Document Ingestion
Overview
We have a variety of methods to best process your documents and store them in a light, easily searchable system.
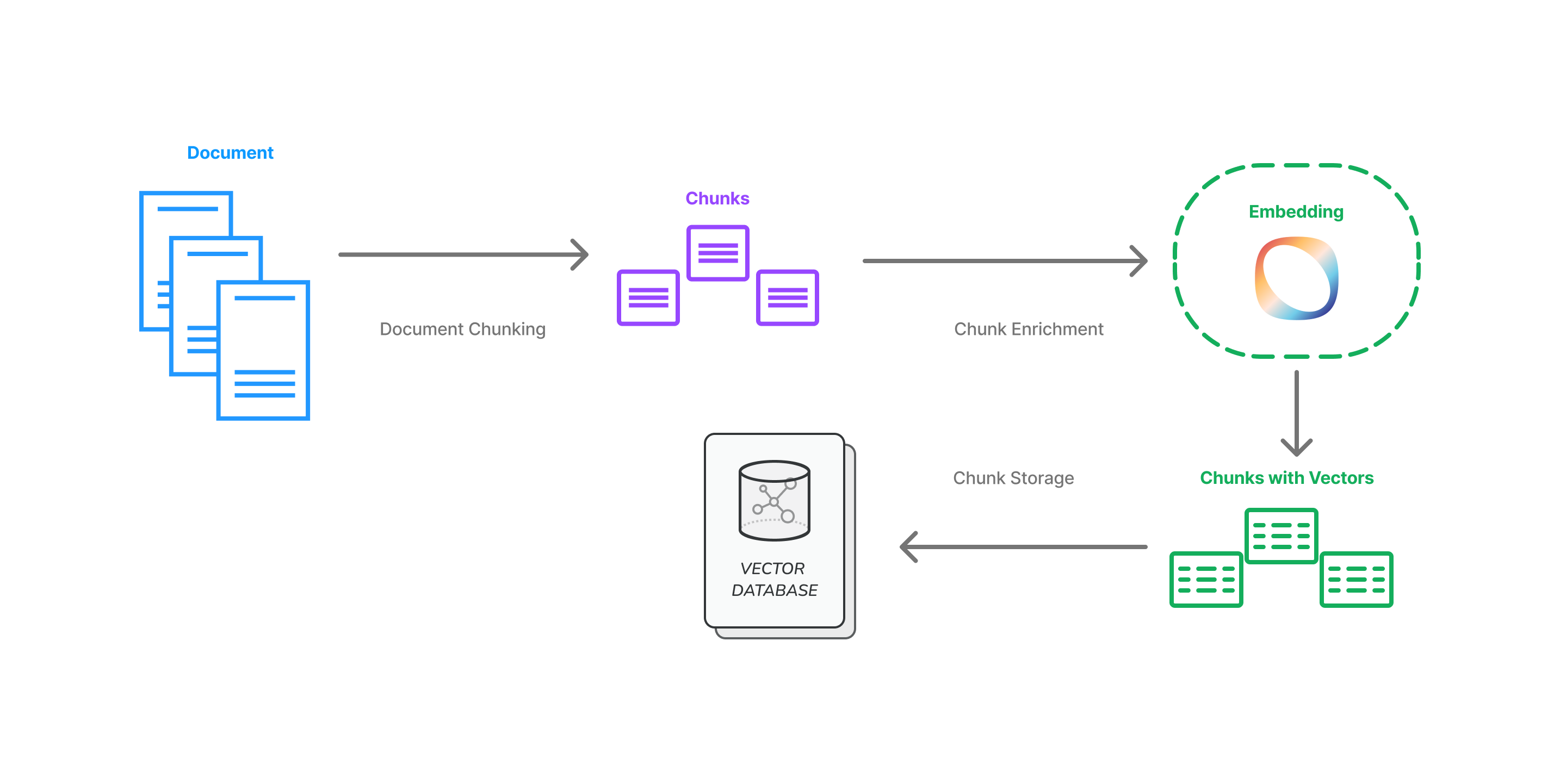
Here is the basic map of the simple path documents can take through our system:
Uploading Documents
The document processing pipeline can be accessed via the DPP API using POST /api/v1/documents.
Document Chunking
Documents often contain much noise in addition to the information necessary to answer an individual user's question. Giving an entire document to a generative model is typically suboptimal and will be less likely to yield knowledgeable answers. Even if the requisite knowledge required is distributed across multiple pages there is still a large proportion of the corpus that is irrelevant. Document chunking instead retrieved the relevant parts of the document to the user query.
We separate the document into its constituent elements and then, based on their relation to other elements, construct meaningful chunks. The size of the chunks can be customised based on your requirements. Larger chunks contain more information but can lead to fewer chunks being supplied in context. On the other hand, smaller chunks can lead to more relevant chunks being composed into the generative model's context which is better if the questions you are asking are more broad and encompass a larger portion of the document.
Chunk Enrichment
Embedding
Once the document has been divided into meaningful chunks, we want to enrich the text in the chunks by vectorising them. Embedding provides a meaningful representation of the text through a vector which can be used later to search for the chunk among other extracts of text, without relying on basic word matching.
Table Detection
For documents that are more complicated to ingest, especially documents with tables, we have a more complex process:
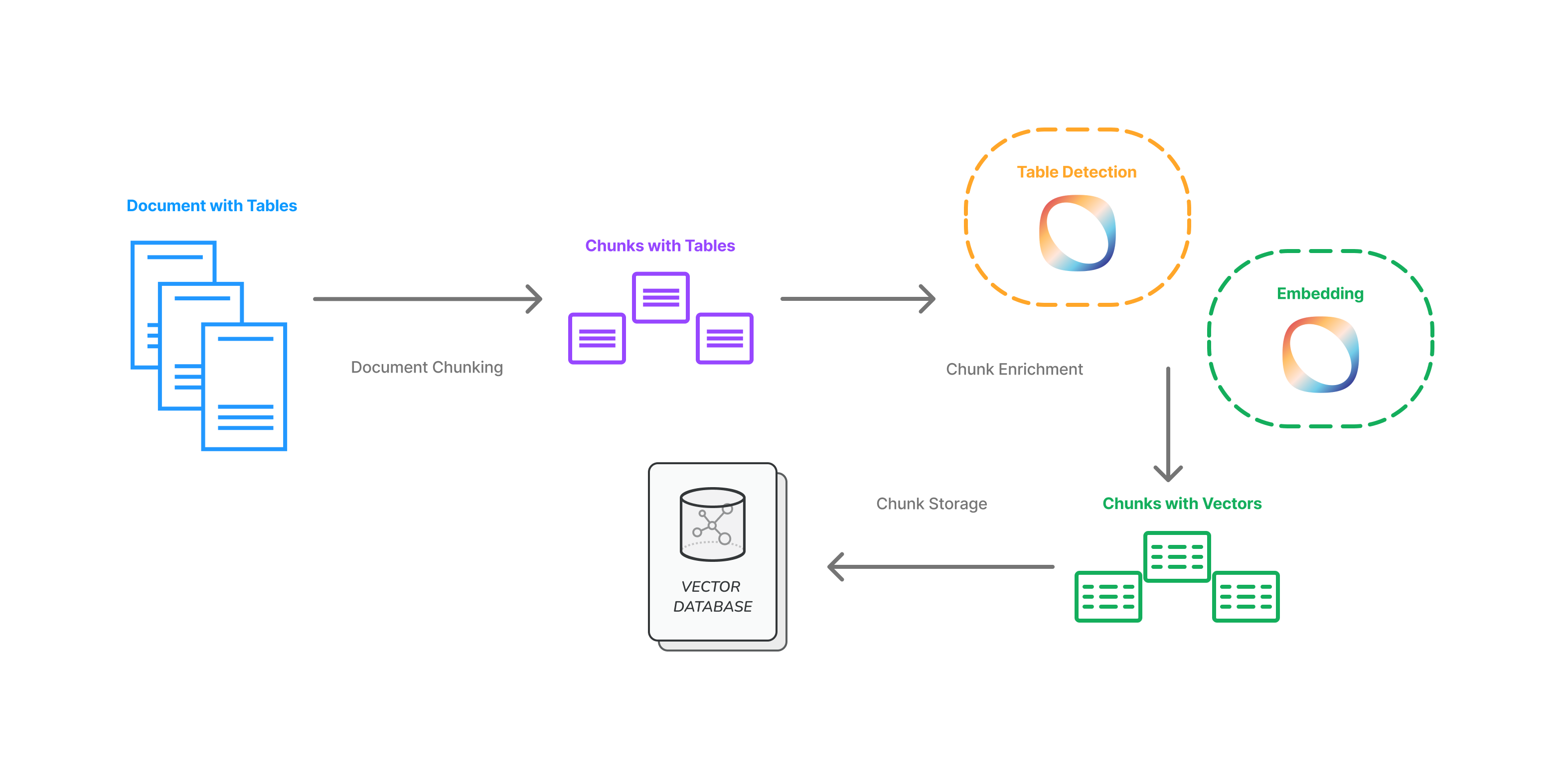
Tables are a more nuanced form of data that can be difficult to extract. Elements which are detected as tables undergo conversion to a structured machine-readable format. Tables can't then be immediately embedded as text, as to do so would sacrifice most of the structural information that embeds meaning. We use an extraction process to summarise the meaning of the table and then submit that alongside to the table text to the vectorisation process. This allows us to capture the meaning and content of tables, so the generative model can accurately use them in its answers.
Chunk Storage
We use a vector database in which we store the chunk text alongside the vectors computed in the previous step. This allows for the fast searching of chunks based on the vector similarity alongside text matches. This is agnostic to the vector database used - we support Weaviate, Postgres and MongoDB out of the box and will work with you to integrate any further systems you may use.