Massively parallel hardware accelerators, such as GPUs, have played a key role in providing the computational power required to train modern machine learning models, especially recent Large Language Models (LLMs). Training these models can still take several months, regardless of the amount of resources allocated to them. The problems, however, don't stop at training - these models are so large and unwieldy that just interacting with and inferring from them can also be a challenge. This is particularly pertinent for language modelling use cases which need almost real-time responses to not frustrate users - no one wants to talk to a chatbot that takes a few seconds to send each word. Now imagine how tricky this gets as you scale your application to thousands of concurrent users! Fortunately, in these situations where the models are too big or the request traffic too high, we can turn back to the same hardware that built these models in the first place: large, massively parallel clusters of GPUs.
Distributed computing
To truly appreciate the benefits of multi-gpu inference, we need to understand some of the fundamentals of distributed computing.
Amdahl’s law and the limits of parallelisation
To begin, we need to start with a reality check on the computational speed ups available to us through parallelisation. Equation 1 is Amdahl’s law, and relates the fraction of our program that can be parallelised with the number of parallel nodes we have available, to calculate our potential speed up. This speed up is a theoretical limit as it doesn’t include any communication costs between our processes, which will apply heavily in our multi-gpu environment for result reconciliation and aggregation.
Equation 1:
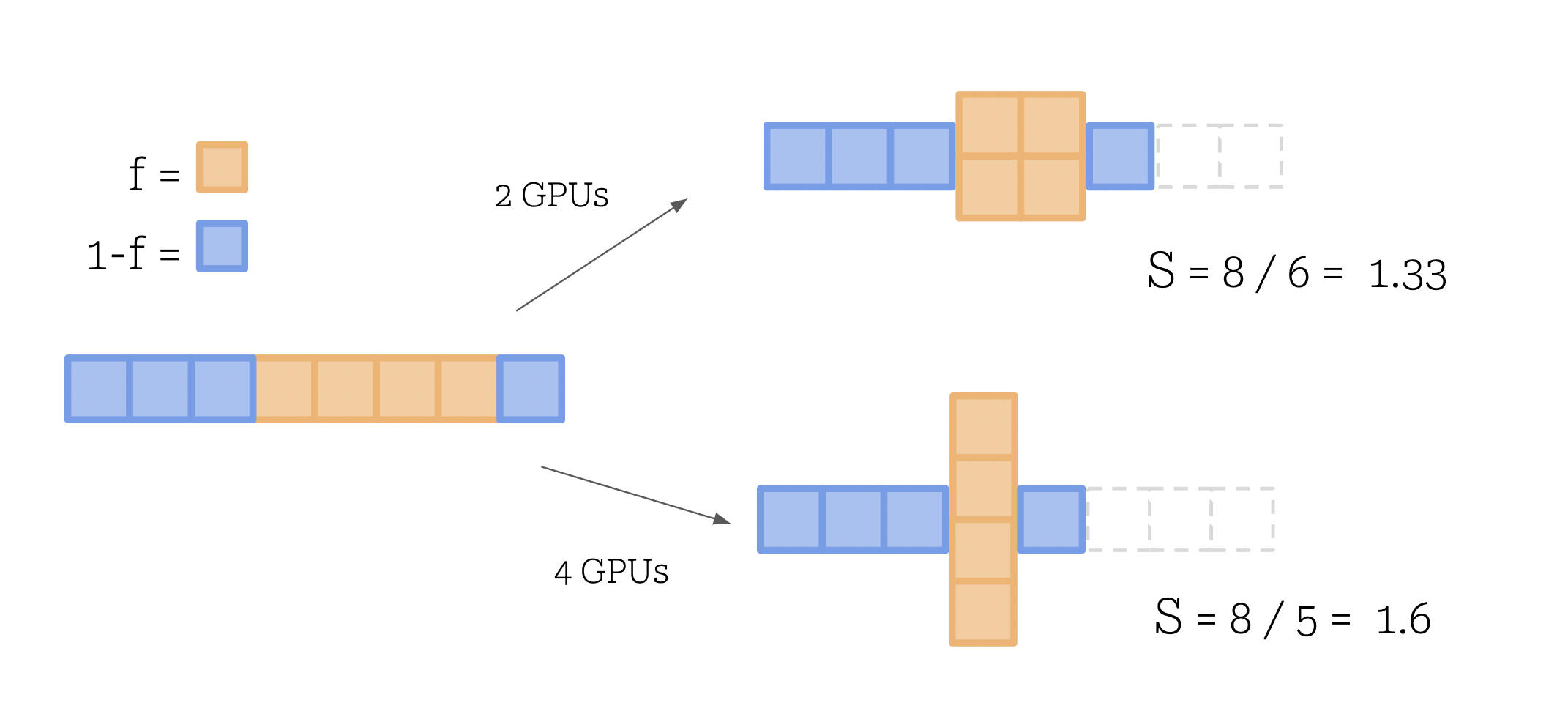
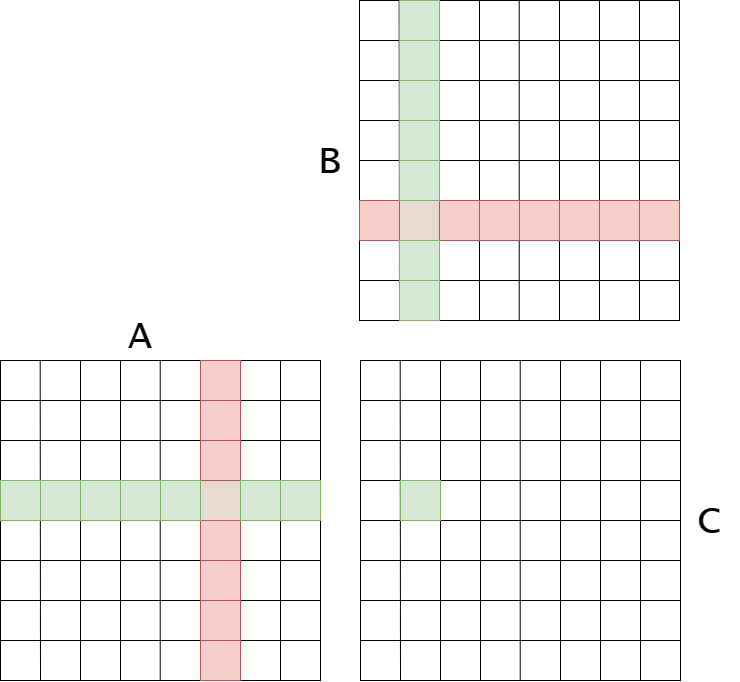
Here we visualize distributing our ML program across a number of parallel devices. Parts of the program (in blue) must inevitably run in series, such as data retrieval and preprocessing, initialising the parallel nodes and closing the program with some postprocessing. Likewise, the orange blocks represent computations that can happen simultaneously, such as passing a single input through our model, and we are capped by our available nodes as to how many units can run simultaneously. If these units exceed our number of devices, they must execute consecutively on our devices.
This means using the absolute theoretical limit, when splitting our program over 2 GPUs, we cannot expect to pass the limit of half of the original time taken - and should expect a time somewhat greater than this due to the serial parts of our program, pre- and post-processing, plus the communication overheads required between our parallel processes.
So, while any speed up is good news, to appreciate the real appeal of stacking our GPUs, we need to segue into some more inference metrics.
Latency vs. Throughput
Latency and throughput are two fundamental performance metrics used to grade computing systems, and while we usually want competitive values in both, our use case can prioritise one over the other.
- Latency: often referred to as response time, measures the time it takes for a single unit of data to traverse a system from source to destination - in the context of our LLMs this is the time we see between each subsequent token returning from our models.
- Throughput: on the other hand, quantifies the rate at which data can be processed or transmitted within a given time frame - for our LLMs this value describes our output tokens per second. Higher throughput indicates our system's ability to handle a larger volume of requests efficiently.
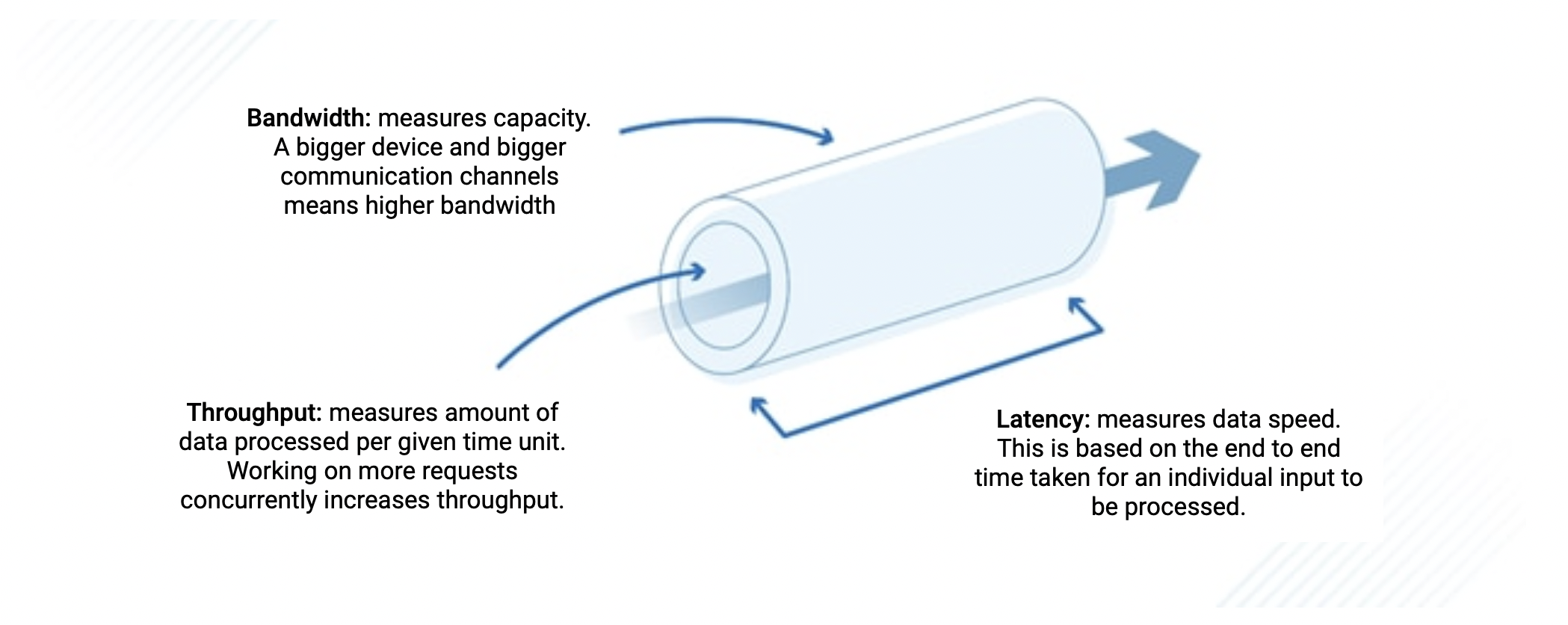
While these two values may appear similar and are, in fact, inherently interconnected (reducing latency typically leads to increased throughput), there are subtle ways we can tweak them individually.
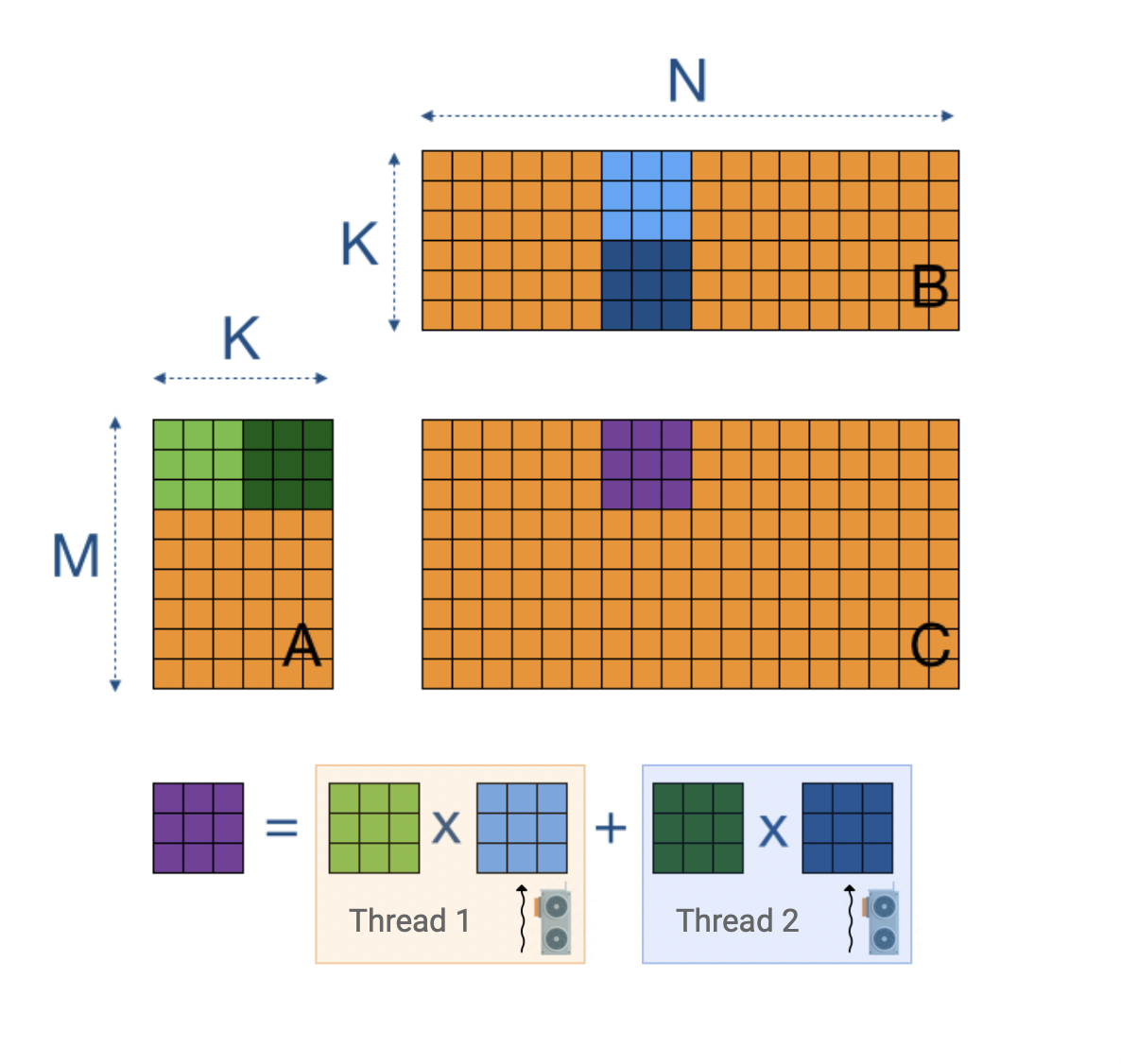
- Batch size: LLMs consist of numerous consecutive matrix multiplications, and when processed on massively parallel devices like GPUs, the time required to handle a batch of inputs through these operations is negligibly increased compared to a single input (to an extent). See
Fig 3: if we can process multiple inputs simultaneously, at low cost to the execution time, we can multiply the tokens passing through and outputting from our model per unit time - this is a big boost to our throughput. (Note: on a sequential processor like a CPU, these steps have to execute consecutively and you lose the benefit).
- Quantization: a lot of time is spent moving large chunks of data around to be processed in a system with limited bandwidth, causing queues and bottlenecks. One of the big advantages to quantizing our models, apart from allowing use of bigger models, is massively reducing the size of our data, and increasing the speed it can be transferred. This is a win for latency.
- Caches: There are many repetitious calculations that occur during the inference process, and if we can store the results of these calculations in a cache, we can save time by not having to recompute them. This is a win for latency, and improves our throughput in the process.
To summarize, latency measures speed and throughput measures volume - and the latter is where we're going to see our dramatic results! Bigger batch sizes is a significant opportunity for boosting our throughput, and allowing our deployed model to serve many users concurrently while keeping performance competitive. The problem is these batches need space to work with:
Fitting a model (and some space to work with) on our device
Firstly, lets calculate the raw size of our model:
And let’s see how these numbers look for some of the most popular models:
| Model | fp32 | fp16 | int8 |
|---|---|---|---|
| OPT-1.3b | 5.2 | 2.6 | 1.3 |
| Llama2-7b | 28.0 | 14.0 | 7.0 |
| Llama2-13b | 52.0 | 26.0 | 13.0 |
| Flan-T5-L | 3.1 | 1.6 | 0.8 |
| Flan-T5-XL | 12.0 | 6.0 | 3.0 |
| BERT-L | 1.2 | 0.6 | 0.3 |
| BERT-XL | 5.2 | 2.6 | 1.3 |
Table 1: Model sizes in Gb for different precisions.
Our first imperative for working with GPUs is that the model itself needs to be able to fit within the devices’ VRAM. So looking at the following range of common GPUs, we can see that for a Llama-7b at fp16, some GPUs are inaccessible and for Llama-13b at fp16 all but the A100s are unusable, unless we can find a way to split the model across more than one device. So our first lesson: for large models, it may be a necessity to split it across a multi-gpu backend just to be able to run it. GPU prices also grow exponentially with their size, so chances are you are more likely to be able to afford multiple smaller GPUs than a single large one.
| GPU | VRAM |
|---|---|
| 3060 | 12 |
| V100 | 16 |
| 4090 | 24 |
| A10 | 24 |
| A100 | 40/80 |
Table 2: GPU memory capacity in Gb.
Next we need to think about how much extra space we need reserved for our rolling calculations. There is a back of the envelope esimate1 that for a 13b parameter model, each token requires 1mb of additional space for continuous values. So a prompt of 128 tokens, with a desired generation of 128 tokens will require 256mb of additional space. This seems like a low amount, but that means a batch size of 48 would max out our 3060 GPU without even the model present!
But to increase our throughput and the amount of users we can serve concurrently, we know we need to up our batch size. This is the next argument for splitting our model across GPUs: it leaves more space on each device for running the inference on an increased amount of inputs.
Strategies for distributing across multiple gpus
There are a couple of ways we can approach our multi-gpu environment:
-
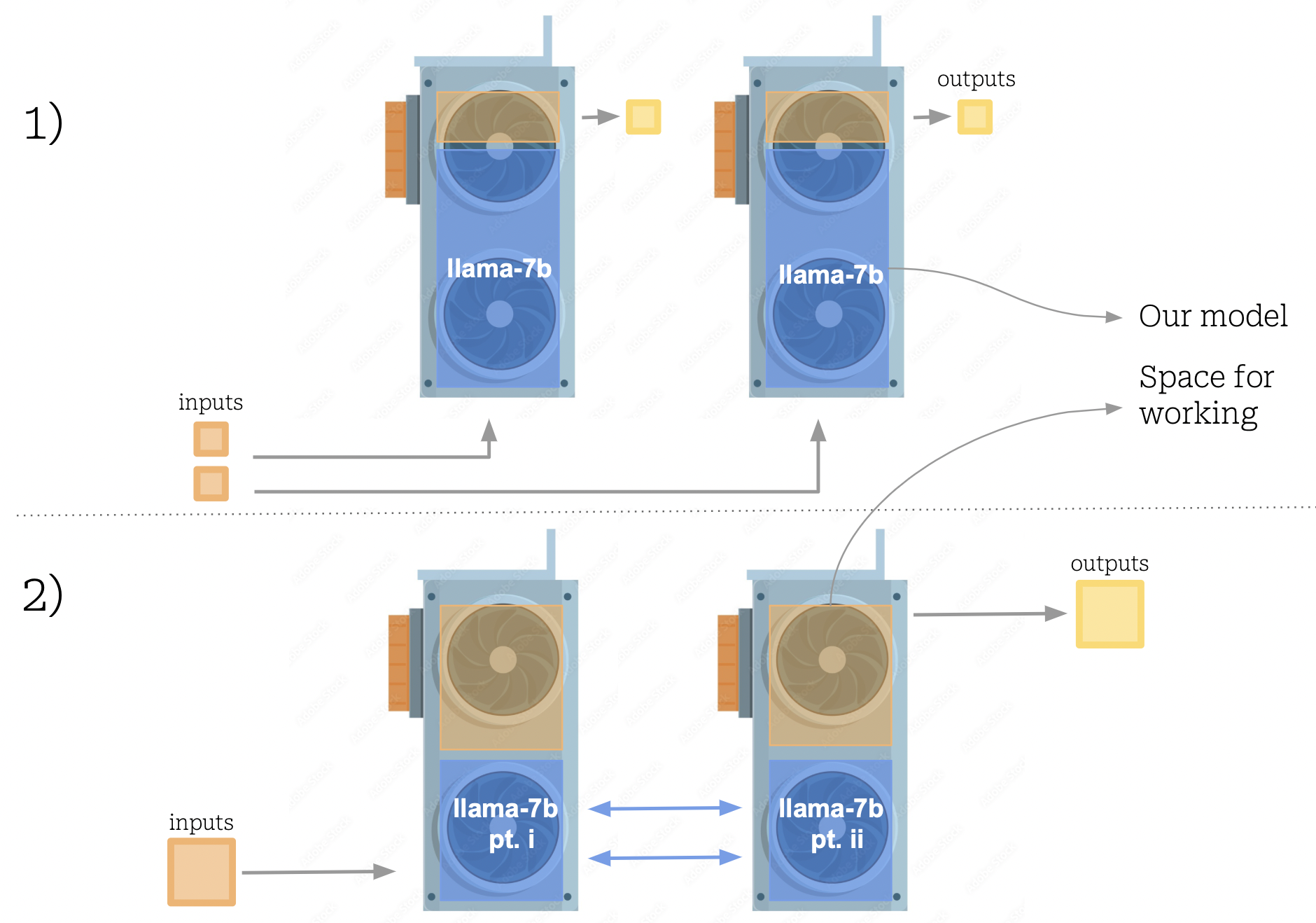
Repeat our model on multiple devices: this is the simplest approach, and will afford us throughput increases without any inter-gpu communication costs. The technique involves simply loading the model individually onto each of our GPUs, and using a queue system to distribute incoming requests to each of the models. The main advantage to this approach is simplicity, but some downsides are evident. For one, there is a lot of redundant information wasting precious GPU space by repeating the same weights across all the devices. This approach also stuffs a large model into each GPU, reducing the capacity left to fit in our runtime data, forcing us to operate at lower batch sizes.
-
Split our model: the alternative is to chunk our model and split it across the devices. This way is much more complex to code, and also comes with some communication overheads, as the model needs to costantly combine calculation outputs before moving on to the next stage. However, this way allows us to access massive models that can't normally fit on our available hardware, and also allows us to operate at much larger batch sizes, as we have more space to work with on each device.
The latter approach is particularly exciting: it is known that large models typically outperform their smaller counterparts, so if we can use our distributed hardware to unlock previously inaccessible models like llama-13b then this is a big win.
How to split a model: pipeline vs tensor (vs data) parallelism
Data parallelism is option 1) in the previous section, whereby different chunks of our data are processed in parallel on replicas of the model. For reasons previously discussed, we wish to split our model across our devices and there are a few ways we can achieve this, the most common being pipeline or tensor parallelism.
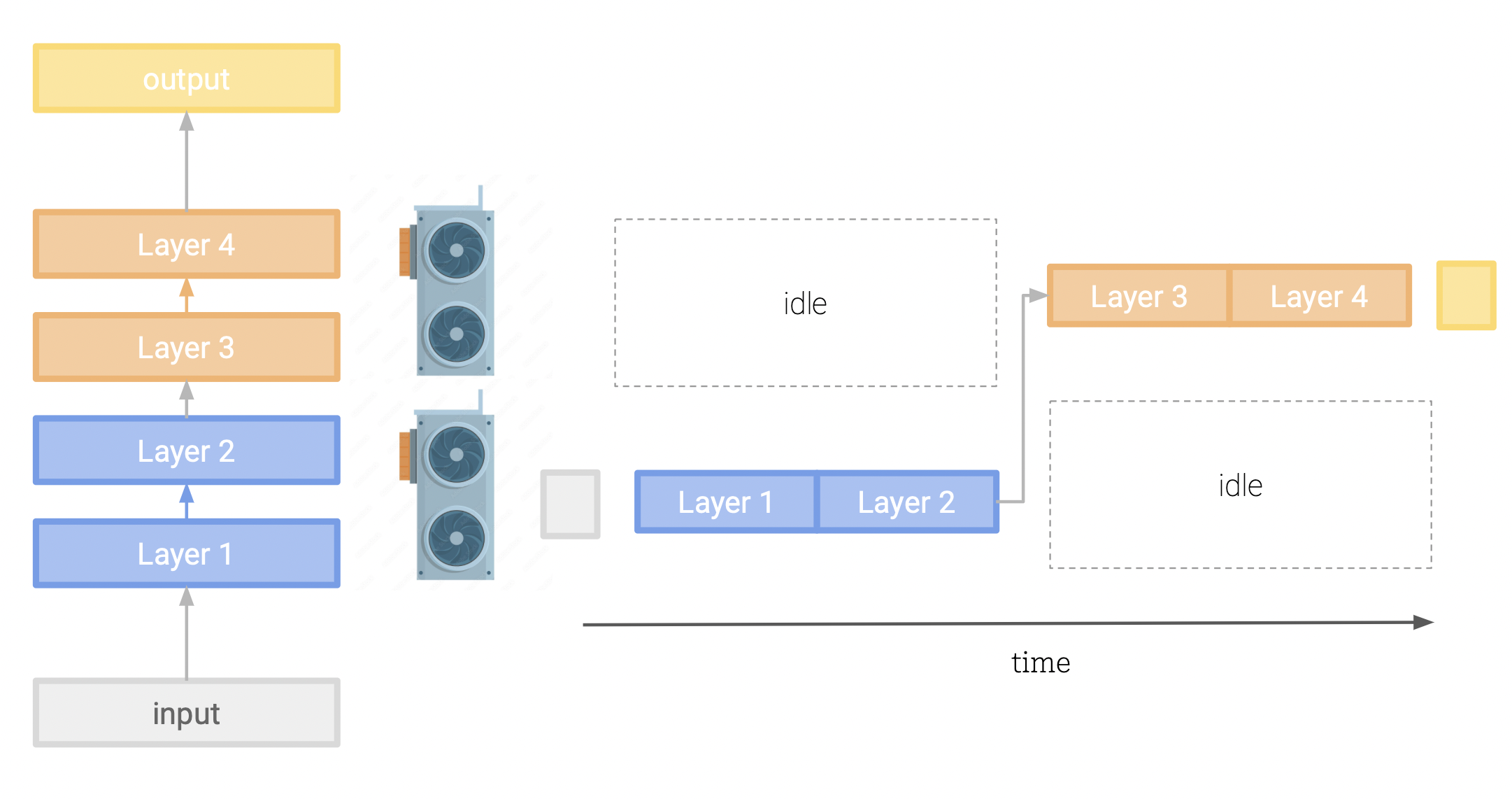
Pipeline parallelism:
This involves splitting our model layers across our devices. After one device has finished processing its chunk of the model, it passes the intermediate values to the next device to continue the computation. While this is a simple approach, it is limited by the sequential nature of the model, and the fact that the each device must wait for the previous to finish before it can move on to the next layer. This means both devices can sit idle for a large portion of the time, while the other is processing. We have managed to split our model across devices, but have lost our parallel execution.
Tensor parallelism:
Someone smart noticed the above approach was underutilizing the GPUs because of bubbles of idle wait time in their computation graphs. To maximise the computation occuring, ideally we want our GPUs operating as close to 100% utilization as possible for as much time as possible. We can achieve this by splitting our model in a slightly more ingenious way. Instead of splitting our model by layer, we split up the large matrices internal to our layers such as the big MLPs or attention modules. Different parts of the output matrix can be calcuated simultaneously and the intermediate tensors concated for the full result. As you can see in the following diagram this calculation is equivalent so no results are compromised.
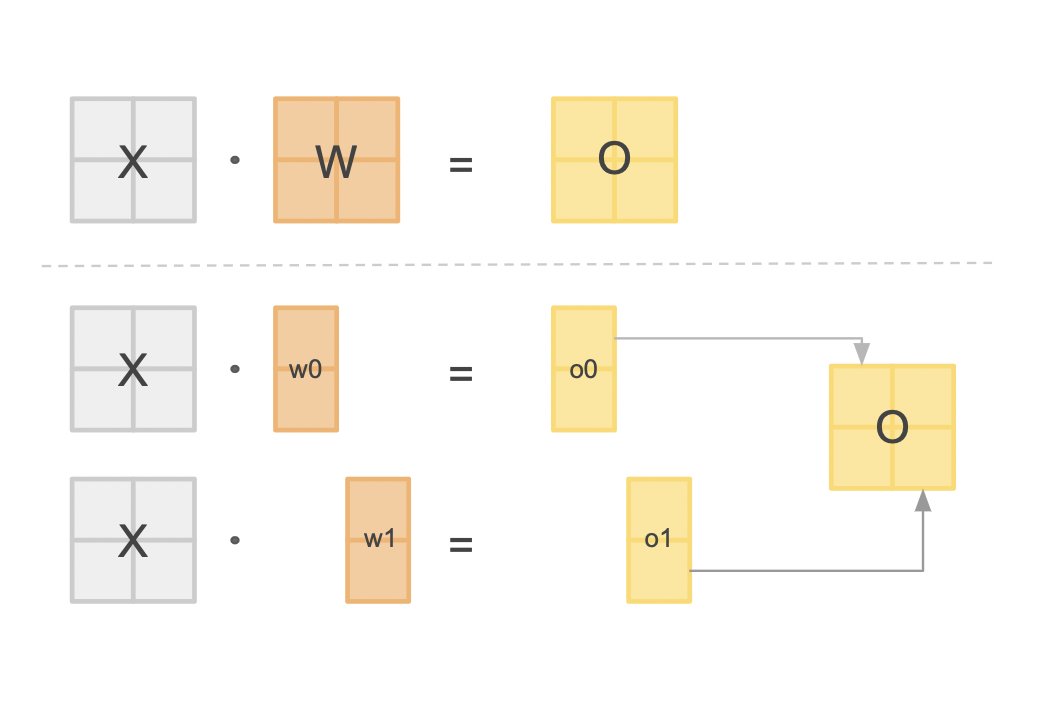
By following this method we can have all of our devices crunching away on heavy computation (what they are best at) at all times, at the cost of some communication overheads to synchronize tensors. Despite its added complexity, tensor parallelism is the way to go if you want ultra competitive performance from your multi-gpu setup.
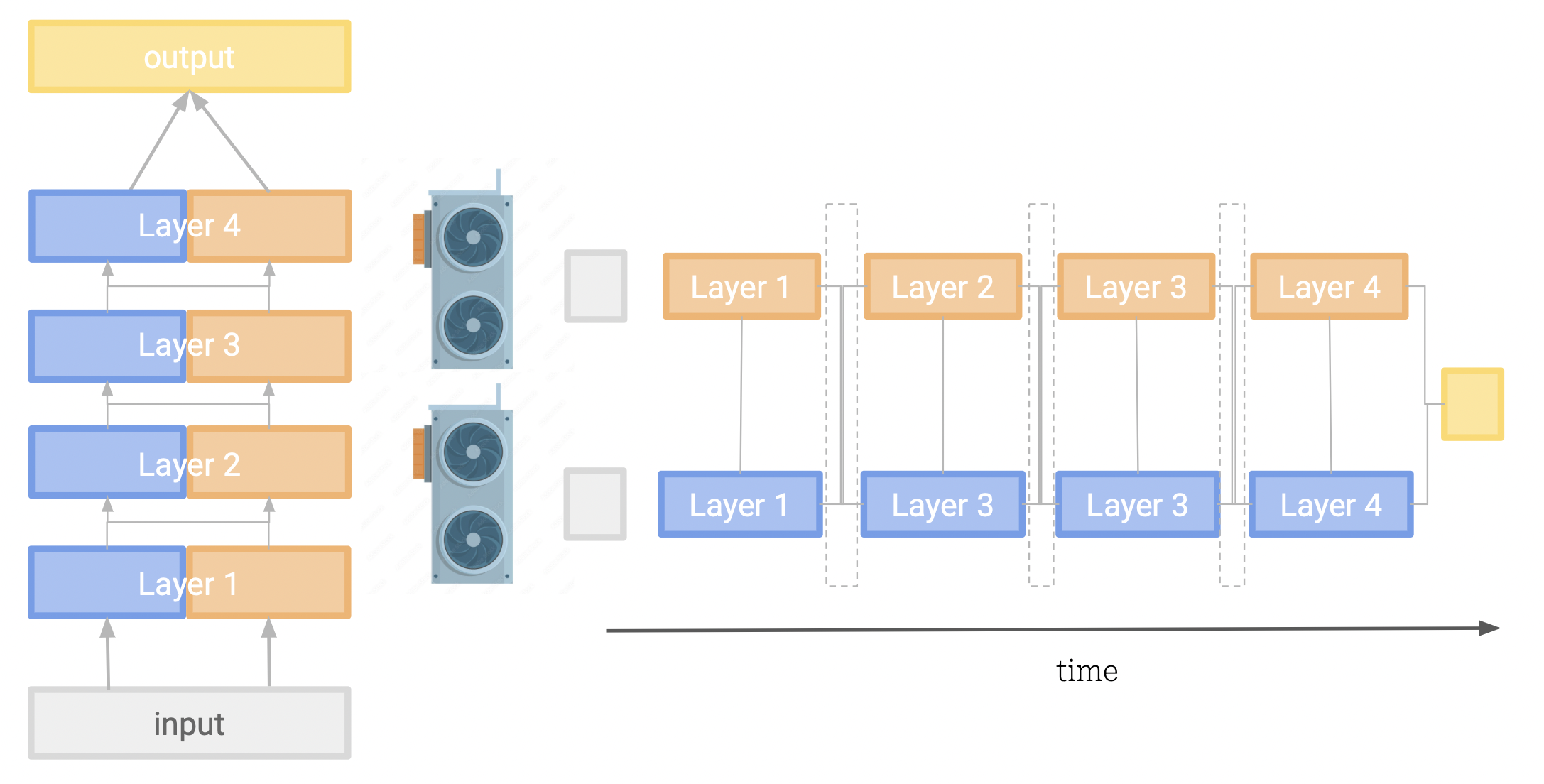
TitanML's multi-gpu engine
The above taster is a brief introduction to the complexities of distributed computing, and the challenges of deploying large models in production. Luckily, we at TitanML are on a mission to make this easier for you.
Results
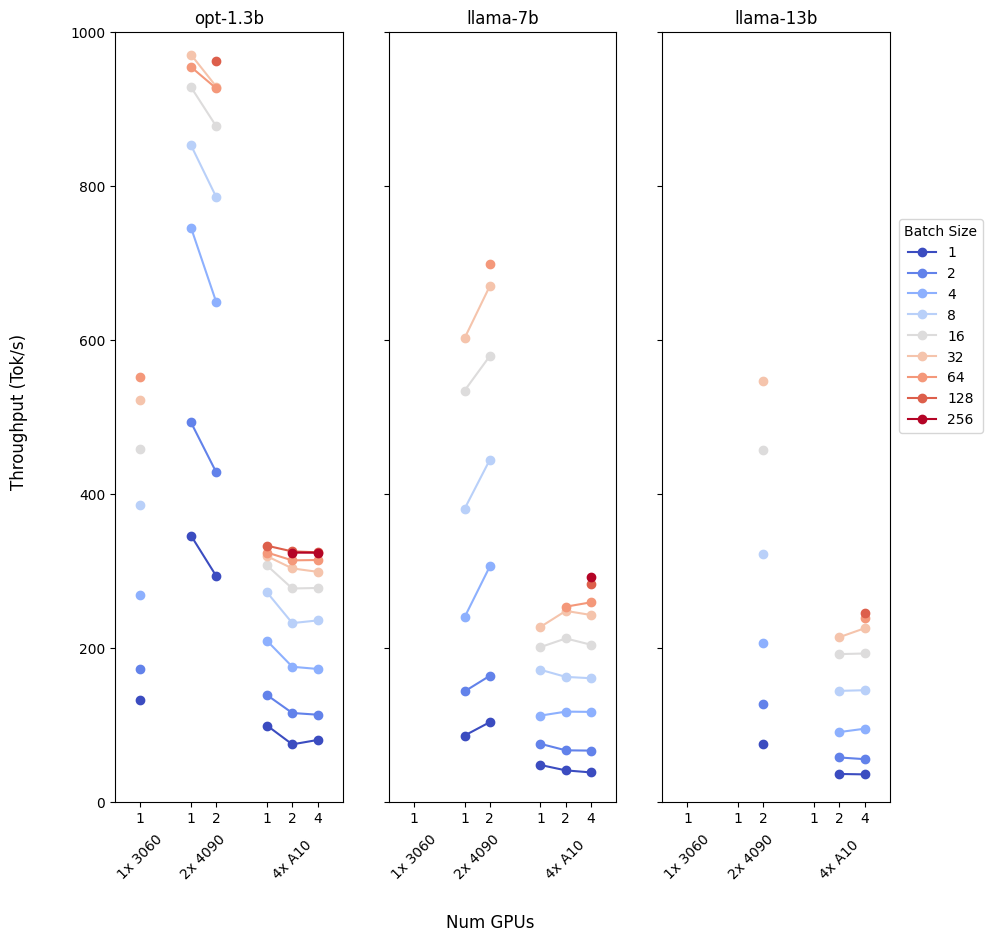
The following graph is a demonstration of the trials and tribulations of working with multiple GPUs. Its not as easy as just throwing more hardware at the problem, we need to assess and benchmark if its right for the type of application we are planning to build.
| param | value |
|---|---|
| prompt_length | 3 |
| max_new_tokens | 256 |
| min_new_tokens | 256 |
| sampling_temperature | 1 |
| sampling_topp | 0.9 |
| sampling_topk | 20 |
Table 3: Generation parameters for repeatability.
Discussion
Off the bat, we can see that a multi-gpu environment is wasted for a small model. The communication overheads and the fact that the model can fit on a single device means we are better off just using a single GPU. The larger GPU can work with bigger batch sizes, but the token/s is so high for the single GPU, that the throughput is likely maintained just because of the very low latency. In this scenario, we are better off using the data parallel regime and using each GPU to host its own model.
Fig 8 also demonstrates to us how our model size can outright reject potential hardware setups - where datapoints are missing, the setup failed with dreaded Out of Memory(OOM) errors. As we can see, if you want to run a Llama-13b you're going to need more than 1 GPU.
The most dramatic effect of a 4 GPU cluster is unlocking the 256 batch size. The reduced throughput is a second hand effect of the slower latency within the cluster, but this does mean 256 individual users are receiving output simultaneously (even if at a slower rate than on the 4090s). This may be a tradeoff that is worth it for your application. Unless you are using some very exotic batching methods such as continuous or piggyback batching (coming to Titan soon!), your next set of requests will sit queuing while the current batch is being processed. Sometimes serving more requests concurrently, even if it seems like it lowers your throughput, can be necessary, as the total average wait time for the user is still lower - this depends on the wider context of your whole application architecture.
Do it yourself
Running a model distributed across multiple GPUs, with all the previously discussed optimizations, can be achieved using Titan Takeoff Server2 with a single command:
docker run
-e TAKEOFF_BACKEND=multi-gpu # Specify multi-gpu backend
-e TAKEOFF_MODEL_NAME=meta-llama/llama-2-13b # Specify which model
-e TAKEOFF_ACCESS_TOKEN=<token> # Needed for Llama-2 models
-e CUDA_VISIBLE_DEVICES=<'0,1...'> # Decide which of our GPUs to use
--num-gpus all # Let the docker container access these
--shm-size=2gb
-p 3000:3000 # Port forward
takeoff-pro:gpu # The takeoff pro image
You can now send inference requests to your model using the following command, and the takeoff runtime will handle distributing the inputs, the parallel computation and aggregating the results:
curl http://localhost:8000/generate_stream \
-X POST \
-N \
-H "Content-Type: application/json" \
-d '{"text": "List 3 things you can do in London"}'
The text field can be an array of inputs with dimension matching your desired batch size, and the response will be an array of outputs of the same length. If you wish to watch your GPU utilisation during the process, you can run the following command in a separate terminal:
watch -n0.2 nvidia-smi
Here we can see what it looks like when our model is distributed across 4 devices, and how much memory a large batch size uses up!

Further improvements
Hybrid approaches
The eagle eyed amongst you may have noticed that the gains going from 2 to 4 GPUs for the llama-13b model are not dramatic enough to really justify doubling our expensive hardware resources. But! We can use our 4 GPU cluster more wisely, combining both tensor parallelism and the previously discussed data parallelism to eke much better performance out of our setup. If we split our model across 2 GPUs, and replicate this setup twice we can utilise all 4 of our GPUs, and achieve almost double the throughput of a 4 way tensor parallel model.
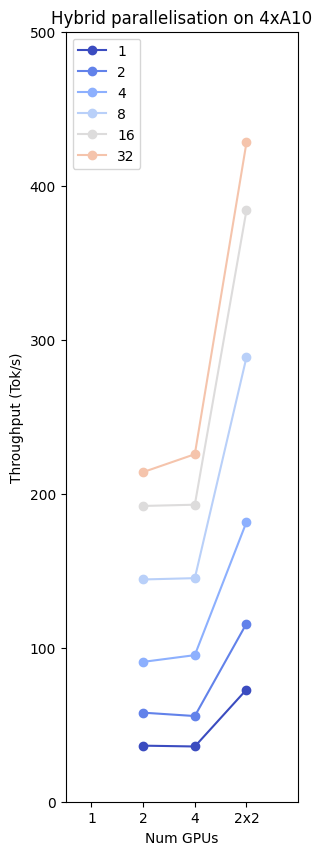
For this, now even more complex situation, we at TitanML have got you covered again! With Takeoff we can manage control groups of clustered GPUs so your requests can all hit a single endpoint (our highly optimised rust server) and we will organise distributing these requests across multiple sets of GPUs, each holding split up models. Finding the optimal setup for your application can be a mixture of intuition and trial and error, but with Takeoff we do as much of the initialisation and orchestration as possible, so that you can focus on rapidly prototyping and benchmarking your options.
Happy hacking!
About TitanML
TitanML enables machine learning teams to effortlessly and efficiently deploy large language models (LLMs). Their flagship product Takeoff Inference Server is already supercharging the deployments of a number of ML teams.
Founded by Dr. James Dborin, Dr. Fergus Finn and Meryem Arik, and backed by key industry partners including AWS and Intel, TitanML is a team of dedicated deep learning engineers on a mission to supercharge the adoption of enterprise AI.
Footnotes
-
https://github.com/ray-project/llm-numbers#v100-16gb-a10g-24gb-a100-4080gb-gpu-memory-capacities ↩
-
Multi-gpu support is currently a Pro feature - if you are interested, contact us here: https://www.titanml.co/contact ↩