Batching Strategies
-
Batching is an important optimization for language model serving:
- Batching combines multiple requests into a single call to the model.
- This allows the model to process the content of multiple requests in parallel.
- Given the substantial parallelization capabilities of GPUs, batching can significantly increase server throughput.
-
Batching in an inference server requires careful consideration:
- One approach is at the request level:
- Requests arriving within a short time window are batched together and processed all at once.
- This method is also called dynamic batching.
- Drawbacks include added latency, as each request must wait for the batching interval to elapse before processing.
- Despite this latency, the increase in throughput often makes it worthwhile.
- One approach is at the request level:
-
Challenges with dynamic batching:
- Each request waits for the batching interval.
- Example issue:
- A user requests a 1000-word document.
- Nine users request single words.
- All 10 requests are batched together.
- The nine simple requests must wait for the 1000-word request to complete.
- Additional simple requests arriving during this time will also be delayed.
-
Token-level scheduling offers a solution:
- The model processes a batch of requests, adjusting the batch size as tokens are generated.
- Continuous processing:
- Completed requests are returned immediately.
- The model refills its batch from a buffer when the batch size drops below a threshold.
- This paradigm is called continuous batching, and is the default strategy for deploying LLMs in takeoff.
-
Applicability:
- Non-generative models (e.g., embedding models) can only use dynamic batching.
- For details on configuring both batching modes in the takeoff server, see below.
Continuous batching
Continuous batching is a generation algorithm for large language model serving, where the model inference logic is defined such that the batch of requests that the language model is working on can grow and shrink after each generated token. This allows incoming requests to join the processing batch at any time, and allows responses to be returned as soon as they are ready.
This is in contrast to dynamic batching, described in detail below, where the batch size that the model can process is fixed, and incoming requests are buffered in order to allow them to be processed in batches of that size.
Example of Continuous Batching
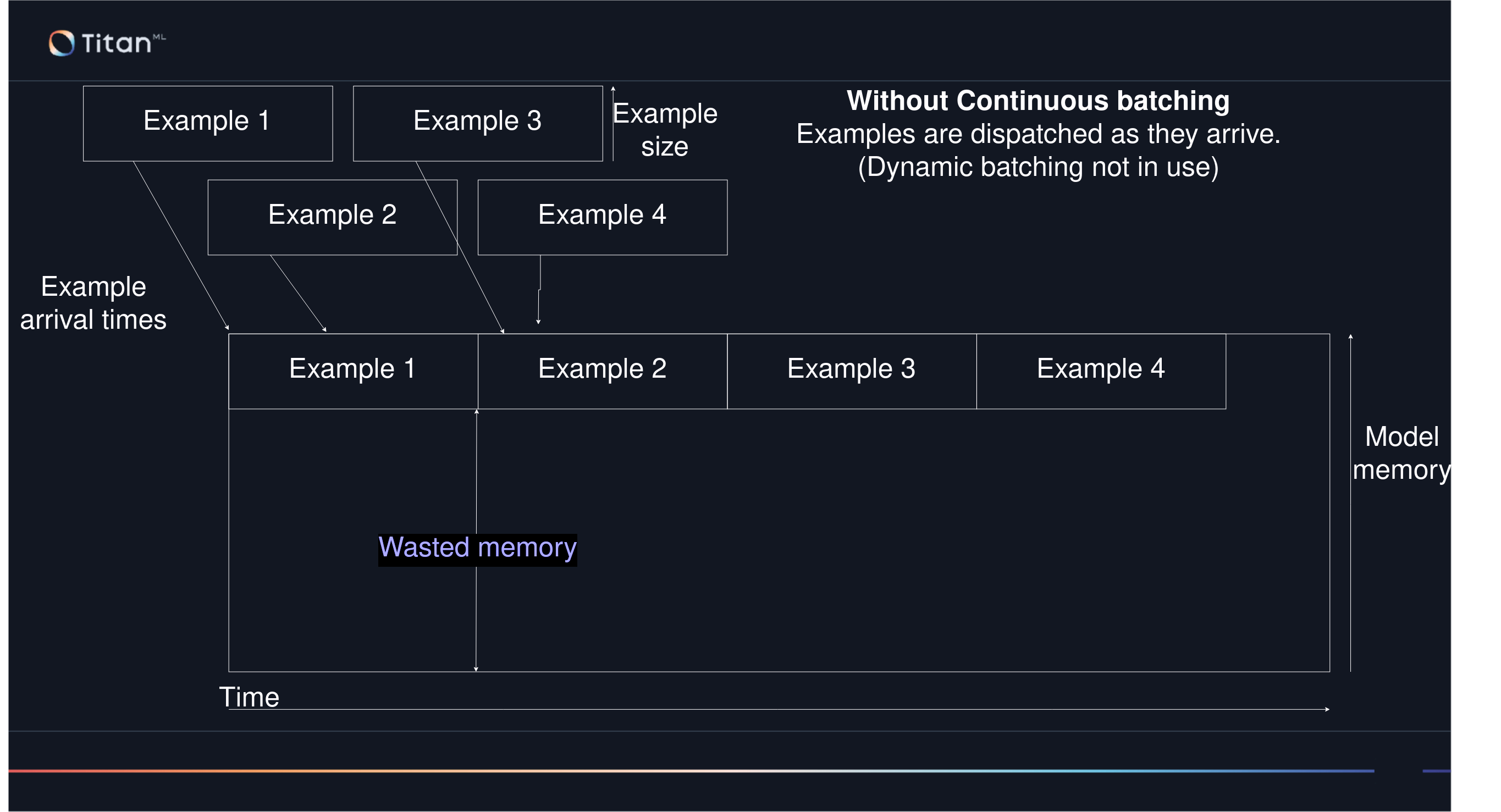
Without Continuous or Dynamic batching, hardware can be used inefficiently depending on when each example is submitted ('arrives'). The GPU cannot start on another example until its finished the previous one, resulting in most examples ending up in a backlog. Example 4 below has had to wait for examples 2 and 3 to finish in their entirety, despite having arrived not long after Example 2.
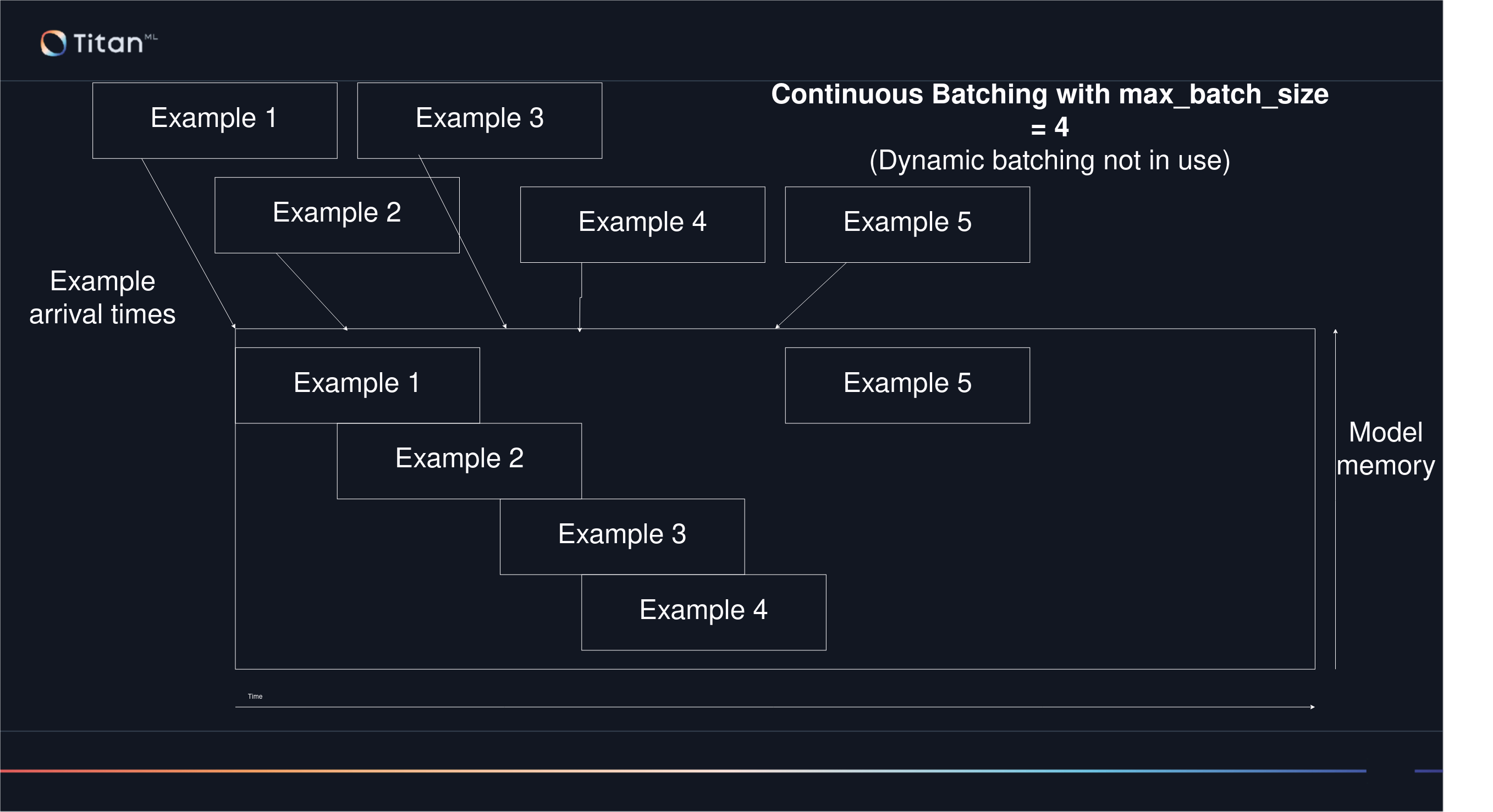
With Continuous batching, examples are added to the batch as they arrive, cyclically filling the available memory space by making use of selective indexing of the KV Cache.
Why continuous batching?
The continuous batching process increases the maximum throughput of the server. If you're using takeoff to process large batch workloads (think summarising a lot of documents, or responding to a long list of questions), or high traffic volumes, then continuous batching will allow you to process these requests faster, since each can join the batch in progress, closer to the time that it arrived, and leave the processing batch as soon as it is finished (rather than waiting for its neighbours in the batch to finish before being returned).
Continuous batching also decreases the average time to response for the server. So takeoff in this configuration will respond (on average) faster than the same server with dynamic batching enabled.
Dynamic batching
Dynamic batching is a process where the size of batches is adjusted to match the stream of incoming requests. During periods of heavy traffic requests are batched together to maximise throughput, to avoid one request waiting for every request ahead of it in the queue to finish sequentially.
We achieve this by having a timeout (default 50ms) after which any queued requests are sent to the model. In the timeout interval any incoming requests are paused and wait until the timeout period is finished. Then all the requests are sent to the model to begin processing.
Example of Dynamic Batching
Without Dynamic batching, hardware can be used inefficiently depending on when each example is submitted ('arrives'). The GPU cannot start on another example until its finished the previous one, resulting in most examples ending up in a backlog. Example 4 below has had to wait for examples 2 and 3 to finish in their entirety, despite having arrived not long after Example 2.
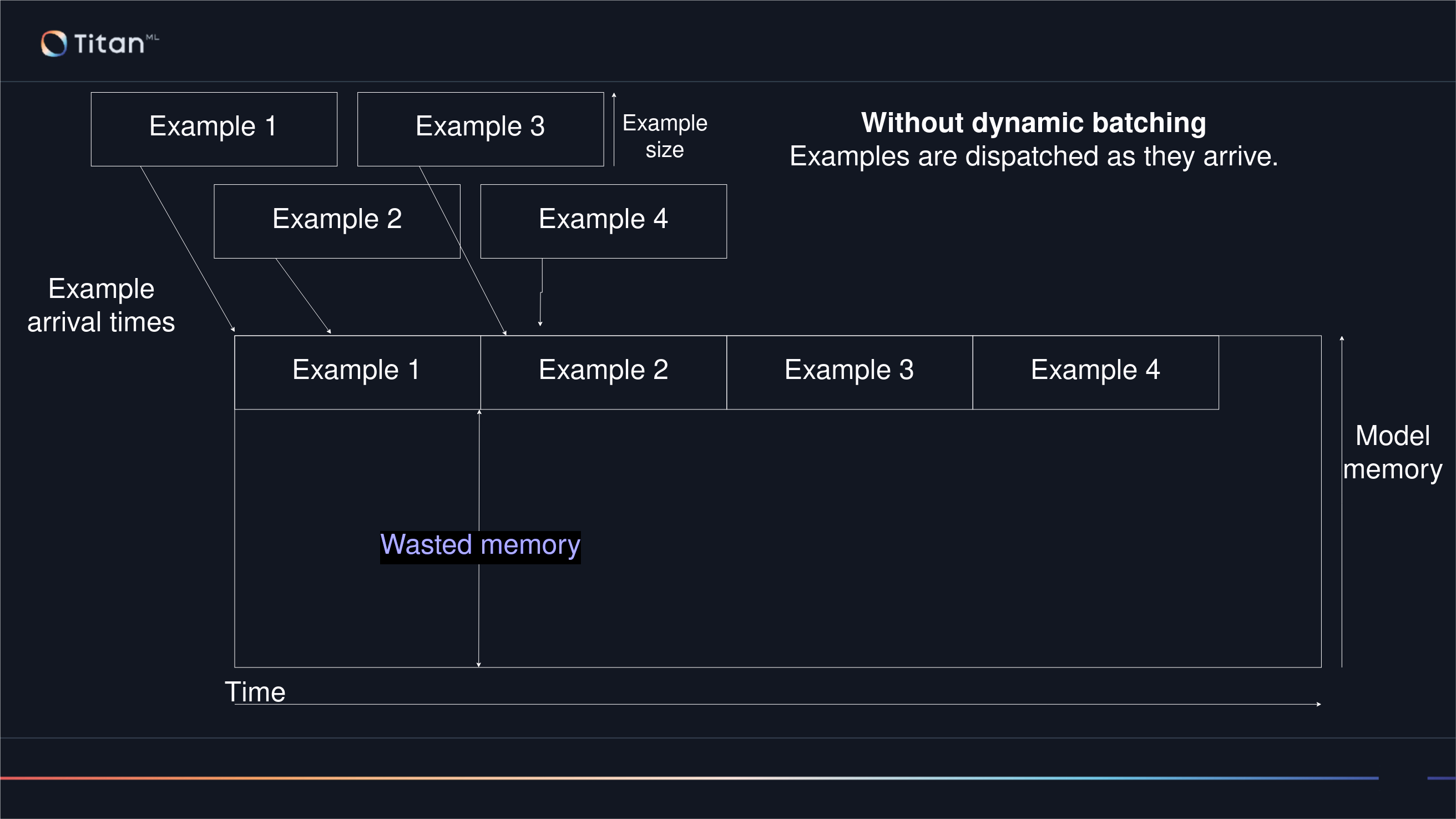 In comparison, the Dynamic batching case shown below waits for a full batch to be accumulated as to make maximal use of the GPU. This makes maximal use of parallelism, and results in the batch of examples being returned earlier.
In comparison, the Dynamic batching case shown below waits for a full batch to be accumulated as to make maximal use of the GPU. This makes maximal use of parallelism, and results in the batch of examples being returned earlier.
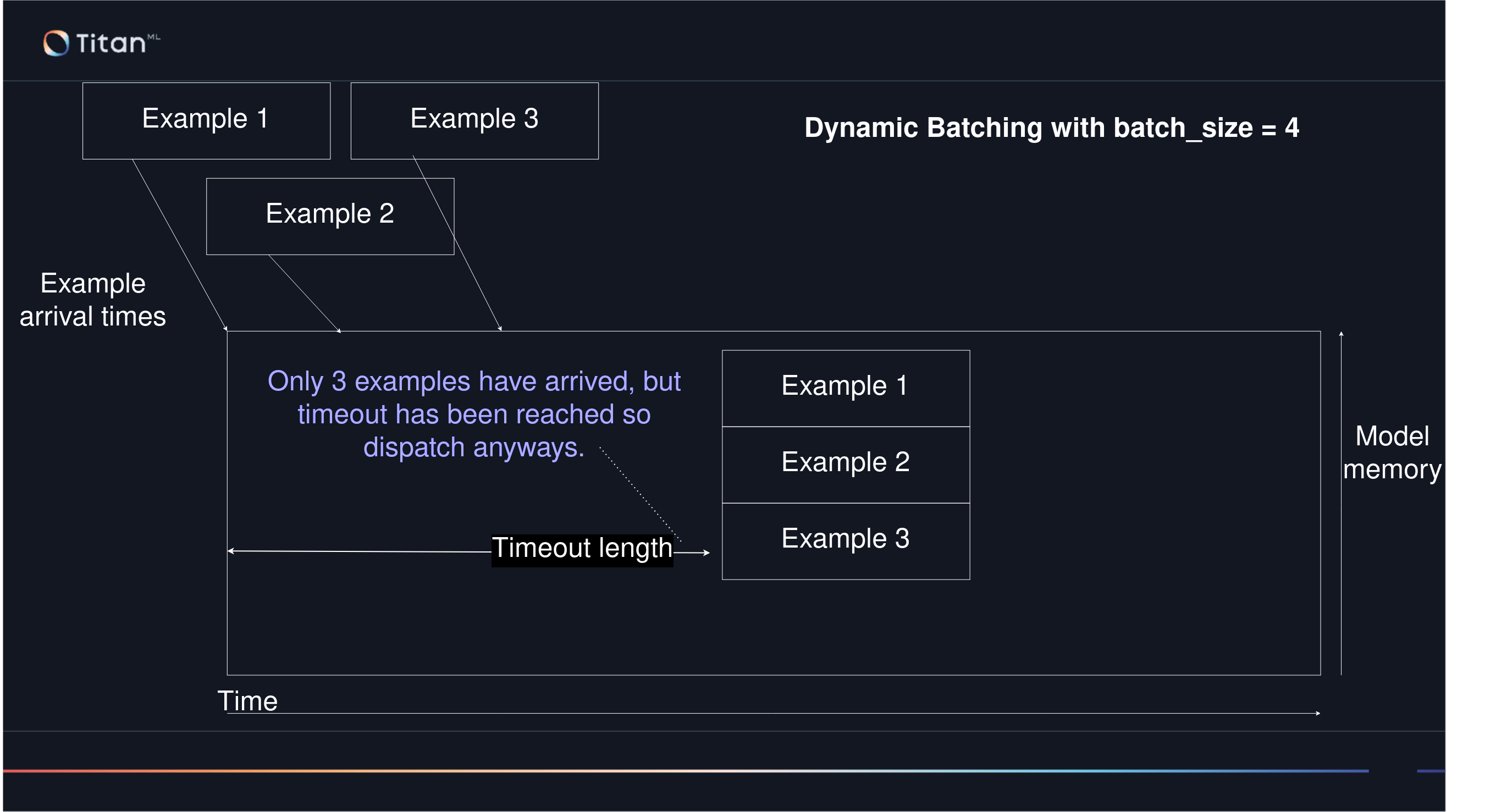 An issue arises if only three examples arrive. Rather than never returning these three examples as the batch hasn't been filled, a timeout is reached which dispatches the three examples on their own.
An issue arises if only three examples arrive. Rather than never returning these three examples as the batch hasn't been filled, a timeout is reached which dispatches the three examples on their own.

Were this timeout to be longer, the users who submitted these three examples would have to wait for longer. Were this timeout to be shorter - to half of that shown - and this example submission behaviour consistent, then the third submission would always have to be unnecessarily delayed whilst waiting for the first two submissions to finish. Choosing the timeout is thus important, as discussed below.
How to choose the timeout?
Choosing the right timeout depends a lot on your expected traffic. If you are expected requests to come in one-by-one with reasonable gaps in between them, it might make sense to choose a low time, like < 1ms.
However if you expect there to be a lot of traffic, then it makes sense to optimize the throughput with a timeout. It makes sense to increase the timeout if you are consistently not processing with the max batch size you specified.
The batch sized used is logged when run in debug mode with -e TAKEOFF_LOG_LEVEL=DEBUG. You can see it by searching for a message like the following:
Processing with batch size 32 from a queue of size 50
If the batch size is significantly lower than the max batch size, you may want to consider increasing the timeout to benefit from the throughput increase.
How to choose the max batch size?
Increasing the batch size increases the memory required to run the model. For a given model, given hardware, and given prompt length, there will be a maximum batch size that can be run without erroring. This is difficult to predict ahead of time, so it makes sense to test and decrease the batch size if you get out-of-memory errors.
Configuring batching in Takeoff
See here