Using the GUI
Takeoff is packaged with some easy-to-use demo interfaces to help you quickly test out a model. There are two interfaces available:
Chat -- similar to that of OpenAI chat (ChatGPT) and Playground -- similar to that of OpenAI completions.
Chat Interface
To use the chat interface navigate to localhost:3000/demos/chat/ in your browser with the Takeoff server running
The chat interface is designed to mimic the ChatGPT interface. Your messages and the model's responses are sent back and forth via the API each time you send a message, meaning TitanBot has a memory of the conversation up to that point.
The settings panel on the right-hand side allows for generation to be customised. For more information on these parameters, see Choosing parameters.
Playground Interface
To use the chat interface navigate to localhost:3000/demos/chat/ in your browser with the Takeoff server running. See here.
The playground interface is modelled on the completion mode of the OpenAI playground, making it a good way to quickly test non-chat behaviour of models such as summarization. Any text you add to the box is sent to the API, and the model tries to complete it.
Shift + Enter: New Line
Enter: Submit / Ask the model for a completion.
Model Memory calculator
In order to avoid Out of Memory errors, we have created a memory calculator that will estimate the amount of memory a model will use. You can also specify your hardware's specifications to determine if a specific model can be run on your configuration, based on the calculations discussed in more detail here.
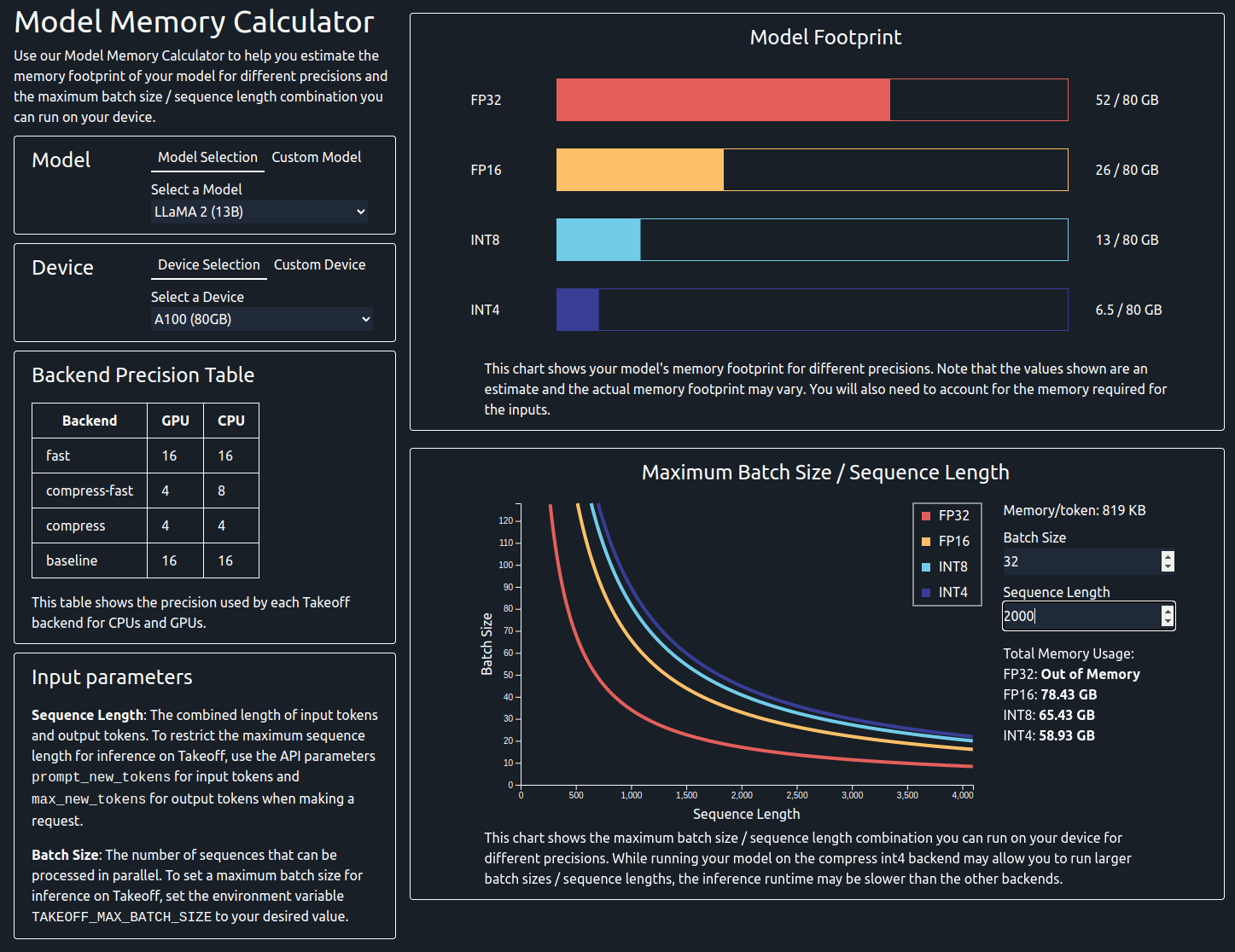
You will need to enter the following information:
- Model: You can either select a model from the drop-down menu or enter the number of parameters manually.
- Device: You can either select a device from the drop-down menu or enter the memory manually.
- Batch Size (optional): This is the batch size that you want to use for inference.
- Sequence Length (optional): This is the max sequence length that you want to use for inference.
Model Footprint Chart
On provision of the required parameters you will be presented with the model's footprint chart. This shows the static memory usage of the model in different precisions, such as FP32, FP16, INT8 and INT4.
If a device has been provided, the chart will update to show the memory usage of the model on that device, allowing you to see if a model will fit on the device. Bear in mind that the memory usage of the model during inference time will be higher than this value, as it does not take into account the dynamic memory usage of the model.
Maximum Batch Size / Sequence Length Chart
If you have selected a custom model, you will also need to input the hidden size and number of layers in order to see this chart. The details for these values can usually be found in the config.json file of the model on the HuggingFace hub.
This line shows the maximum batch size and sequence length combinations that can be used with the model on the selected device across different precisions. You can also specify a batch size or sequence length to see the maximum sequence length or batch size that can be used with the model on the selected device. If both batch size and sequence length are specified, the chart will show the total memory usage of the model on the selected device.