Quickstart
Installing Docker
Takeoff runs using Docker, which you'll need to install first.
To run models on GPU, you'll also need to have installed the NVIDIA Container Toolkit and have it configured to work with Docker. A guide on how to do this can be found here.
Accessing Takeoff
On first run, you'll need to ensure you have access to our Docker registry (run docker login -u takeoffusers and enter the Docker authentication token you were provided).
You'll then need to provide a license key the first time you launch the server (use docker run with -e LICENSE_KEY=[your_license_key]).
See Accessing Takeoff for more info.
Step 1: Setting Up Takeoff
To get up and running with Takeoff, you can use the Mistral generative model, such as TitanML/Mistral-7B-Instruct-v0.3-AWQ-4bit. Alternatively, feel free to explore and choose from a wide range of models available on Hugging Face here or from other creators and organizations.
Help! Mistral-7B is too big...
According to the model memory calculator, Mistral-7B non-quantized requires at least 14GB of memory to run in full precision (e.g., 14GB of VRAM).
You can use any supported model for this tutorial, such as TitanML/Mistral-7B-Instruct-v0.2-AWQ-4bit, which needs only 3.5GB of memory thanks to its use of int4 quantization. See here for more on determining which models you can launch with your available hardware.
We can now Takeoff with the following command:
docker run --gpus all
-e TAKEOFF_MODEL_NAME=TitanML/Mistral-7B-Instruct-v0.3-AWQ-4bit
-e TAKEOFF_DEVICE=cuda
-e LICENSE_KEY=<your_license_key>
-e TAKEOFF_MAX_SEQUENCE_LENGTH=1024
-p 3000:3000
-p 3001:3001
tytn/takeoff-pro:0.18.0-gpu
Terminal output should display:

Demo at http://localhost:3000/
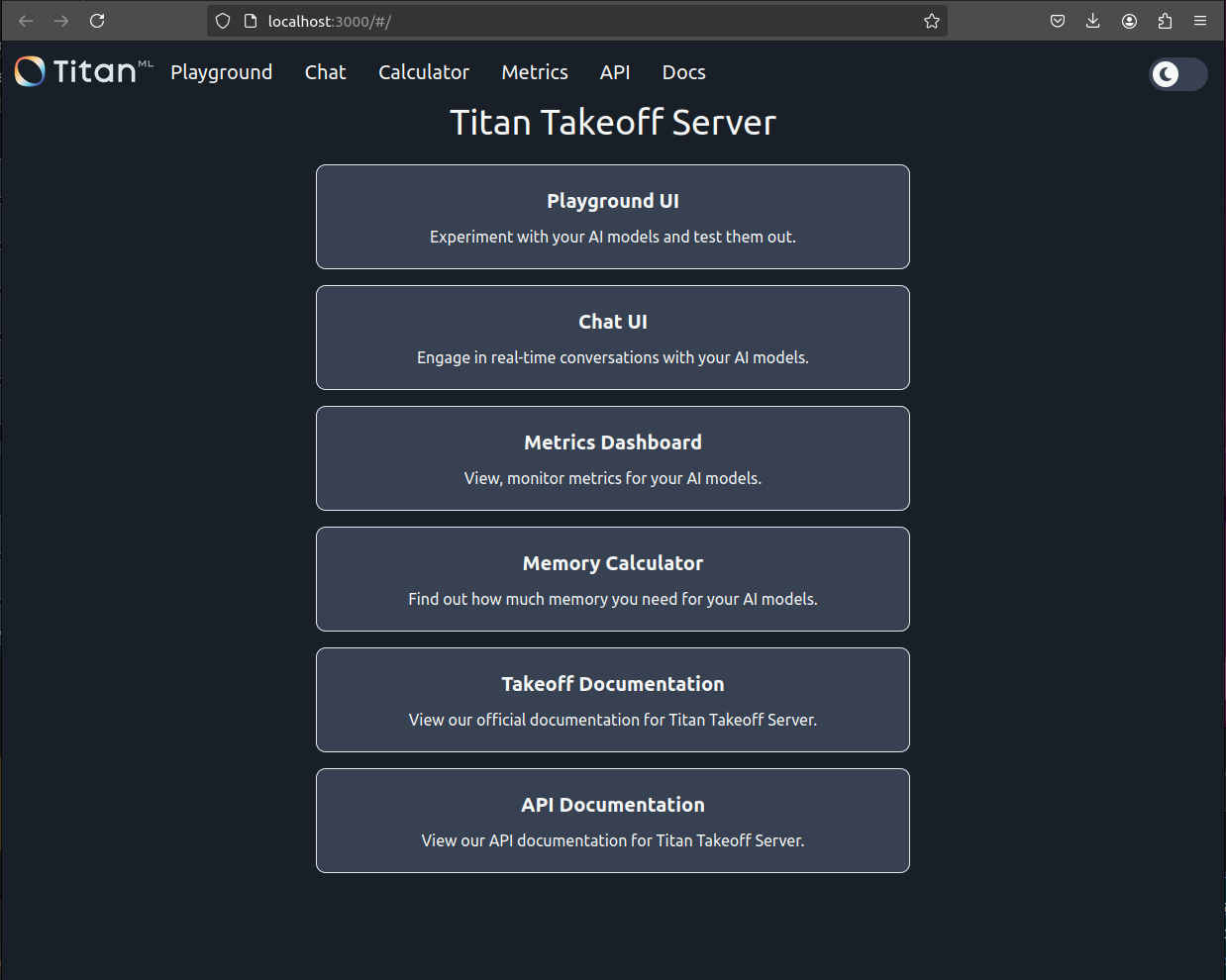
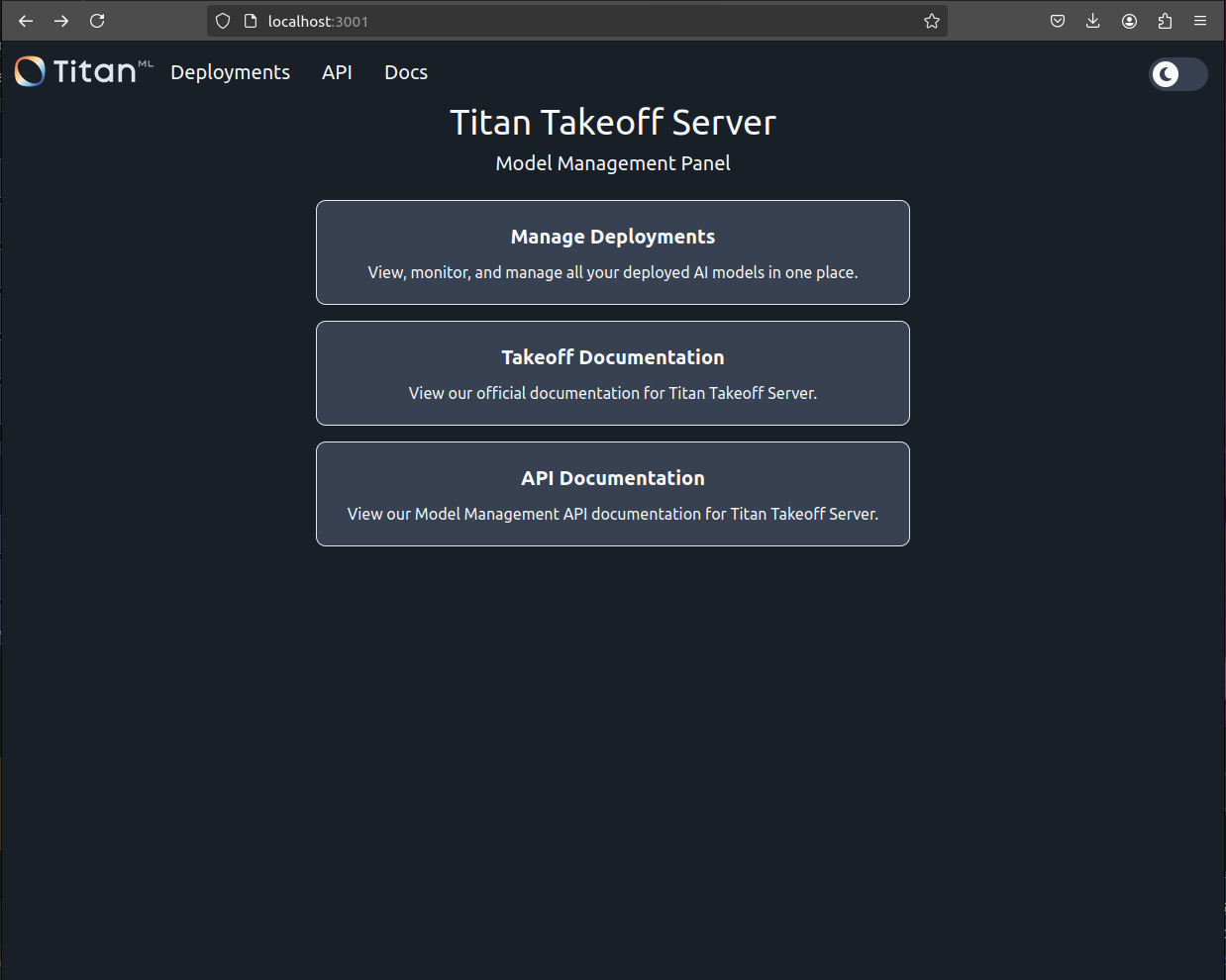
Model Management Panel at http://localhost:3001/
Variables used:
TAKEOFF_MODEL_NAME: Model to useTAKEOFF_DEVICE: Device to run it on (cuda for GPU, cpu for CPU)LICENSE_KEY: License key to authenticate your copy of TakeoffTAKEOFF_MAX_SEQUENCE_LENGTH: The maximum length of an input and generation in tokens
Additionally, this requires port 3000 and port 3001 to be forwarded to interact with the container.
Querying Your Model
You can check that your model is running by navigating to the frontend. This will be hosted at localhost:3000 if you didn't specify a port in the docker run command.
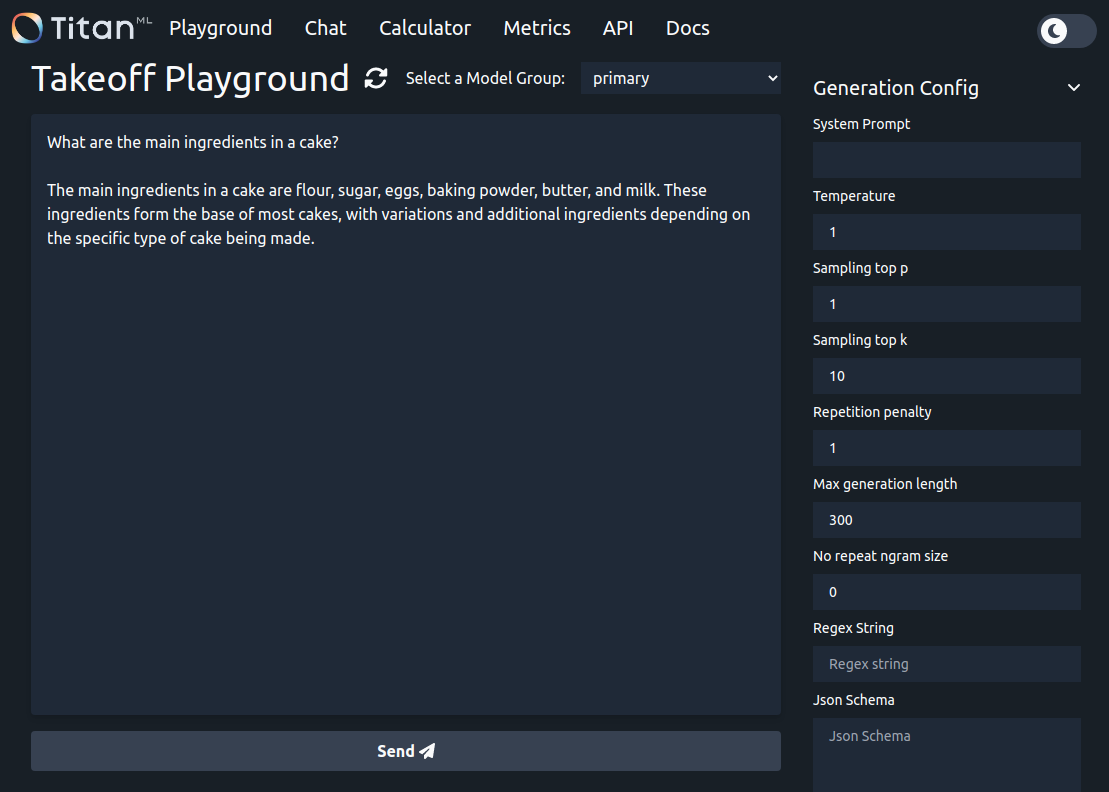
Enter a prompt and press "send", then watch as the response is streamed back. As the model is running with random token sampling, the output you see will likely be different (but still reasonable).
Querying via cURL
curl <http://localhost:3000/generate> \\
-X POST \\
-N \\
-H "Content-Type: application/json" \\
-d '{"text": "What are the main ingredients in a cake?"}'
Response:
{"text":"The main ingredients in a cake are flour, sugar, eggs, butter or oil, baking powder, and vanilla extract. These ingredients form the basic structure of a cake, with variations depending on the specific type of cake being made. Other common ingredients include cocoa powder for chocolate cakes, milk for moist cakes, and different flavorings such as lemon zest or almond extract."}
Tips for Success
-
Use Ctrl+Shift+V and select text precisely when pasting credentials to avoid unwanted characters or paste brackets.
-
If you encounter the error
docker: invalid reference format, try rebooting your system. -
If multiple containers are running, ensure you're using the correct Docker container. You can view all running containers by pressing Tab on your keyboard. To stop an unused container, use:
docker kill 'unused container'Note: Please consult your team before killing a container.
You're all set! You should now be able to run this in your browser.