
The pace of ML research is accelerating, and the amount of information available is growing exponentially. It's becoming increasingly difficult to keep up with the latest developments in your field, let alone the wider world of research. The TitanML platform incorporates the techniques from this fast-moving field to make it easy, fast, and efficient to build NLP applications. To help us keep up with the firehose of information, we can use NLP to summarise and answer questions about papers.
Here we present a platform that uses Arxiv papers to demonstrate two hallmarks of NLP applications: text summarisation and question answering. By leveraging the Titan Train finetuning & optimization platform, this whole app is built on readily-accessible, free to use, open source language models. Using the Titan Takeoff inference server, it's powered by a single GPU with VRAM capacity significantly smaller than the size of the initial models. In fact, this demo involves two google/flan-t5-xl models and one embedding model working hand in hand, each specialised to their task, and all trimmed to fit snugly together along with a vector database on a 24Gb GPU.
Outline
- Why finetuning?
- Summarisation
- Creating our Question answering (QA) model
- Optimisation & deployment
- Demo!
- Appendix: Model capability
Why finetuning?
The first thing you might think of when building an NLP application is to plug in to ChatGPT.
While it can be tempting to jump into building a shiny front end, and start calling out to openAI's models, there are many reasons this may not be ideal for your application.
- Cost per query: When you hit the API, you are charged per query. As your application scales, this can rapidly become expensive.
- Data Sovereignty: While this example uses publicly available data, your application might handle documents that are more sensitive and would ideally stay within your own system,
- Uptime: if ChatGPT goes down, your site goes down with it — self hosting your own models is the only way to control your uptime.
- Customisation: ChatGPT is a generalist, and while it is very good at what it does, it is not specialised to your application.
- API Stability: OpenAI switch out their models all the time, and deprecate old models. To own the solution yourself, you need to be able to control the models you use.
Luckily, there is a vast array of open source, easy to download models available to try out. While they may not be as good as ChatGPT initially, there are a few tricks to make them competitive for your specific use case. Remember, ChatGPT is the ultimate generalist — a lot of its capacity is wasted when we know exactly the task we wish our LLM to enact. To specialise our models, here for summarisation and answering questions based on text, we use a process called finetuning.
For all the tasks in this app we start with the same model, Google’s Flan-T5-XL (28Gb in float32, 3b parameters), and fine-tune it once for each of our applications. Note that these two specialised models are still smaller than the rumoured size of ChatGPT1.
- For summarization, we train our model to transform full papers into abstracts using the ccdv/arxiv-summarizer dataset
- For question answering we train our model using a custom Arxiv paper question and answer pair (dataset). In the table at the end of the article you can see the difference that fine-tuning makes
Summarisation
As an NLP task, summarisation has its challenges. By its nature, the initial text is usually large, and much longer than the context length of most LLMs - particularly the open source ones. In this app we employ a technique of rolling summarisation, to recursively chisel down the text until it can be managed by our models given context length, meaning our final summarisation will have incorporated the whole document. To do this, we chunk our text into overlapping pieces, each chunk is summarised individually, and the results concatenated. While the running text is larger than the context length, the process is repeated.
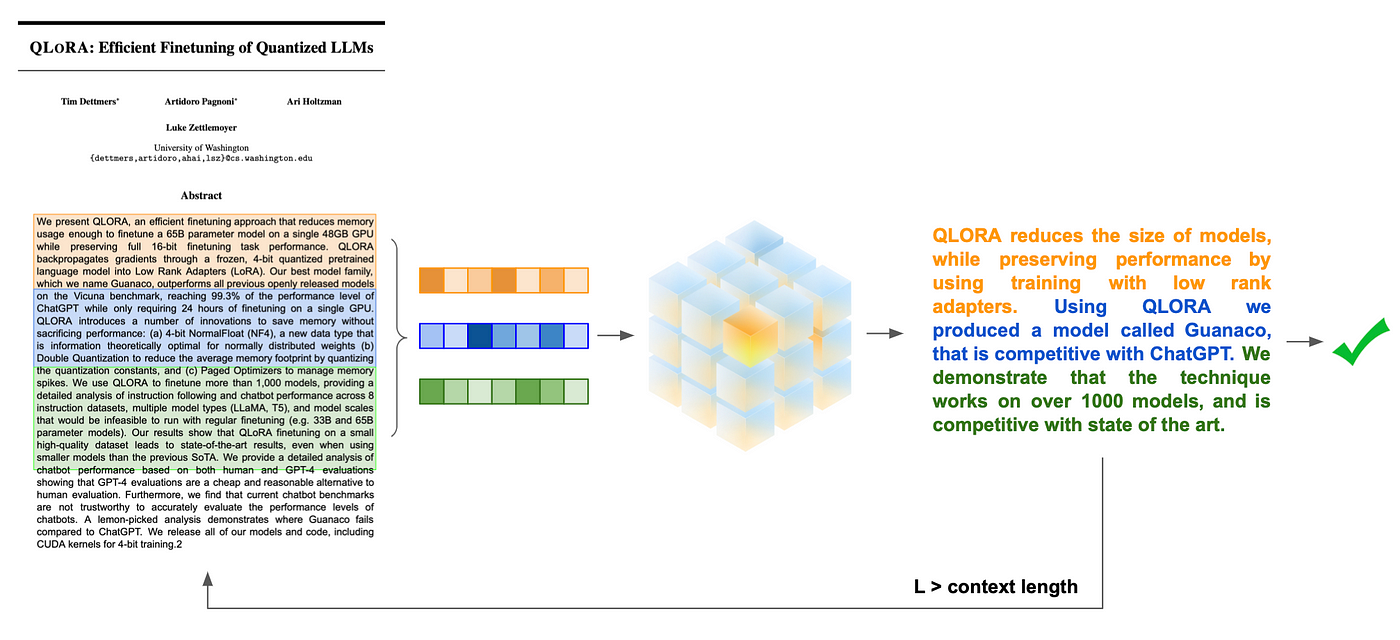
Creating our Question Answering (QA) model
Question answering can also become tricky when the subject text is much larger than the model context length. To address this, we first split and embed our text corpus into a series of vectors using a sentence transformer. User queries are also embedded and compared for semantic similarity against the embedded text to fetch the most relevant parts of the original document. These can be concatenated into a context that is accessible to the model, while also providing the most important information available.
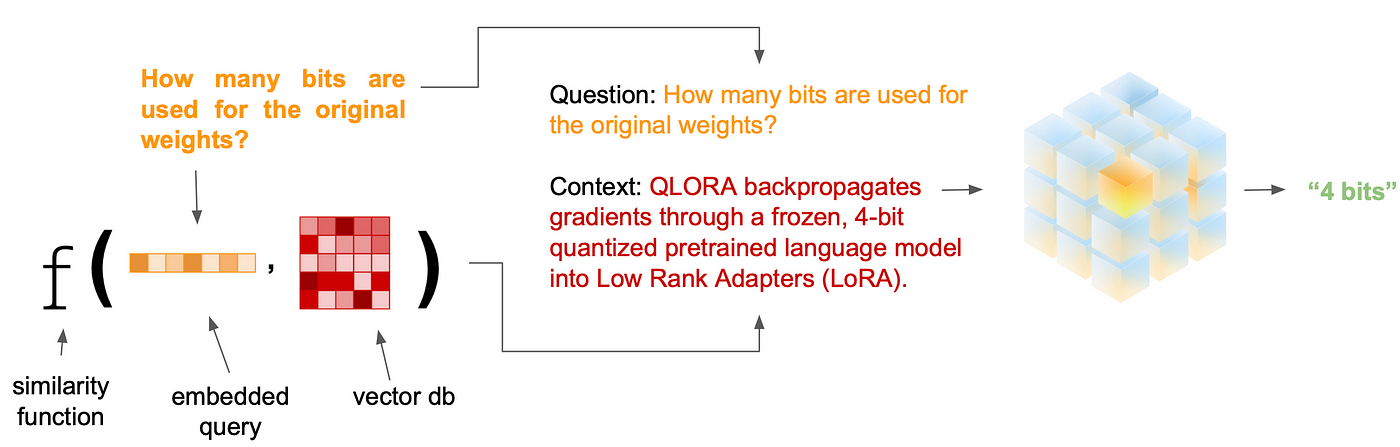
Optimization & deployment
LLMs are unwieldy due to their massive size. Many of the more capable models cannot fit into consumer hardware, and without GPUs they are too slow to run for any realistic application.
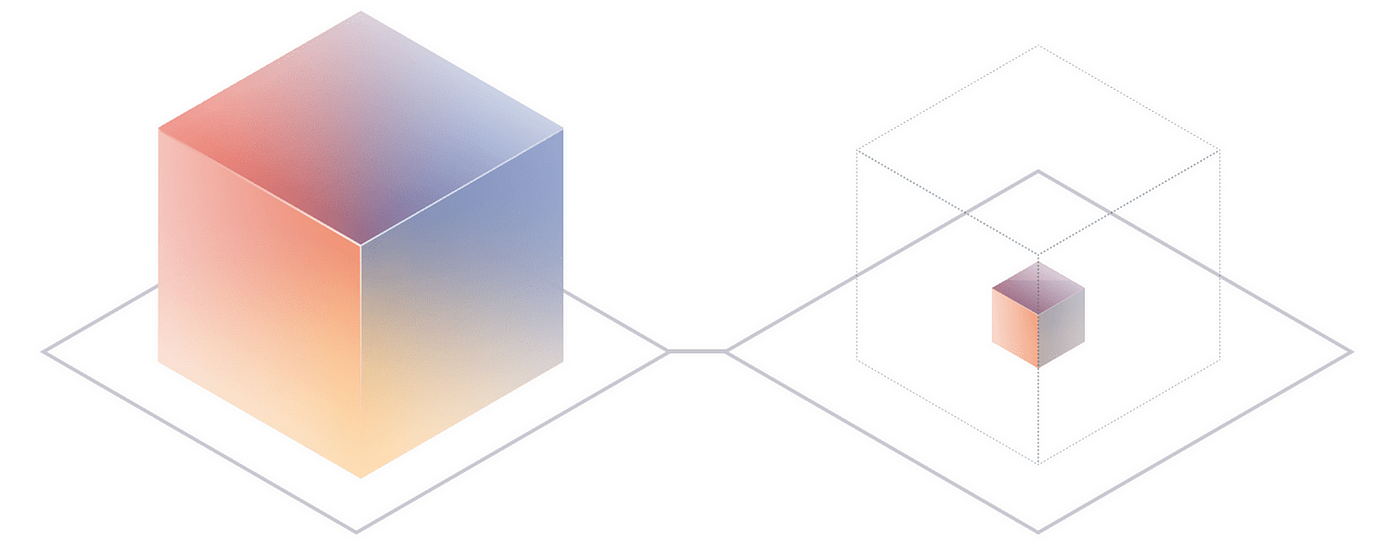
To make it possible to fit and run both our models we need to use quantization to trim the amount of space used to store the model values, at a small accuracy penalty. The technology has advanced so as to minimize the effects of this reduction, and the outcome is the ability to fit both of our XL Flans (28Gb each) into our 24Gb GPU, with room to spare for runtime values, our embedding model, and embedding lookups. This means we aren’t forced to use a less capable model for one of our tasks.
This project required a compromise between model capability and what can fit onto our GPU device. With the TitanML platform we attacked this problem from both angles:
Using Titan Train we were able to opt for smaller sized models, knowing we can make back the performance loss by using finetuning to specialise the model for the task at hand.
iris finetune --model google/flan-t5-xl \
--dataset ccdv/arxiv-summarization \
--task language_modelling \
--text-fields article \
--text-fields abstract \
--name flanxl-arxiv-summarizer
And with Titan Takeoff, we explored models beyond our hardware's unoptimized capacity by employing quantization techniques to fit larger models into memory, and runtime optimisations to drastically accelerate model inference.
iris takeoff --model flanxl-arxiv-summarizer --device cuda --port 8000
Demo!
Now that we've given you a taste of what's going on under the hood, you can try it out for yourself. The demo is live here2. It's running two Flan-XL models, and a MiniLM embedding model, all on a single A10G GPU-enabled AWS instance.
- The models are deployed with the TitanML Takeoff server, which is a lightweight inference server that can be deployed for rapid inference on CPUs and GPUs. For more information about the Takeoff server, see our github.
- The instance we've used here is a
g5.2xlargeinstance, which has a single A10G GPU, 8 vCPUs, and 32Gb of RAM. For more information about deploying the takeoff server on AWS, see our article - See the following for the speedups that we attained using the Takeoff server.

Iris takeoff layers a number of runtime optimizations that can drastically speedup inference against naive GPU execution.
Thanks for reading, and we hope our paper summarizer helps you keep up with the latest in AI research!
To emulate this project yourself see the code here, and to start applying cutting edge ML performance and latency optimisations to your own projects and models, checkout the TitanML platform! If you have any questions, comments, or feedback on the TitanML platform, please reach out to us on our discord server. For help with LLM deployment in general, or to signup for the pro version of the Titan Takeoff Inference Server, with features like automatic batching, multi-gpu inference, monitoring, authorization, and more, please reach out at hello@titanml.co.
Appendix: Model capability
See the following table for a comparison of the performance of the raw model and the finetuned model.
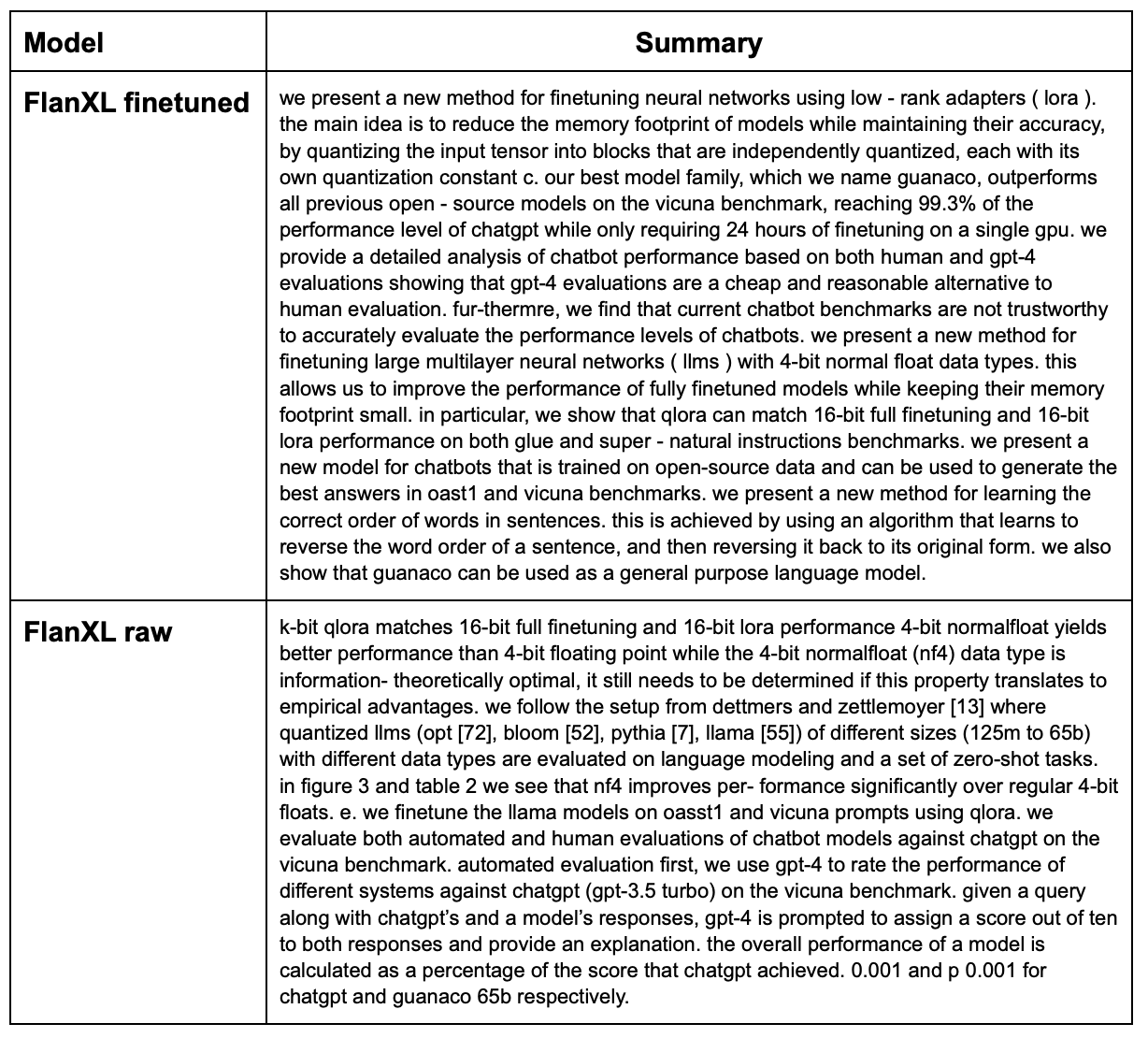
As you can see, a model finetuned on a corpus of Arxiv papers has much better comprehension of scientific text than its prior base model.
Footnotes
-
Numbers get thrown around all the time, but the GPT-3 model the gpt-3-5 model powering the ChatGPT free tier is based on had 175b parameters. Given the generation speed, it's likely smaller than this, though nobody knows how small. ↩
-
Depending on the time of reading, the demo may be down. To build and run the demo yourself, check out the instructions on the github. ↩