It is no secret that we built Titan Takeoff to make it easy for you to make inferences and deploy your models. With the nitty-gritty details of deployment and technical complications of running massive models abstracted away, you can stop worrying about performance issues and instead focus on what really matters - how to select the best model for your use case and get your desired model to product quality outputs.
We recognize that the model selection and prompt engineering process are essential as this can influence the user experience and satisfaction with your applications. We also realize that this process is complex, usually requiring many rounds of repeated experimentation.
Simplified Model Selection and Prompt Engineering with LLM Arena
In order to help you with this challenging process, we have built the LLM Arena. This interactive web application lets you quickly compare the outputs across different models and prompts. We’ve abstracted away all the technical complexities of deploying other models, so you can use our simple interface to compare different models and prompts, speeding up experimentation and development of your AI-powered application.
Lightweight Model Comparison
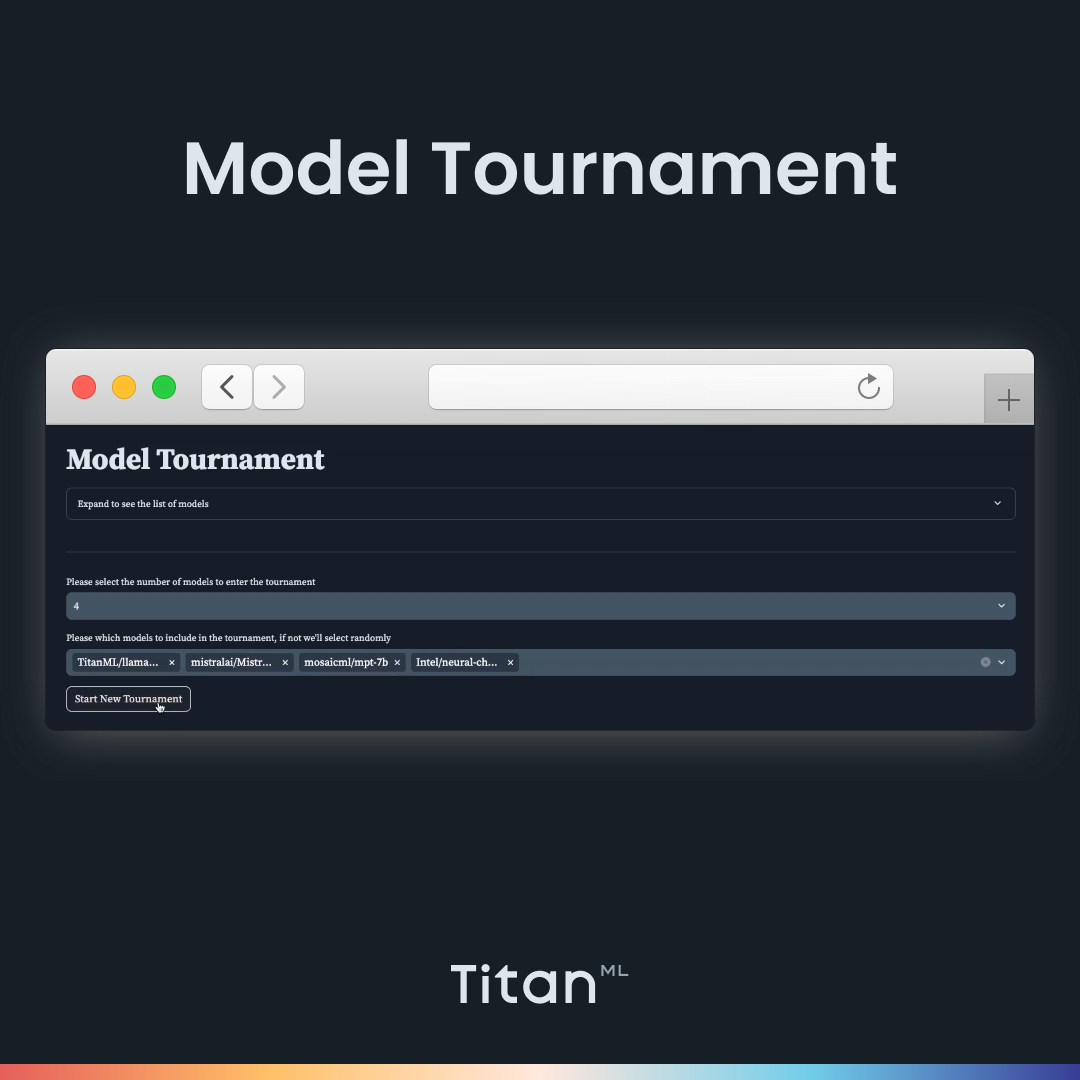
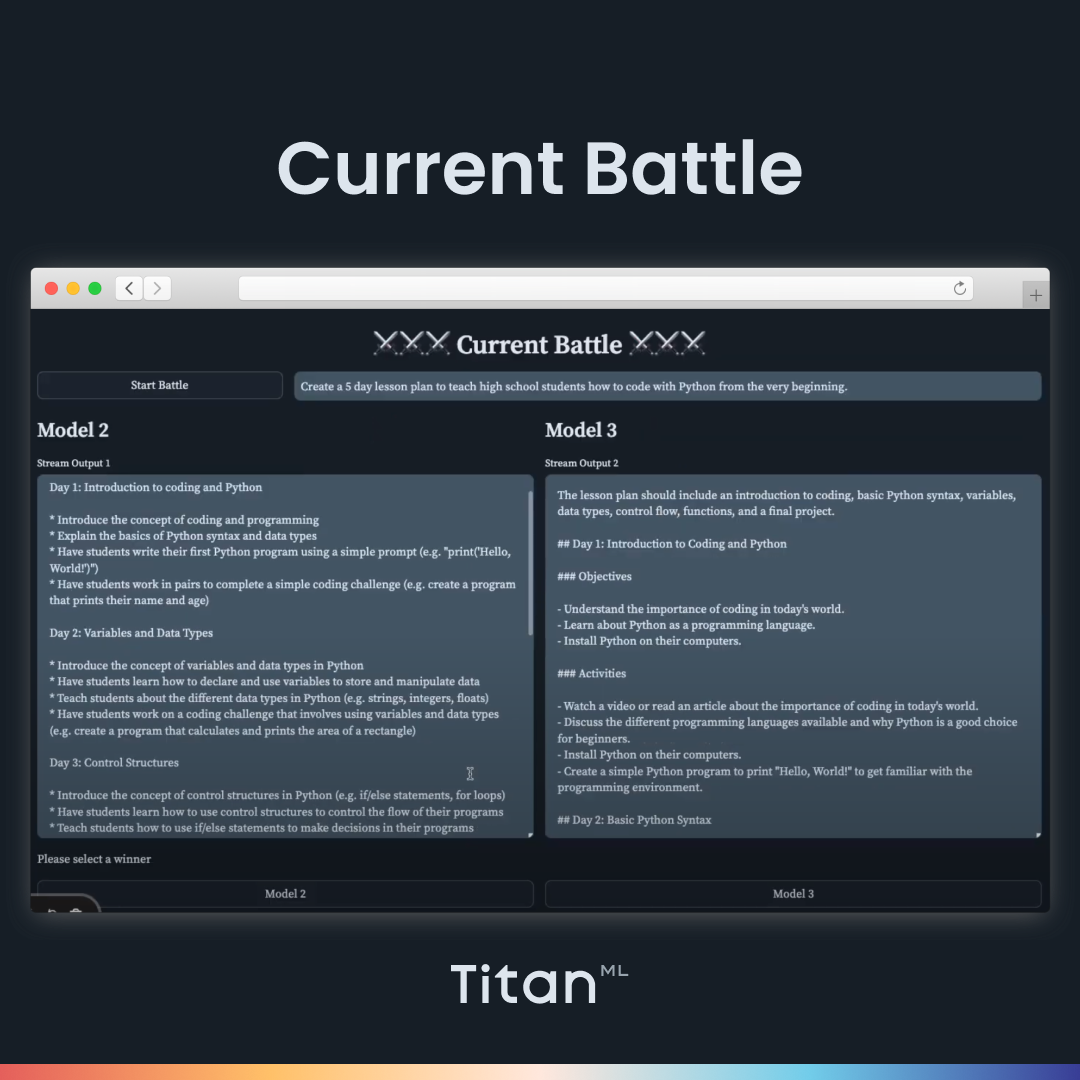
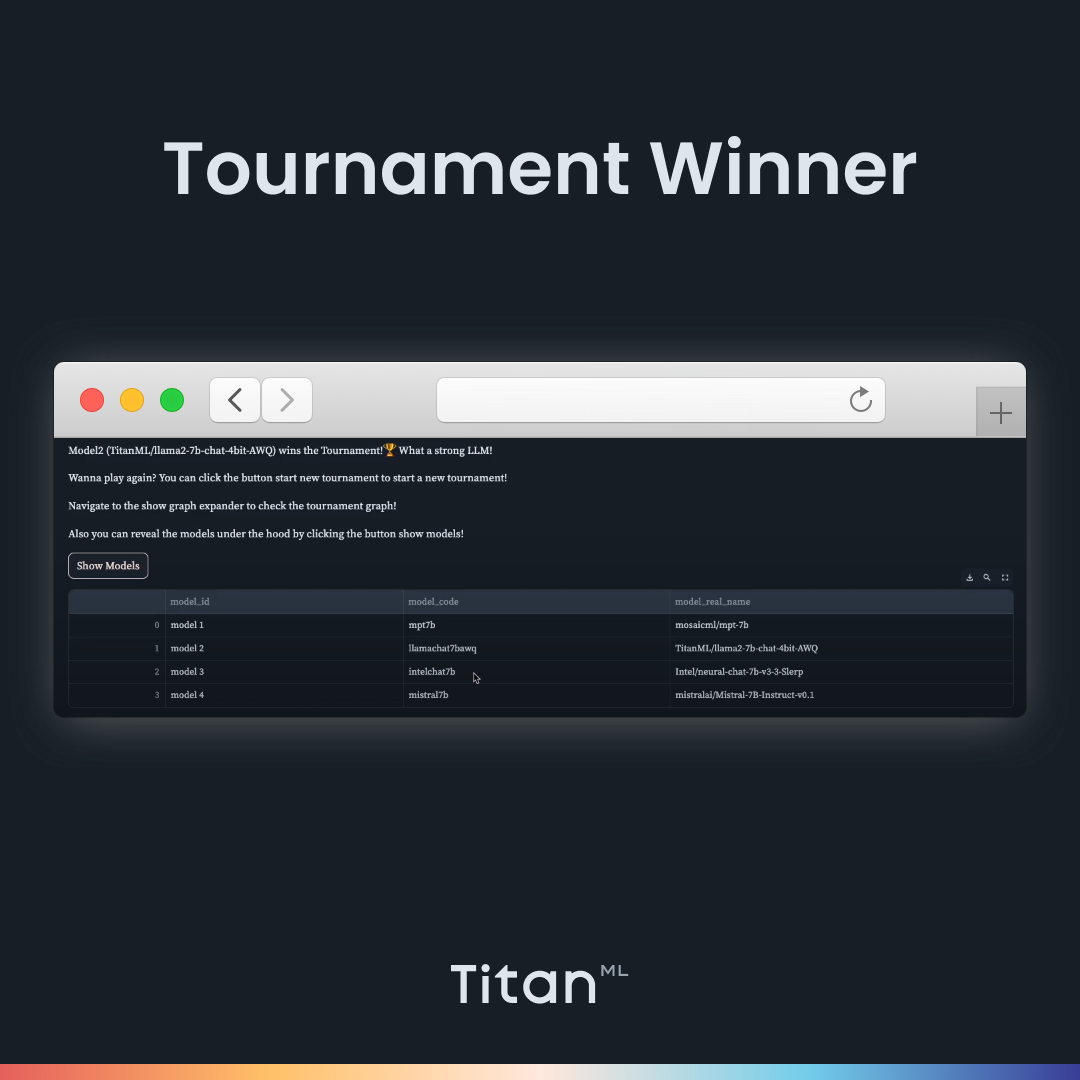
In the previous blog post, we talked about the Tournament Mode, where users can host a knockout-style tournament for Large Language Models, allowing them to judge and compare outputs between various models and find the ultimate winning model that produces the best output.
While this may be a helpful way of testing out a more comprehensive selection of models, we recognize that this may only be appropriate for some model comparison workflows. Therefore, we have included a Comparison mode in the LLM Arena that allows users to simply compare two models in-depth, side-by-side, without going through the process of playing a whole tournament and spinning up and down different models.
How the Comparison Mode works

- Model Selection: You can pick two model outputs to compare side-by-side, making evaluating the outputs of the models more convenient and straightforward.
- Simultaneous Streaming: The responses from two models are streamed back in real-time, allowing you to compare the speed of responses as well.
- Efficient Model Orchestration: The Comparison Mode is built with Hades, a Kubernetes-based orchestration system that efficiently spins up and down models on demand, based on which models you need.
Comparing Model variants with LLM Arena
We’re still working with the fictional NextGen Education, an Education Tech company, from the previous blog post. We’re helping their marketing department with their social media campaign this time. They want to use an LLM to create a promotional post for their new product, PlanlyAI, an AI-powered tool to help teachers make lesson plans (what we did in our previous blog post).
They have decided to pick a Llama-2 7B model and have secured enough budget to host it in full precision. However, they can also choose to save much more by hosting a quantized or compressed version of Llama 2 7B on a smaller AWS instance, allowing them to spend more on marketing campaigns. But they’re still a bit hesitant about the performance loss that comes with quantization. In order to reassure them about using quantized models, they will have to see an output that is not significantly worse than that of the unquantized model.
This is the prompt we’re going to use:
Craft a compelling and concise marketing tweet for NextGen Tech, promoting their new product, PlanlyAI. PlanlyAI is an innovative AI-powered platform designed to assist teachers in generating comprehensive and engaging lesson plans efficiently. The tweet should emphasize the benefits of PlanlyAI, such as its ability to save time, enhance lesson quality, and personalize learning experiences. Highlight the user-friendly nature of the platform and its alignment with modern teaching needs. Include a call to action encouraging educators to explore PlanlyAI for their lesson planning needs. The tone should be enthusiastic, professional, and focused on the transformative impact of PlanlyAI in the educational sector. Ensure the tweet is under 280 characters, making it suitable for Twitter.
Here’s what it looks like in Comparison Mode:

We see that the outputs from the quantized and unquantized models aren’t very different from each other, and the marketing department will be pleased to know that they will have saved some compute costs for their marketing costs.
LLM Arena
The comparison mode is a lightweight and helpful way to compare the outputs of two models side-by-side. It allows for quick experimentation to select the better model or sometimes even to test a hypothesis (that quantized models do not differ much from those in full precision). If you’re keen to incorporate LLM Arena into your AI game plan, do reach out to us.
About TitanML
TitanML enables machine learning teams to deploy large language models (LLMs) effortlessly and efficiently. Our flagship product, Titan Takeoff Inference Server, is already supercharging the deployments of several ML teams.
Founded by Dr. James Dborin, Dr. Fergus Finn, and Meryem Arik and backed by key industry partners, including AWS and Intel, TitanML is a team of dedicated deep learning engineers on a mission to supercharge the adoption of enterprise AI.