asynchronous tasks running in the event loop. So your batching approach when implemented in Python is not as clean or simple as you thought. Then the questions start rolling in: do you rip it up and start again? Should you change tech stack? Are there other solutions out there? How long will this take?....
While you've been distracted all other projects you were meant to be doing are on hold. Other product owners are not happy, there is no obvious solution and you are going to have to tell your product owner that the benchmarks you quoted are not going to be met. You're not sure what to do and start to panic, the holiday you were planning is now a distant dream.
You may dismiss this warning as hyperbole but this is currently happening across the industry. ML Engineers are having to hack together solutions to get their models deployed. They are not experts in API development and do not have the time to be aware of the pitfalls. This is completely understandable as they are ML Engineers not DevOps/Software Developers!
How can we get to a solution?
Let's take a breath and step back from the problem. We have a model that is performing well but the inference server is not. We need to find a way to maximise the throughput of the inference server without hitting the pitfalls of Python async. So what would the ideal solution look like:
- Fast: We want to maximise the throughput of the ML Model so we can serve as many requests as possible. To do this we need a fully async server that can effectively batch requests to reach a high throughput.
- Safety: In implementing our async batching server we want to be thread and memory safe, so requests are returned correctly.
- Thread Safe: We want the server to be able to handle a large number of requests concurrently while accessing the same ML model. Therefore, it is imperative that the server is thread safe, so we don't end up in race conditions, deadlocks, or other unexpected behaviour.
- Memory Safe: We want to avoid memory leaks and other memory related issues that can cause the server to crash or subtler bugs such as incorrect responses being returned.
- Speed of Iteration: As stressed the typical ML Engineer is inundated with deadlines and projects, so we need a solution that is easy to implement and maintain. We don't want to have to spend weeks learning a new languages or framework to get our model deployed.
So What Language or Frameworks Fulfils This?
Sadly, like most things in life there is no perfect solution. The most common languages an ML Engineer would typically work with are Python, R and maybe Java/Javascript. None of them are inherently Thread Safe. For instance, Python has a global interpreter lock, which only allows one thread to run at one time (per process). On the other hadn, the safer and more performant languages such as Rust or Go may be unfamiliar to the typical engineer and would take a longer time to develop in. It seems that there is a tradeoff between spending more time learning an unfamiliar new language and accepting substandard performance.
Now we know the pitfalls of building an inference server, let's choose the best tool for the job. The standout languages for this job are Rust and Go.
Rust is a systems programming language that runs fast, and is purpose build for async programming guaranteeing thread and memory safety. Although Rust is a compiled language and can be more time-consuming to write, this is offset by less time fixing runtme errors and increased performance at runtime.
Go (or Golang) is a statically typed, compiled programming language designed for simplicity and efficiency. It features a built-in concurrency model (Goroutine) and a rich standard library, priding itself on its useability.
Both are fast, safe and have a number of web frameworks to choose from. Comparing the two, Rust has a steeper learning curve but is safer. This is due to the strictness of the Rust compiler and other safeguards in Rust such as reference lifetimes. The simplicity of Go to learn leading to a slight trade off in safety/performance for speed of iteration. We are ignoring speed of iteration for now so we are going to pick Rust as our language of choice.
What do other people think?
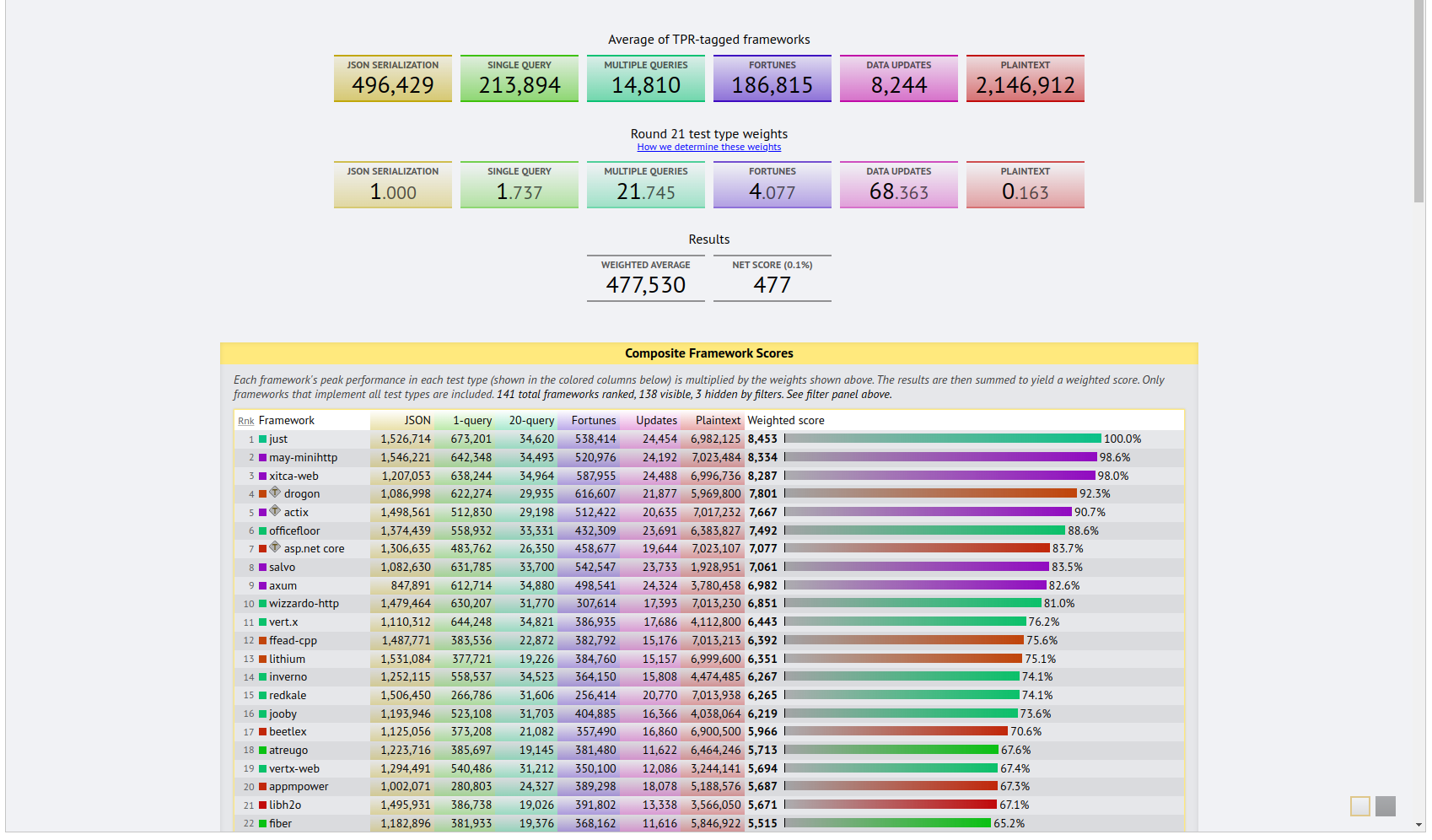
Naturally we're partial to Rust but we would need to evaluate if it is fit for purpose? We can start by consulting third party independent body: Techempower, who benchmarked hundreds of web frameworks. From their most recent testing, Rust frameworks have consistently scored highest across the board (color coded purple). Specifically, the Rust frameworks excelled at the multiple queries which is the most relevant to inference server throughput. So it seems like Rust is a good choice.
![]()
Framework Choice
Similarly to Python, there are numerous web frameworks out there in Rust which are easy to work with such as Salvo, Axum and Actix. We chose Axum which is built on top of Tokio, Rust's most popular async runtime. So this enabled us to implement batching requests truly asynchronously using Tokio ecosystem.
Load testing
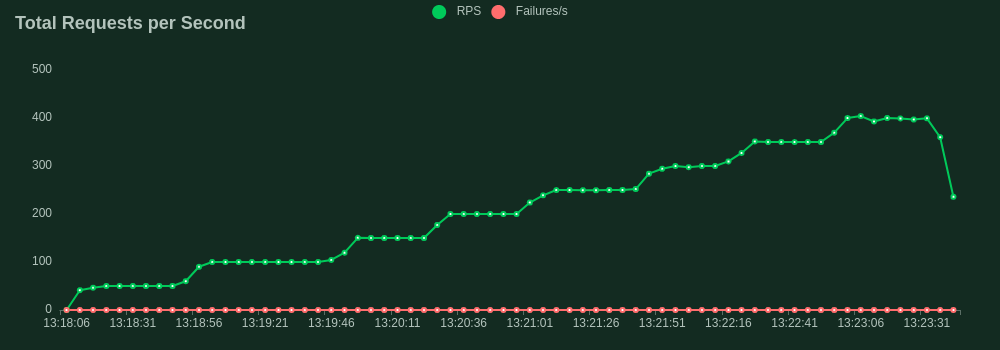
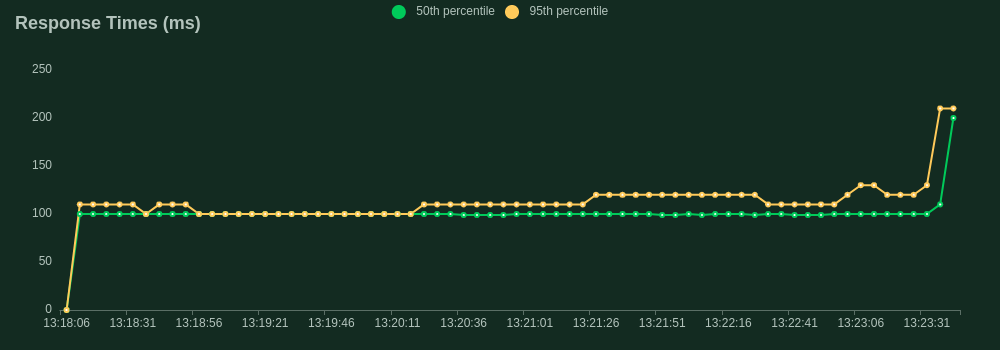
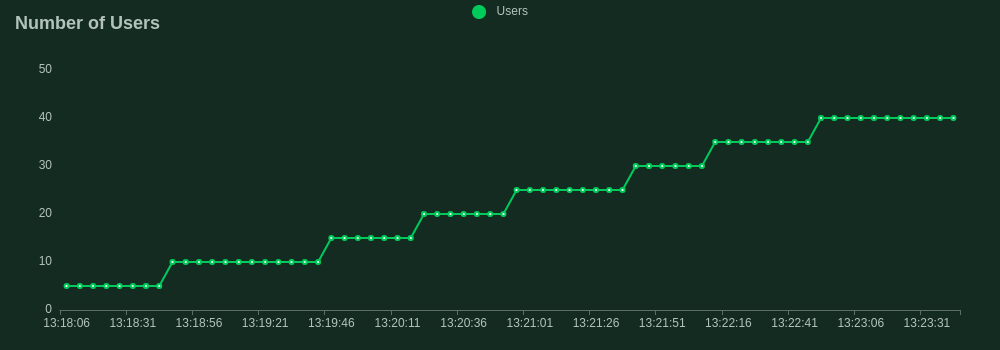
Now we have our ideal inference server we want to test its limits before we can feel confident about deploying it to a real-world production environment. We will use the FastAPI framework in Python as our control to compare the performance of Rust. Both servers implement the same batching logic and were ran with the same 125 million parameter model, on the same machine, with the same configuration. We used Locust to facilitate the load tests.
Takeoff Configuration
- Model name: opt_125m
- Backend: fast-ct2
- Device: cuda (Nvidia GA106 [GeForce RTX 3060 Lite Hash Rate])
- Max batch size: 50
- Batch timeout: 100ms
- Request body:
{
"text": "Hello World, what is your name dog?",
"max_new_tokens": 10
}
Our load test spun up 40 concurrent users all firing requests as fast as possible to the server. Each user dispatched prompts to our /generate endpoint with a max_new_tokens of 10 to ensure consistency of output. The throughput was quantified by the rate of simultaneous requests the server could handle. This is slightly different from the frequently used tokens per second statistic to quantify benchmark model throughput and is a more specific metric focusing on the API's performance.
Throughput Results
- FastAPI: Maximum 40.2 requests per second (RPS)
- Rust Maximum 404 requests per second (RPS)
So we see a 10x increase in throughput with the Rust server. Wow! Maybe it's time to stop settling for substandard performance and start using Rust!
The full results of the load test are included in the appendix.
How is This Useful for ML Engineers?
This is a great result but we have ignored one of our key criteria to achieve this solution: speed of iteration. How do we expect an ML Engineer to learn Rust and start building Rust servers on top of their normal responsibilities? The answer is we don't and that's why we built Titan Takeoff Server! The Pro version of Titan Takeoff Server features a fully optimised Rust batching inference server to maximise the throughput of your models. This is a great example of how TitanML is helping ML Engineers focus on what they do best: building amazing language models and not worrying about deployments. Get in touch with us at hello@titanml.co to find out more about Takeoff and how it can help your business.
About TitanML
TitanML enables machine learning teams to effortlessly and efficiently deploy large language models (LLMs). Their flagship product, Titan Takeoff Inference Server, is already supercharging the deployments of a number of ML teams.
Founded by Dr. James Dborin, Dr. Fergus Finn and Meryem Arik, and backed by key industry partners including AWS and Intel, TitanML is a team of dedicated deep learning engineers on a mission to supercharge the adoption of enterprise AI.
Appendix
FastAPI Load Test Results
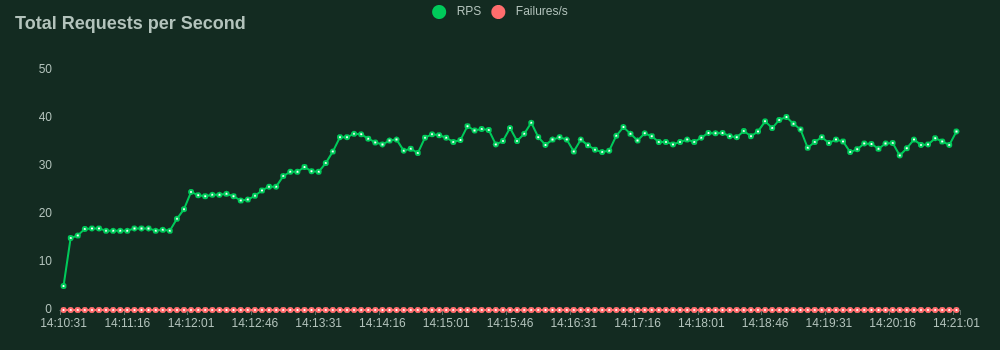
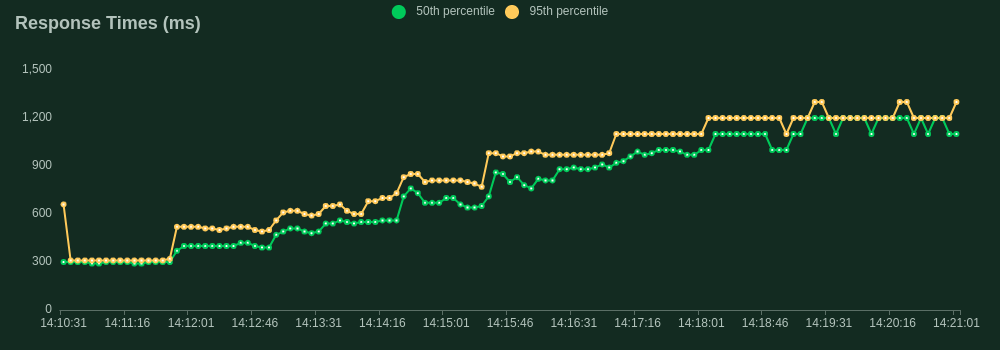
Rust Load Test Results