Readers & Consumer Groups
Takeoff's Management Server lets you simultaneously support different models, with different configurations, serving different users. The API orchestrates Readers and Consumer Groups, described in further detail here.
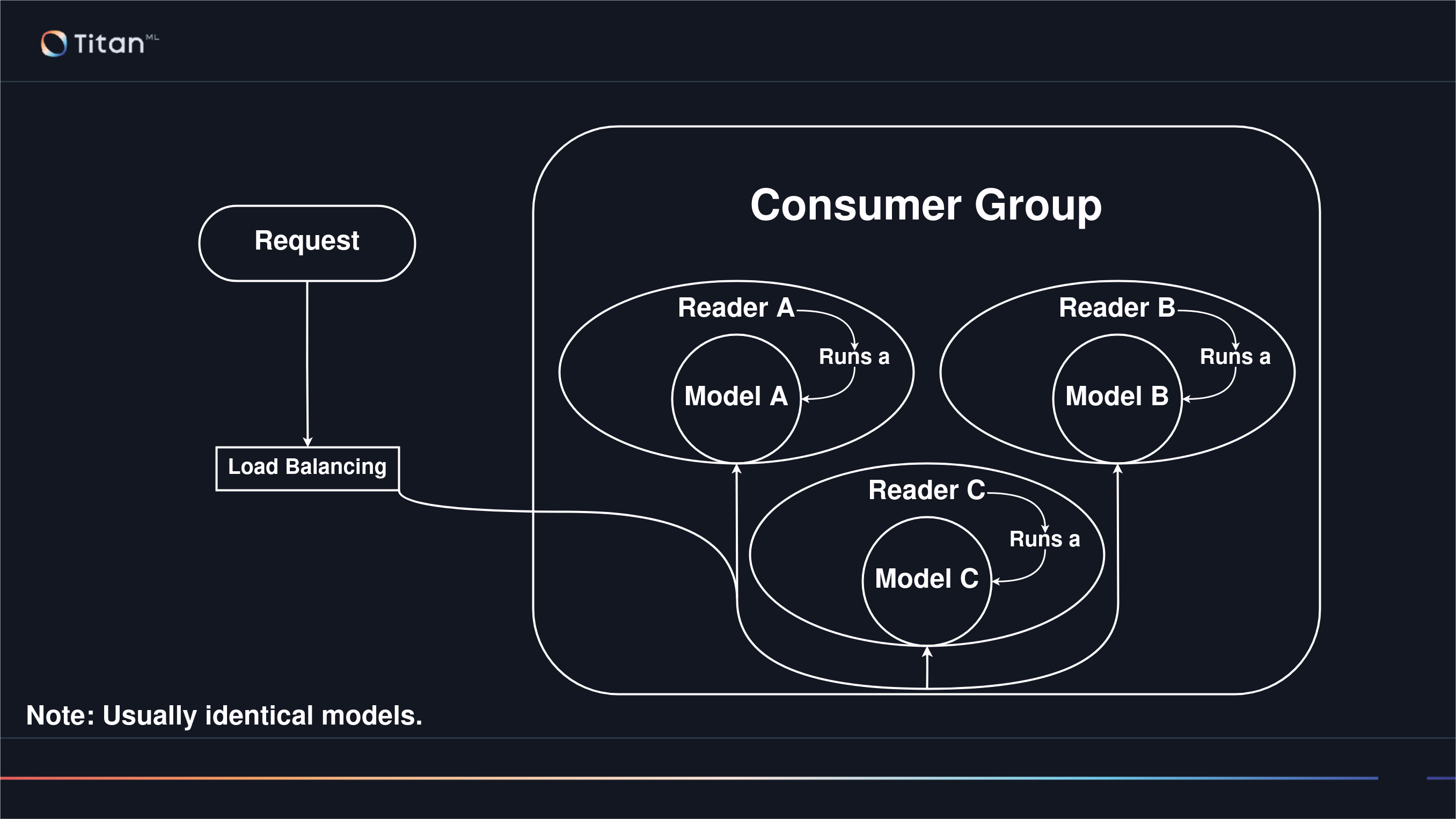
Consumer Groups
Multiple readers can be organised into a single Consumer Group which only process requests in their group. Having multiple consumer groups thus allows for fine-grained control of which group of readers should process each of your requests.
When you first spin up Takeoff with a model, a reader is automatically created in the default primary consumer group. Which consumer group requests are sent to are determined by the consumer_group parameter in inference request bodies, defaulting to the primary consumer group.
Consumer groups and readers can be configured either at launch time, or dynamically.
Readers vs Models
The Takeoff inference server API has functionality to serve requests to multiple models simultaneously.
We use the terminology reader to refer to a model that is loaded into Takeoff with a particular configuration. This configuration includes the model name and the device (cpu or cuda).
A model is considered as the description of the model, whereas a reader is a served instance of a model, applying the model to an input by reading an input off of a queue of required inferences.