Running multiple models at once
This guide will cover how to run more than one model at once using Takeoff. We'll cover:
- Using consumer groups to deploy models with different roles.
- Launching a single reader using a manifest file.
- Launching multiple models at once using a manifest file.
- Changing which models are running after launch time.
A quick introduction to Consumer Groups
Deploying multiple models with Takeoff requires the use of consumer groups, which are essentially groups of readers. Every reader is part of a consumer group, and there can be multiple readers per consumer group.
Consumer groups distinguish model functionality. For example, you could have two consumer groups each with one reader in them, with one consumer group having a very large language model and the other having a smaller language model in it. You could then have an application route easier tasks to the smaller model, and harder ones to the larger model. You would use the consumer group to specify which readers should receive the request. Similarly, you could have one consumer group have an embedding model and another a generative model, with a RAG application sending requests to each of them at the relevant points.
There are also cases where you'd want multiple, homogeneous readers in a single consumer group, but these are only useful in distributed contexts which we won't cover here.
If you want to configure multiple readers at runtime, you need to use a manifest file.
Deploying one model with a manifest file
To help illustrate how manifest files work we'll revisit our example from the guide on launching a single model in a docker container, but instead launch it using a manifest file. The first step is the same - you should ensure you have access to the Takeoff Docker repository and have Docker and the NVIDIA Runtime Toolkit installed.
Using docker run and environment variables, we had:
docker run \
-e TAKEOFF_MODEL_NAME=meta-llama/Llama-3.2-1B \
-e TAKEOFF_DEVICE=cuda \
-e LICENSE_KEY=[your_license_key] \
-e TAKEOFF_ACCESS_TOKEN=123
-p 3000:3000 \
-v ~/.takeoff_cache:/code/models \
-it \
--gpus all \
tytn/takeoff-pro:0.21.2-gpu
We can extract our reader configuration from here and put it into a manifest file:
takeoff:
server_config:
access_token
readers_config:
reader1:
model_name: "meta-llama/Llama-3.2-1B"
device: "cuda"
consumer_group: "generate"
Notice how the reader we implicitly setup using environment variables now has to be explicitly defined and given a reader ID - I chose "reader1". We also now need to assign the reader a consumer_group - I went for "generate" as its a generative model. When we add an embedding model later we'll put it in an "embed" consumer group (these names are arbitrary though.) reader is configured to use the same model we previously specified by -e argument to docker run.
We can now launch Takeoff using this config file by mounting it to the relevant location with -v ./my_config.yaml:/code/config.yaml:
docker run --gpus all \
-p 3000:3000 \
-v ~/.takeoff_cache:/code/models \
-v ./my_config.yaml:/code/config.yaml \
-e LICENSE_KEY=[your_license_key] \
tytn/takeoff-pro:0.21.2-gpu
Note how we still have to pass in LICENSE_KEY via -e argument to docker run. Variables which do not start with TAKEOFF_ are intended to be kept out of manifest files, and so can only be specified with -e to docker run. Also note that the location of the config file inside the container is fixed - if the manifest is not mounted at this location it will be ignored.
This should spawn a reader in the same way as not using a manifest, with only two minor differences from the result obtained from the manifest-less example here. Here, the readerID and consumer group are explicitly specified, whereas in the manifest-less case they are autogenerated and defaulted to "primary" respectively.
ASIDE: Modifying the server config.
In this guide we're focusing on configuring Takeoff's readers, but Takeoff also has a central server to communicate with them. The server has its own parameters that you can see here. These are mostly used for advanced cases so we won't go into more detail here, but they can be specified through a mix of the manifest and environment variables, with anything specified via -e in the docker run command overriding that specified in the manifest file. LICENSE_KEY, OFFLINE_MODE and NO_COLOR can only be specified as environment variables using -e to docker run (as can the Standard Docker options like --gpus and --shm-size.
Deploying multiple models with a manifest file
Now that we've covered how to use manifests, adding more models is straightforward as illustrated by this example which launches two consumer groups, one for embedding and one for generation, with a single reader in each.
takeoff:
server_config:
readers_config:
reader1:
model_name: "intfloat/e5-small-v2"
device: "cpu"
consumer_group: "embed"
reader2:
model_name: "meta-llama/Llama-2-7b-chat-hf"
device: "cuda"
consumer_group: "generate"
As we did with a single model, we can launch takeoff as follows:
docker run --gpus all \
-p 3000:3000 \
-p 3001:3001 \
-v ~/.takeoff_cache:/code/models \
-v ./my_config.yaml:/code/config.yaml \
tytn/takeoff-pro:0.21.2-gpu
You'll notice we've also forwarded port 3001 here. This is the Takeoff Management API which is not required for using multiple models, but is useful for us to check that they've been launched properly.
With 3001 forwarded we can now visit the management GUI at http://localhost:3001.
This lets us see the status of our multiple readers:
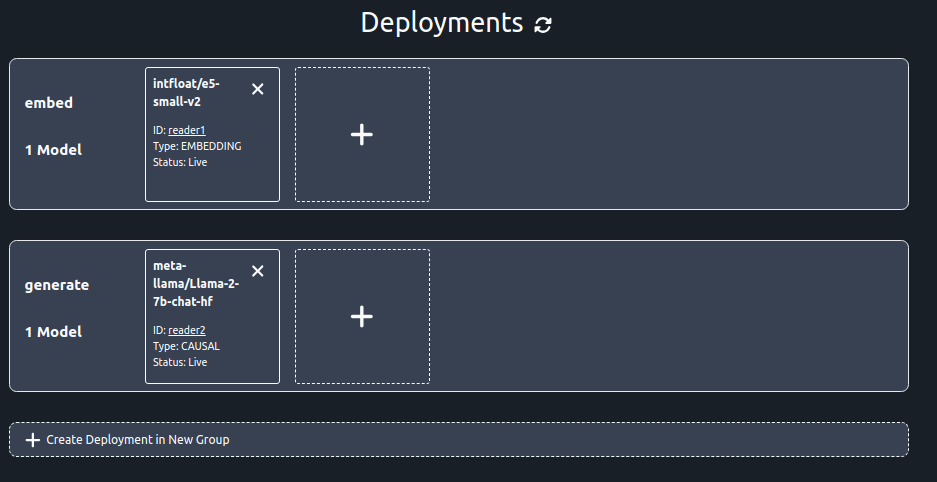
You should be able to see your two consumer groups, and the model in each of them. The management GUI also lets you change which models are running after you've launched with the initial manifest.
Changing which models are running after launch time.
You can change which models are running either by using the GUI from our now exposed Management frontend or using the Management API itself.
For example, using the GUI you can add a model to an existing consumer group or create a new consumer group entirely:
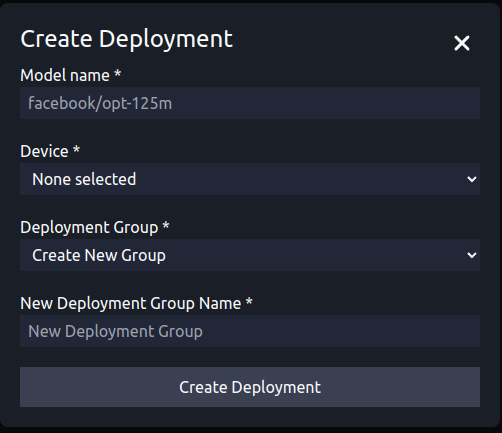
It's worth noting, however, that the management API is required to access the full range of configuration options for the Reader. We'll now add a reader using the API, but first lets check which readers are currently running by sending a GET request to localhost:3001/reader_groups.
You can generate the requests we're going to use here and see the entire API specification here. You can send a request from the API docs themselves or generate a curl command such as this:
curl -L 'http://localhost:3001/reader_groups' \
-H 'Accept: application/json'
We'll then be expecting a response like this:
{
"embed": [
{
"reader_id": "reader1",
"device": "cpu",
"model_name": "intfloat/e5-small-v2",
"model_type": "EMBEDDING",
"pids": [
139
],
"ready": true
}
],
"reader1": [
{
"reader_id": "reader1",
"device": "cpu",
"model_name": "intfloat/e5-small-v2",
"model_type": "EMBEDDING",
"pids": [
139
],
"ready": true
}
],
"reader2": [
{
"reader_id": "reader2",
"device": "cuda",
"model_name": "meta-llama/Llama-2-7b-chat-hf",
"model_type": "CAUSAL",
"pids": [
141
],
"ready": true
}
],
"generate": [
{
"reader_id": "reader2",
"device": "cuda",
"model_name": "meta-llama/Llama-2-7b-chat-hf",
"model_type": "CAUSAL",
"pids": [
141
],
"ready": true
}
]
}
Note that this endpoint returns consumer groups, with the readers in each one listed. Each reader actually spawns an additional consumer group with the same name as its id, which is why you'll see each reader appearing twice here.
We can then add a reader with a POST request to localhost:3001/reader with a ReaderConfig as the body.
We'll launch a reranker model to go with our embedding and generative models, creating a new consumer group classify for it using this body:
{
"consumer_group": "classify",
"device": "cpu",
"model_name": "BAAI/bge-reranker-base"
}
We can then issue the request to get this response. Note the reader ID that's returned in the response, we'll need it to delete the reader in a second! Ours is 476f28b2-069f-4b5b-9471-b29ed089b31b but they're randomly generated so yours will differ.
[
"476f28b2-069f-4b5b-9471-b29ed089b31b",
{
"model_name": "BAAI/bge-reranker-base",
"device": "cpu",
"consumer_group": "classify"
}
]
We can run a GET request to check for the specific reader ID we assigned:
{
"model_name": "BAAI/bge-reranker-base",
"model_type": "SEQUENCE_CLASSIFICATION",
"pids": [
448
],
"consumer_groups": [
"generclassifyate",
"476f28b2-069f-4b5b-9471-b29ed089b31b"
],
"consumer_name": "476f28b2-069f-4b5b-9471-b29ed089b31b",
"device": "cpu"
}
You can see that the consumer group classify was created when we added a new reader with the classify consumer group. Let's now try to delete the reader using:
// This one only returns a 204 status code if it succeeds..
This will remove the reader from the consumer group and kill it. We can then check it's been deleted:
{
"reader1": [
{
"reader_id": "reader1",
"device": "cpu",
"model_name": "intfloat/e5-small-v2",
"model_type": "EMBEDDING",
"pids": [
139
],
"ready": true
}
],
"embed": [
{
"reader_id": "reader1",
"device": "cpu",
"model_name": "intfloat/e5-small-v2",
"model_type": "EMBEDDING",
"pids": [
139
],
"ready": true
}
],
"generate": [
{
"reader_id": "reader2",
"device": "cuda",
"model_name": "meta-llama/Llama-2-7b-chat-hf",
"model_type": "CAUSAL",
"pids": [
141
],
"ready": true
}
],
"reader2": [
{
"reader_id": "reader2",
"device": "cuda",
"model_name": "meta-llama/Llama-2-7b-chat-hf",
"model_type": "CAUSAL",
"pids": [
141
],
"ready": true
}
]
}
As the reader was the last reader in the consumer group, the consumer group has also been deleted.
As the management API can be used to remove or manipulate readers, you should consider restricting access to its ports to only the administrator.