Understanding Chargeback in the Context of Self-Hosted Systems

Introduction
When technology infrastructure—such as GPUs and servers—is owned and managed by a central IT team, the need to allocate costs back to the business units that benefit from these resources becomes a critical consideration. This is particularly relevant in the context of self-hosting AI models, where the initial investment in high-performance GPUs, servers, and supporting infrastructure can be substantial. Without a clear chargeback mechanism, it becomes difficult to ensure accountability, optimize resource usage, and justify the ROI of such investments.
So, how do you design a chargeback system that is scalable, transparent, and easy to manage as your organization grows from supporting a handful of users to thousands of downstream business units? In this guide, we’ll explore how to architect and implement a chargeback system that not only integrates seamlessly with your existing AI infrastructure but also provides clear visibility into costs and benefits. By doing so, you can ensure that the value of your AI investments is both measurable and aligned with business goals.
Why Chargeback Systems Matter?
We believe that to run AI inference at scale, it is essential to centralize your inference operations as part of building out your InferenceOps function (you can read more about InferenceOps in our blog series here). Centralizing inference ensures that GPU resources are shared efficiently across multiple departments in your organization. However, with shared resources comes the challenge of cost allocation—how do you ensure that each department pays for the portion of resources they consume? This is where a robust chargeback system becomes critical.
To illustrate this concept, let’s use a simple example of a pizza pie. Imagine you’re hosting a lunch for a group of people. It’s often more economical to buy an entire pizza pie to feed the group rather than purchasing individual slices for everyone. For instance, a whole pizza might cost $5 and come with 8 slices, while buying individual slices at $1 each would cost $8 for the same amount of pizza. Clearly, buying the pie is the smarter choice, even if you don’t eat all 8 slices.
In this analogy, the central IT team is the one buying the pizza pie (or, in this case, the GPUs and infrastructure). They make the upfront investment because it’s more cost-effective to purchase and manage these resources centrally rather than having each department buy their own GPUs. However, the challenge lies in tracking how much each department “eats”—or, in other words, how much GPU usage each team consumes. Without a proper system in place, it’s difficult to allocate costs fairly or ensure accountability.
This is where a chargeback system comes into play. It allows central IT to track resource consumption at a granular level and bill each department based on their actual usage. Just like dividing the cost of the pizza based on how many slices each person eats, a chargeback system ensures that departments only pay for the GPU resources they consume. This not only promotes fairness but also encourages teams to use resources efficiently, avoiding waste and optimizing the overall budget.
Tracking Individuals Requests
To accurately measure how much each user consumes, the Doubleword Control Layer leverages user-level API tokens to track usage. Each individual is assigned a unique API token, which they use when developing their API applications. This makes it straightforward to identify, over a given time period, which users are consuming the largest share of resources—or, in our analogy, eating the biggest portion of the pizza pie.
All user requests and responses that pass through the Doubleword Control layer are logged in an internal, queryable database. This database provides detailed insights, such as the number of requests a user has sent, the specific models they interacted with, and the input and output token counts for each request. By querying this data, we can generate summary tables, like the one shown in the image below, to provide a clear breakdown of resource consumption by user. This level of granularity ensures transparency and accountability, making it easy to allocate costs fairly and optimize resource usage.
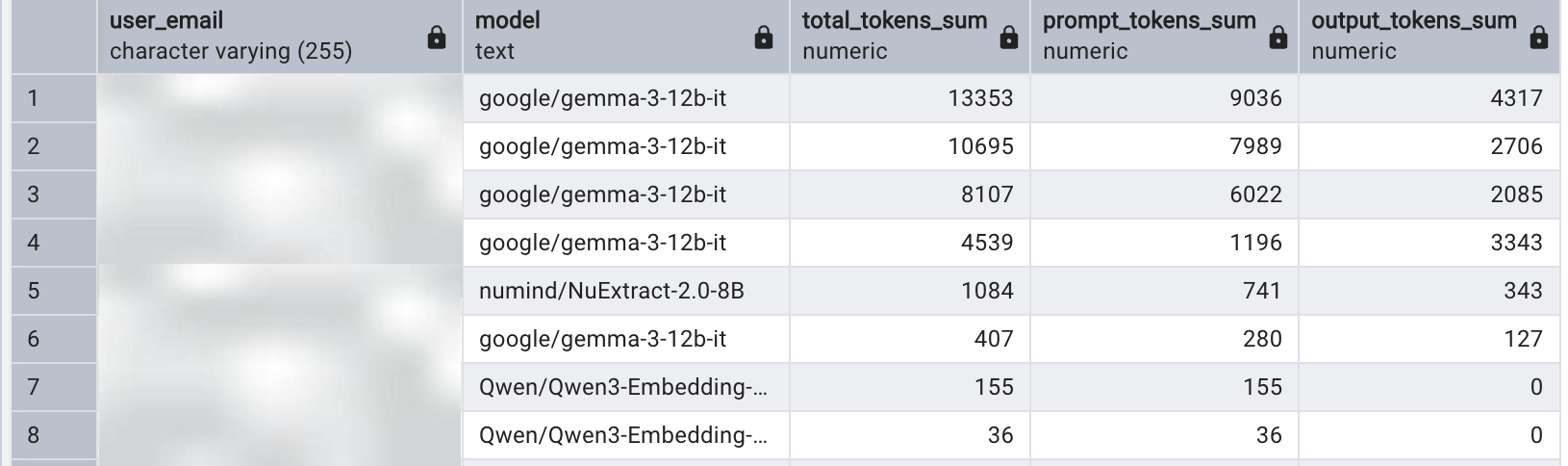
For example we can run the following query to get the summary table:
SELECT
user_email,
model,
SUM(total_tokens) as total_tokens_sum,
SUM(prompt_tokens) as prompt_tokens_sum,
SUM(completion_tokens) as output_tokens_sum
FROM public.http_analytics
GROUP BY
model,
user_email
ORDER BY
total_tokens_sum DESC;
Associating Tokens to Cost
In a self-hosted system, there isn’t a predefined price per token like you would get with closed-source LLM providers. This is because the GPU cost is a fixed expense, regardless of how much it is utilized. However, since multiple downstream users or teams share this fixed cost, a system can be implemented to allocate costs based on each user’s capacity of usage.
There are a few ways to calculate this chargeback based on token usage:
- Proxy Price Per Token: You can calculate a proxy price per token by dividing the total GPU cost by the total capacity of tokens the GPU can process. This gives you a baseline cost per token, which can then be multiplied by the number of tokens each user processes. For example, the equation might look like: total_cost / total_opportunity_of_tokens. This method ensures that users are charged proportionally to their actual usage of the GPU resources.
- Total Tokens Per User: Another approach is to calculate the total tokens processed by each user as a percentage of the total tokens processed by the system. For example: user_tokens / total_tokens_processed. While this method is simpler, it doesn’t account for wasted GPU capacity (e.g., idle time or underutilized resources), which could lead to inefficiencies in cost allocation.
The price-per-token model is a great starting point for organizations with high GPU utilization and dedicated inference workloads. However, for organizations just getting started with InferenceOps or those sharing GPUs between training and inference, alternative methods like flat fees, time-based allocation, or hybrid models may be more practical. These approaches ensure cost recovery, fairness, and predictability while accommodating the unique challenges of low usage or mixed workloads. A full summary of methods can be found below:
| Method | Best Used When... |
|---|---|
| Proxy Price Per Token | High GPU usage scenarios, where the GPU is operating near full capacity, ensuring the fixed cost is spread across many tokens. |
| Total Tokens Per User | Moderate to high usage scenarios, where the focus is on simplicity and transparency, and idle GPU time is minimal. |
| Time-Based Allocation | Low usage scenarios, where GPU utilization is sporadic, and charging for time ensures idle costs are covered. |
| Hybrid Model | Dynamic workloads or large organizations, where a combination of factors (e.g., time, tokens, and compute) provides the most balanced cost allocation. |
| Tiered Pricing | Organizations with diverse usage levels, where predictable costs are important, and incentives for efficient usage are needed. |
| Flat Fee with Overages | Low to moderate usage scenarios, where simplicity and predictable costs are prioritized over precise cost allocation. |
Conclusion
Implementing a chargeback system for self-hosted AI infrastructure enables accountability, efficiency, and cost optimization. By centralizing inference operations and leveraging robust tracking mechanisms, organizations can ensure that GPU resources are shared fairly and transparently across teams. Whether you’re just getting started with InferenceOps or managing a mature AI infrastructure, the right chargeback model can help align IT costs with business goals, encourage efficient resource usage, and provide clear visibility into ROI.
Ultimately, a chargeback system ensures that every "slice of the pie" is accounted for. By making costs transparent and tied directly to usage, you can foster a culture of accountability and efficiency while ensuring your AI investments remain sustainable and aligned with business priorities.
As AI adoption continues to grow, chargeback systems will play an increasingly critical role in managing the costs of high-performance infrastructure. By implementing a scalable and transparent chargeback system, organizations can not only recover costs but also drive innovation and operational excellence.