
In today's rapidly evolving tech landscape, language models like ChatGPT have taken centre stage. There's a buzz in the air as enthusiasts and researchers race to harness the full power of AI. To produce coherent and high-quality responses, these models are constructed with a colossal number of parameters, sometimes in the realm of hundreds of billions. These parameters are the essential building blocks that enable the models to interpret our queries and craft contextually relevant answers.
However, the astronomical number of parameters can be a double-edged sword. They increase computational demands, leading to slower deployment times. No one has time to wait endlessly for an AI-generated response. Hence, research is in full swing to speed up response times without sacrificing the quality of the answers.
In this article, we'll first explore the basics of text generation, before introducing an innovative decoding method designed to speed up text generation significantly, all while maintaining high-quality results.
Text Generation 101
Text generation is an iteration of two consecutive processes: forward pass and decoding.
During the forward pass, the input is processed through a sequence of layers in the model. Within these layers, specific weights and biases are applied to shape the input. At the end of this pass, the model produces a set of potential tokens, each accompanied by its probability, indicating how likely it is to follow the given input. For instance, the higher the probability, the more likely the token is to follow the input.
After the forward pass comes decoding. This is where we select a token from the list of possible tokens obtained from forward pass. Several decoding methods exist, but the most common is "greedy decoding," where we simply choose the token with the highest probability.
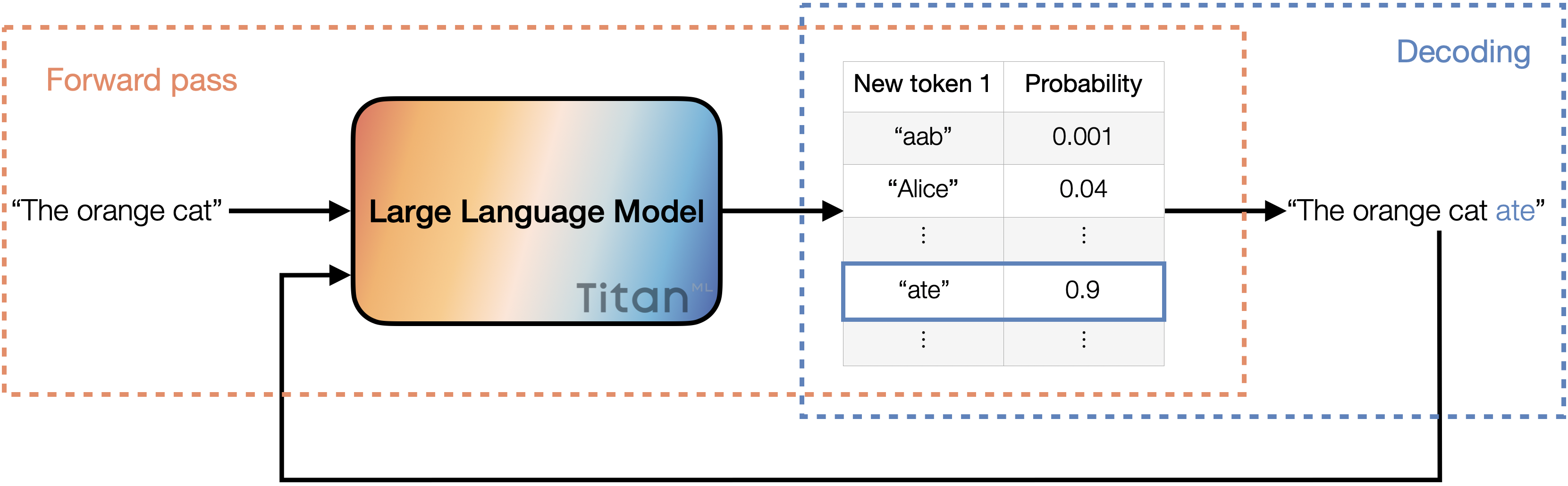 An illustration of the text generation process. The input is fed into the large language model, where it undergoes the forward pass. The model returns a list of potential tokens with their associated probabilities. Then, we decode by selecting the token with the highest probability and appending it to the input. This updated input then goes through the entire process once more.
An illustration of the text generation process. The input is fed into the large language model, where it undergoes the forward pass. The model returns a list of potential tokens with their associated probabilities. Then, we decode by selecting the token with the highest probability and appending it to the input. This updated input then goes through the entire process once more.
After selecting the token, we append it to the existing input and pass it through the forward pass and decoding again. This iterative process forms the foundation of text generation in modern language models.
The primary reason for delayed response times in large language models becomes evident: the forward pass in these models can be time-consuming. When these models are locally hosted or are served to a limited number of users, they often use smaller batch sizes. In these cases, performing matrix multiplications to apply weights and biases is relatively easy. But the real challenge arises when loading layer weights onto local devices. This process is heavily restricted by memory bandwidth, referred to as being 'memory (or bandwidth) bound'. It's worth mentioning that for larger batch sizes, the bottleneck often shifts towards compute-bound processes. Here, techniques such as quantization might not always speed things up and could even slow down performance.
Now that we've pinpointed the bottleneck, let's see how speculative decoding offers a solution. But first, we need to take a slight detour to discuss caching.
 A full text generation process, where the large language model iteratively generates a full sentence with the given input.
A full text generation process, where the large language model iteratively generates a full sentence with the given input.
To Cache or Not to Cache
Caching is a strategy where temporary memory storage is used to hold copies of data, allowing future requests for that data to be accessed much more rapidly than from the main storage. In the realm of model forward passes, caching speeds up the process by storing the list of potential tokens generated so far.
Consequently, the forward pass only has to compute probabilities for the next potential token. Without caching, the forward pass has to recalculate probabilities for each token in the input again. This ability to store and rapidly access previously calculated probabilities is instrumental for speculative decoding. In speculative decoding, we not only use the forward pass to predict the next token, but also evaluate whether the selected tokens are a good choice.
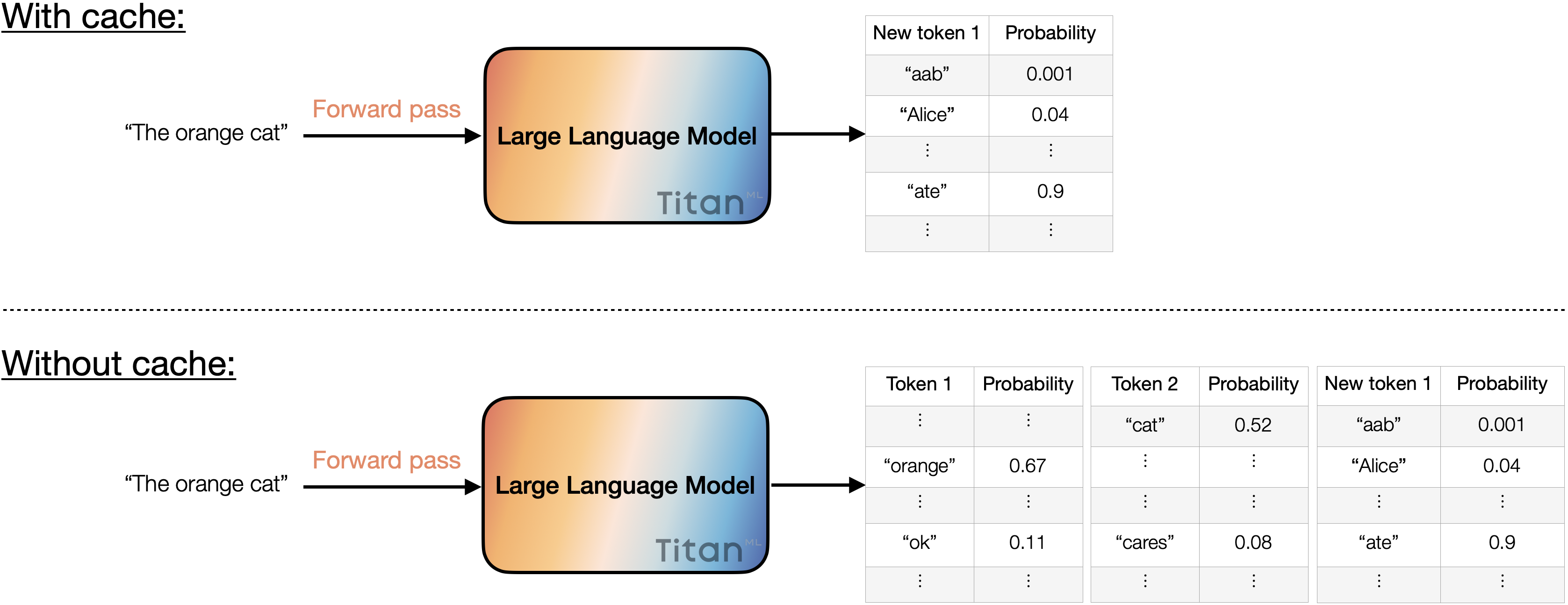 Caching reduces the redundant computation by skipping tokens that have already been processed, focusing solely on calculating probabilities for potential new tokens. In contrast, disabling caching entails computing probabilities for all tokens, including the input tokens.
Caching reduces the redundant computation by skipping tokens that have already been processed, focusing solely on calculating probabilities for potential new tokens. In contrast, disabling caching entails computing probabilities for all tokens, including the input tokens.
Speculative Decoding
While small models offer low latency, they often produce text of poorer quality. In contrast, larger models may be able to produce a text of high quality, but may suffer from slow response times. Are we forced to pick our poison here? Not necessarily. Speculative decoding bridges this gap, producing content that mirrors the sophistication of larger models but at faster speeds. If you're keen on giving it a shot, here's a guide to set you on the right track:
-
Select a small model and a large one of your preference. Make sure they share the same tokenizer, so that we can meaningfully compare the logits of the two models.
-
Generate a specific number of candidate new tokens with the small model, say 3. This involves running the forward pass on the small model 3 times.
-
Use the larger model to forward pass the prospective new input (combining the original with the 3 new tokens). This returns lists of potential tokens with their corresponding probabilities for all input tokens.
-
Decode the last 4 tokens using greedy decoding (3 new tokens plus an additional one from the forward pass of the large model). Compare the decoded tokens from the large model with the candidate new tokens, starting from left to right. If the tokens match, we accept them and append them to the original input. Continue this process until the first mismatch occurs, at which point we append the token from the large model to the input. This updated input is then passed through the small model to generate 3 more tokens, and the entire process is repeated.
In the above process, each step of the iteration ensures the generation of new tokens, ranging from 1 to 4. In other words, we generate between 1 to 4 new tokens with just one forward pass from the large model. Naturally, we can experiment with varying the number of new tokens generated by the small model per iteration and choosing different decoding methods for further optimisation.
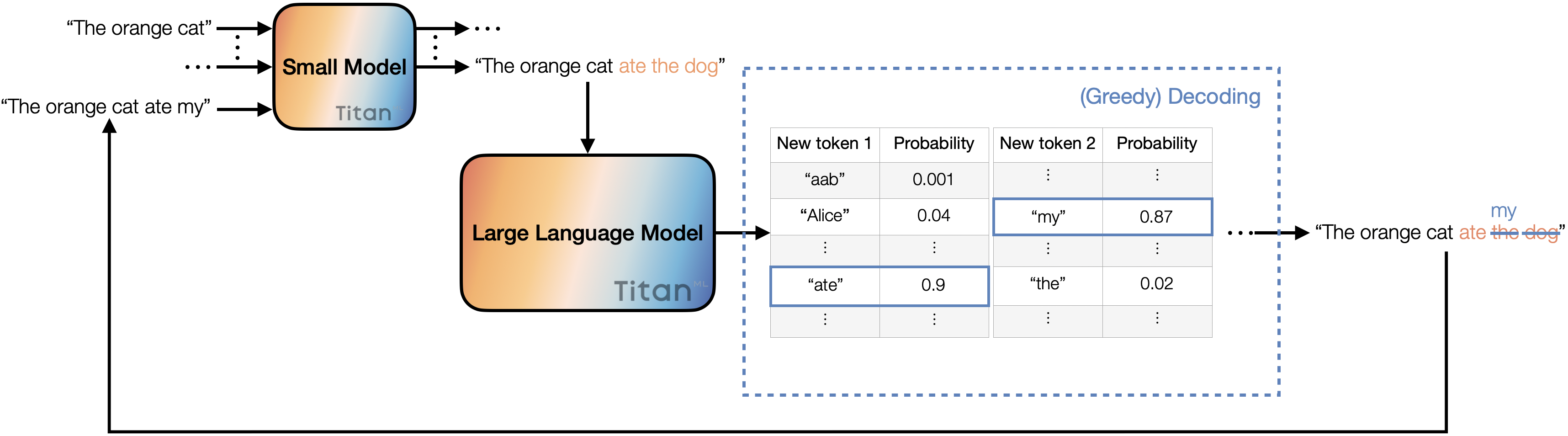 Speculative decoding.
Speculative decoding.
Results & Discussions
To delve deeper into the capabilities of speculative decoding, we integrated it with the AWQ inference engine and subjected it to tests across three distinct hardware platforms: Nvidia A10, RTX 3060, and RTX 4090. The AWQ framework represents a cutting-edge approach to model compression and execution in 4-bit. The weights of a model are adjusted to minimize errors, and its rapid inference kernels ensure that 4-bit inferencing can outpace its 16-bit counterpart. This is achieved even though the model is dequantized on the fly to perform matrix operations in 16-bit.
The beauty of 4-bit inference is its ability to host larger models on smaller devices. When paired with speculative decoding, these larger models can be executed as quickly or even more quickly than their smaller counterparts that are optimised for the device. You can have your cake and eat it too: now, you don’t have to choose between size and speed. You can deploy a significantly larger without compromising on speed!
For a comprehensive understanding, we compared the performance of the combination of AWQ and Speculative Decoding against other engines such as Hugging Face and CTranslate2. We chose the OPT-125m as our 'small model' benchmark for speculative decoding. The findings were nothing short of remarkable: speculative decoding sped up the OPT-13b model to deliver response times that mirrored a model that's 10x smaller on Hugging Face and one that's half its size on CTranslate2.
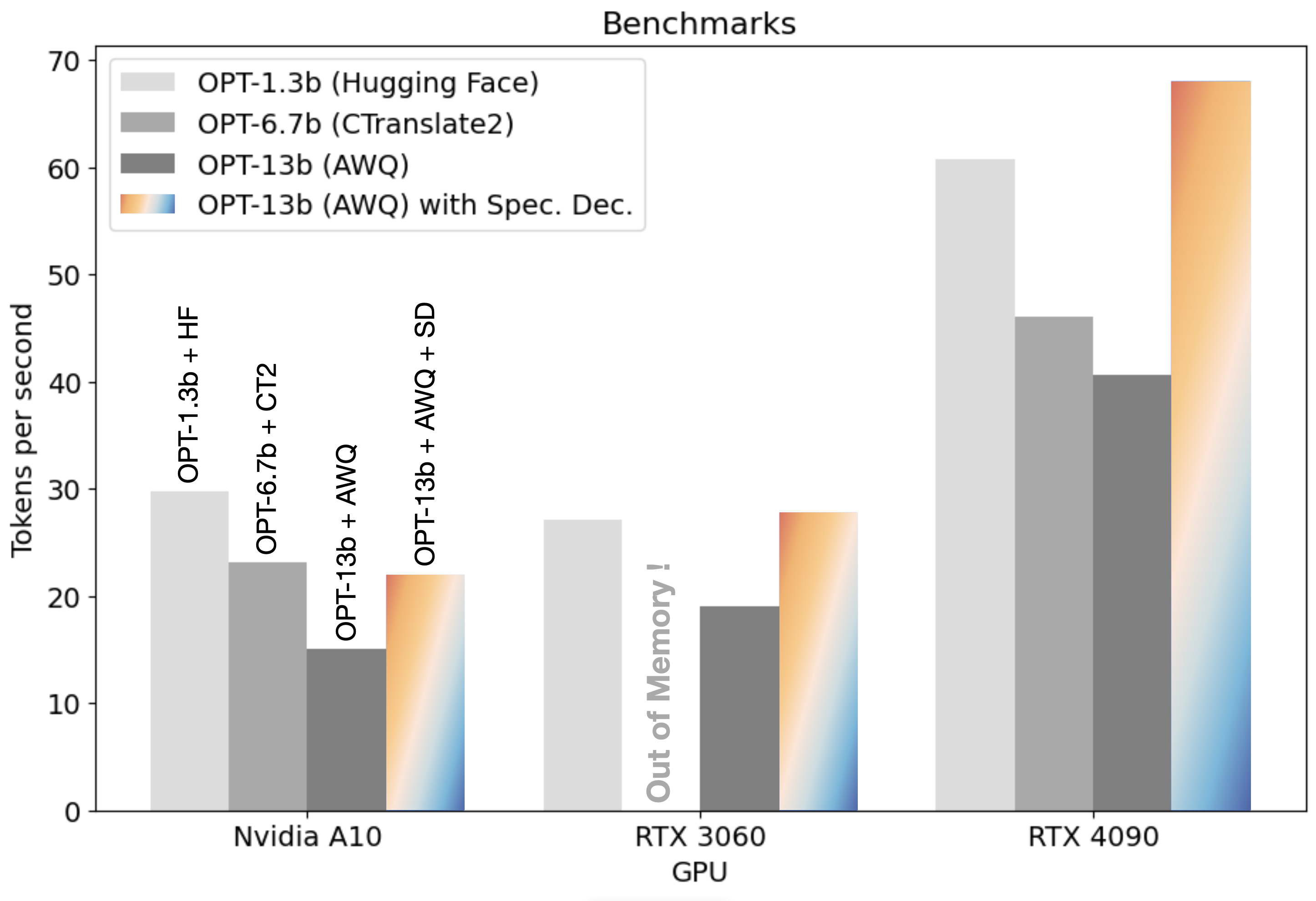 Speculative decoding, coupled with the AWQ engine, speeds up the OPT-13b model to a similar speed as a model 10 times smaller on Hugging Face and twice as small on CTranslate2. Pretty cool, right?!
Speculative decoding, coupled with the AWQ engine, speeds up the OPT-13b model to a similar speed as a model 10 times smaller on Hugging Face and twice as small on CTranslate2. Pretty cool, right?!
For the sake of completeness, we've got a detailed benchmark table right below to give you the full scoop!
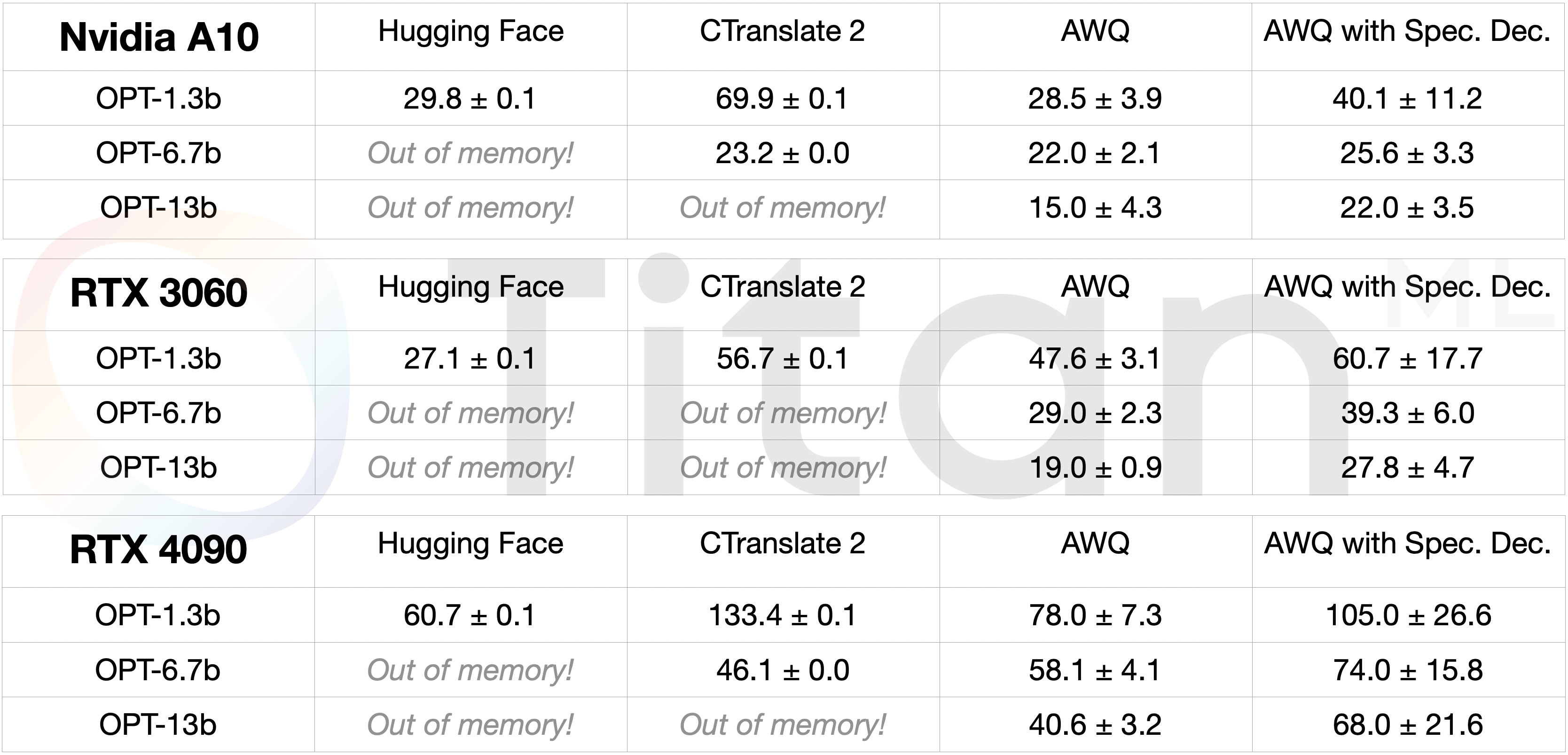 A benchmark table illustrating the performance of models in 3 different sizes across 3 GPUs. The values in the table indicate number of tokens generated per second.
A benchmark table illustrating the performance of models in 3 different sizes across 3 GPUs. The values in the table indicate number of tokens generated per second.
Future Development
Speculative decoding introduces an innovative strategy for enhancing the performance of large language models. By deftly navigating around memory bandwidth constraints, it accelerates text generation without compromising on quality. Yet, there is still plenty more room for improvement.
Future avenues of exploration might include using a range of decoding methods, incorporating early exits when outputs seem confidently accurate, and even venturing into speculative decoding with the LLM itself, termed as 'self-speculative decoding'.
About TitanML
TitanML enables machine learning teams to effortlessly and efficiently deploy large language models (LLMs). Their flagship product Takeoff Inference Server is already supercharging the deployments of a number of ML teams.
Founded by Dr. James Dborin, Dr. Fergus Finn and Meryem Arik, and backed by key industry partners including AWS and Intel, TitanML is a team of dedicated deep learning engineers on a mission to supercharge the adoption of enterprise AI.