Building with Takeoff: Organising LLM Tournaments

It is no secret that we built Titan Takeoff to make it easy for you to make inferences and deploy your models. With the nitty-gritty details of deployment and technical complications of running massive models abstracted away, you can stop worrying about performance issues and instead focus on what really matters - how to select the best model for your use case and get your preferred model to product quality outputs.
We recognize that the model selection and prompt engineering process are critical as this can influence the user experience and satisfaction with your applications. We also know that this process is complex, usually requiring many rounds of repeated experimentation.
Simplified Model Selection and Prompt Engineering with LLM Arena

In order to help you with this challenging process, we have built the LLM Arena. This interactive web application allows you to quickly compare the outputs across different models, as well as prompts. We’ve abstracted away all the technical complexities of deploying other models so you can use our simple interface to compare different models and prompts, speeding up the experimentation and development of your AI-powered application.
Knockout Tournaments

In this article, we will be featuring one of the modes of LLM Arena, Tournament Mode, where users can host a knockout-style tournament for Large Language Models, allowing them to judge and compare outputs between various models and find the ultimate winning model that produces the best output. It is a fun but also useful way to select the most appropriate model.
How the Tournament works

- Model Selection: You can pick the number of models to be included in the tournament (4 or 8) and choose which models to have. It will automatically create a tournament bracket with your preferred models.
- Knockout style Tournaments: Two models face each other in each battle, with the winner advancing to the next round and the other being eliminated
- Blind Model Test: The names of the models are not revealed until the tournament ends to reduce bias when judging models.
- Efficient Model Orchestration: The Tournament round is built with Hades, a Kubernetes-based orchestration system that efficiently spins up and down models on demand. It saves you the need to deploy many models simultaneously, which would be extremely expensive. It also saves you the hassle of manually spinning up and down models compared to just deciding to spin up one or two models at the same time.
Using Tournaments to Select the Best Model
Let’s say we’re an Education Tech company called NextGen Education. One of our internal tools is an AI-powered application that creates course materials for teachers and instructors. We’re looking to create a five-day lesson plan for high school students learning how to code with Python from scratch.
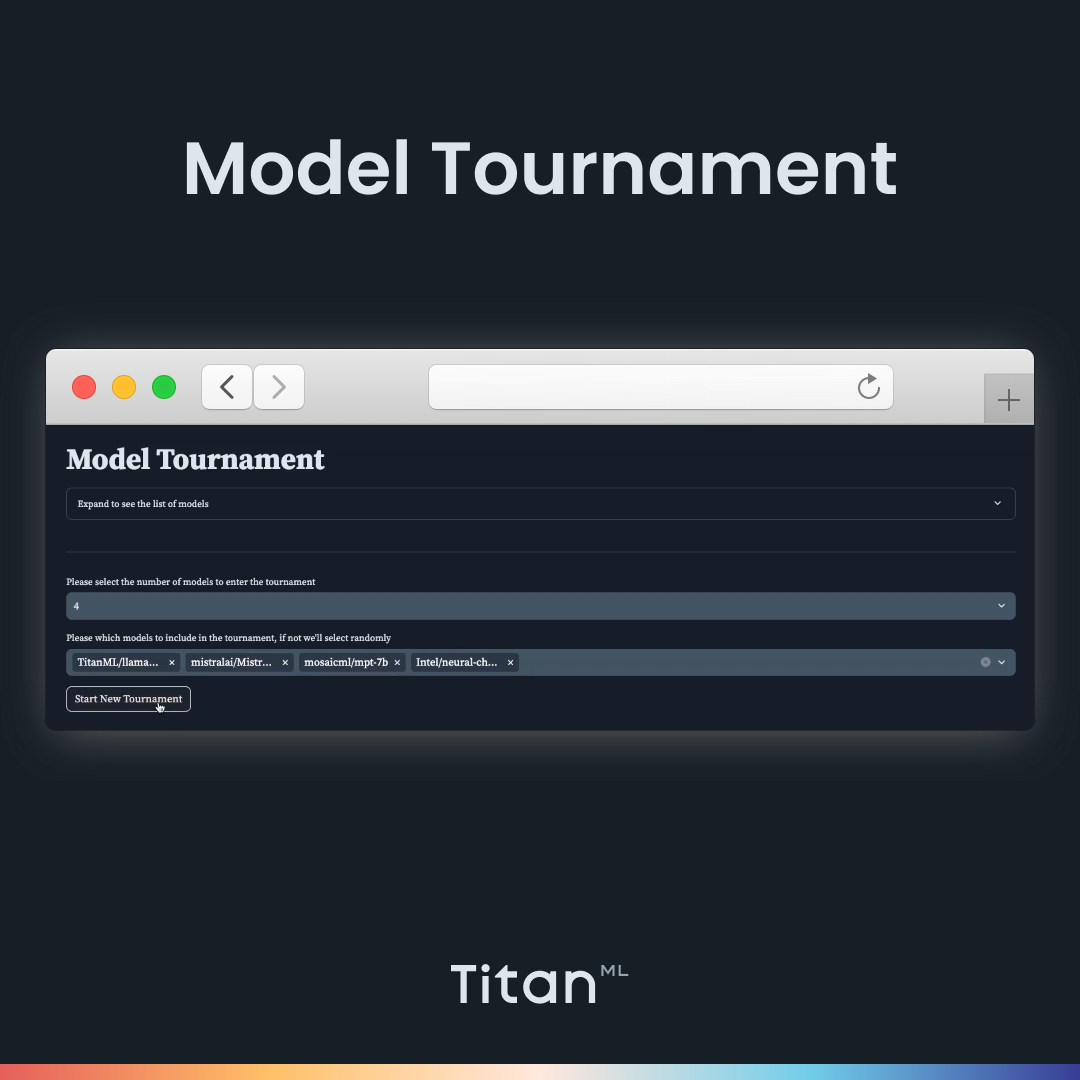
We have calculated that we have just enough budget to deploy an optimized 4-bit 7 Billion parameter LLM, but are not sure which LLM would be the most appropriate for our specific use case, so putting our four shortlisted 7 Billion models in a tournament to compare outputs and decide a winner sounds like a perfect way to determine how it works.

We can select four 7B models to compare. Here, we choose Intel’s Neural Chat, Llama-2, Mosaic ML’s MPT, and Intel’s NeuralChat. Then we can start the tournament. It pairs up the models into tournament brackets and loads up the first two models. In order to be impartial, the names of the models are not revealed until the end of the tournament. Let’s paste in our prompt (Create a five-day lesson plan to teach high school students how to code with Python from the very beginning).
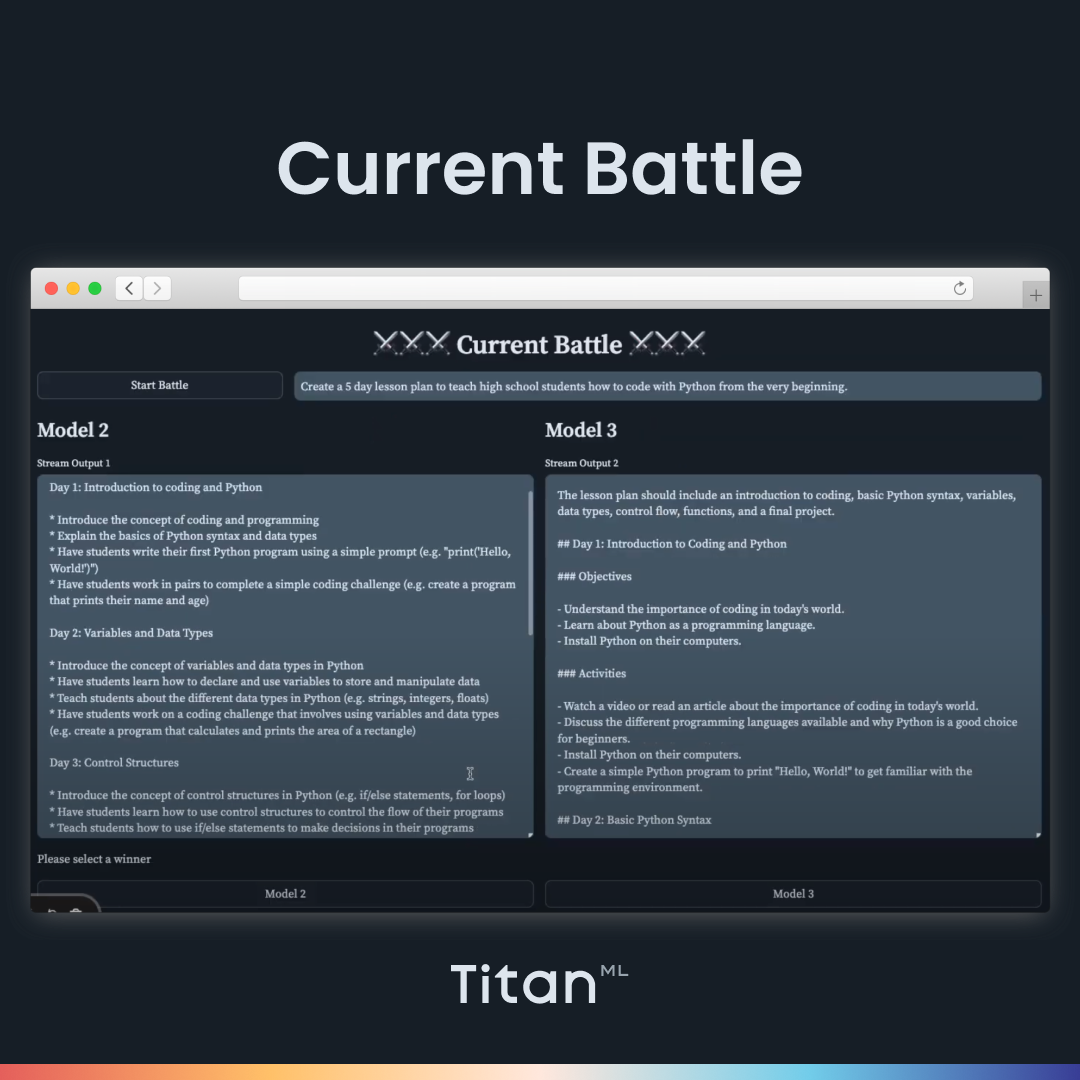
Here, we can compare the outputs of the two models side-by-side very easily, evaluate their outputs, and pick the best one to advance to the next round. You will have a chance to assess each shortlisted model through the tournament bracket. Before each battle, our orchestration system, Hades, will spin down the old models and spin up the new models dynamically, saving you the need to deploy all the models at the same time.
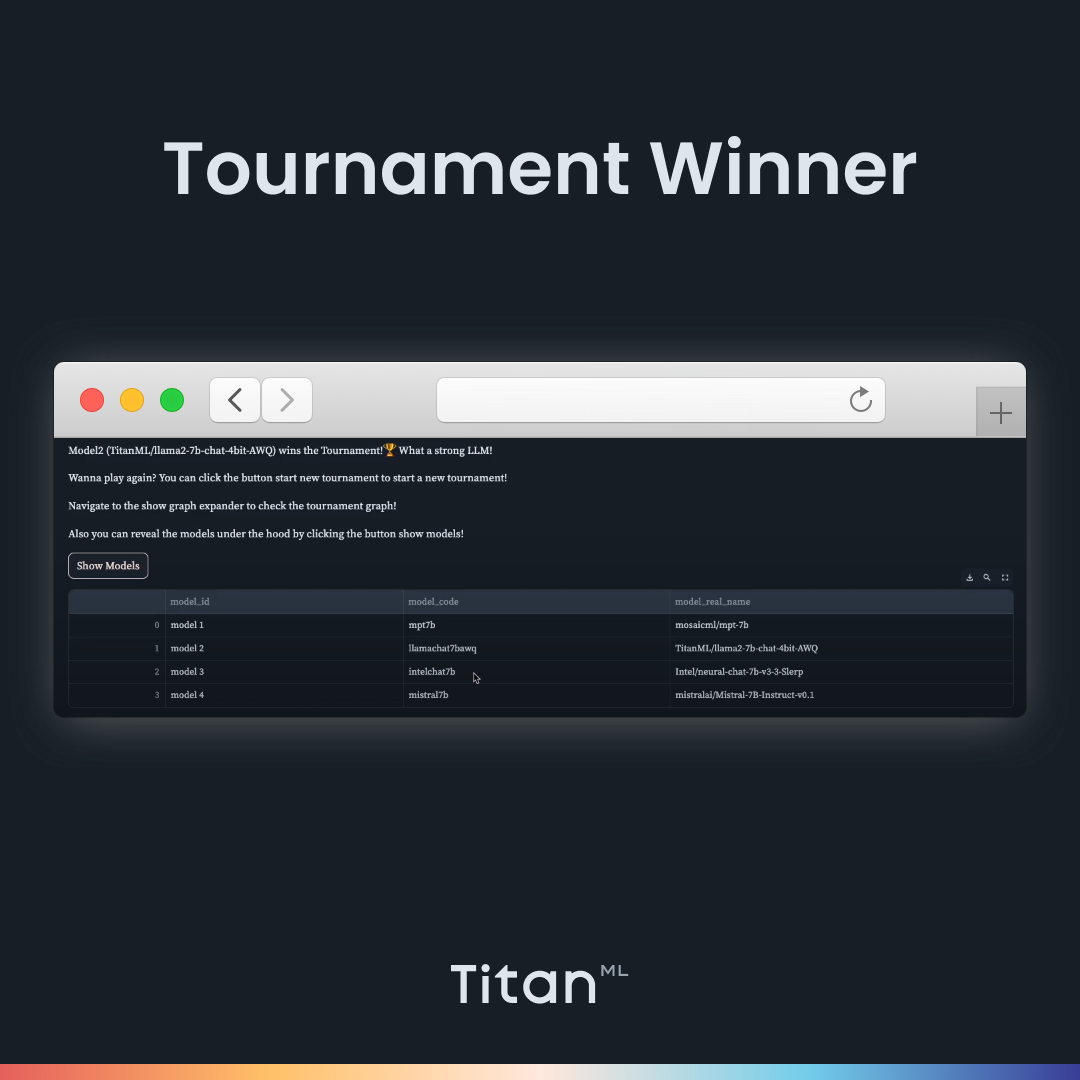
At the end of the tournament, the names of each model will be revealed, as well as the winning model. Congratulations, you have found a model most suited for your prompt. However, playing multiple tournaments is recommended before you select a suitable model to ensure outputs are consistent, reliable, and appropriate. You should battle-test your models to ensure that your models behave properly when receiving inappropriate or ambiguous requests.
Conclusion
Selecting a model best suited for your use case is essential as it can determine the quality of your outputs and user experience with your AI-powered app. It usually requires repeated experimentation that may be troublesome and impractical without suitable tools. The LLM Arena, built on Titan Takeoff, bridges this gap by allowing you to focus on experimentation to select the suitable model by abstracting the complex logic of model orchestration. If you want to incorporate LLM Arena into your AI game plan, do reach out to us.
About TitanML
TitanML enables machine learning teams to deploy large language models (LLMs) effortlessly and efficiently. Our flagship product, Titan Takeoff Inference Server, is already supercharging the deployments of several ML teams.
Founded by Dr. James Dborin, Dr. Fergus Finn, and Meryem Arik and backed by key industry partners, including AWS and Intel, TitanML is a team of dedicated deep learning engineers on a mission to supercharge the adoption of enterprise AI.